BigData - MongoDB
- BigData - MongoDB
ref:
- https://medium.com/starbugs/optimize-index-with-mongodb-explain-2337ef50a601
- https://developer.aliyun.com/article/617229
- https://juejin.cn/post/7102250055666663460#heading-7
- https://edwardesire.com/posts/a-mountain-to-climb-mongodb-index-query/
- https://blog.csdn.net/Comedly/article/details/84496916
BigData - MongoDB
Overview
- 由C++语言编写
- 一个基于分布式文件存储的开源数据库系统。
- 在高负载的情况下,添加更多的节点,可以保证服务器性能。
- 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
- 将数据存储为一个文档,数据结构由键值(key=>value)对组成。
MongoDB文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 可以在MongoDB记录中设置任何属性的索引 (如:FirstName=”Sameer”,Address=”8 Gandhi Road”)来实现更快的排序。
- 可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力), 它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。
- 查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。
- Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单。
Compponent

mongodb中基本的概念是文档. 集合. 数据库
| SQL | MongoDB | 解释说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table | joins | 表连接,MongoDB不支持 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
数据库 Database
一个mongodb中可以建立多个数据库。
MongoDB的默认数据库为”db”,该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ ./mongo
MongoDB shell version: 3.0.6
connecting to: test
# "show dbs" 命令可以显示所有数据的列表。
show dbs
local 0.078GB
test 0.078GB
# 执行 "db" 命令可以显示当前数据库对象或集合。
db
test
# 运行"use"命令,可以连接到一个指定的数据库。
use local
switched to db local
db
local
- 数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
- 不能是空字符串
- 不得含有
' '(空格). .. $. /. \和\0 (空字符) - 应全部小写。
- 最多64字节。
- 有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是”root”数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
文档 Document
文档是一组键值(key-value)对(即 BSON)。
MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
1
2
// 一个简单的文档例子如下:
{"site":"www.runoob.com", "name":"Grace"}
注意:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型, 甚至可以是整个嵌入的文档
- MongoDB区分类型和大小写。
- MongoDB的文档
不能有重复的键。 - 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有
\0 (空字符)。这个字符用来表示键的结尾。 .和$有特别的意义,只有在特定环境下才能使用。- 以下划线
"_"开头的键是保留的(不是严格要求的)。
集合 collections
集合就是 MongoDB 文档组,类似于 RDBMS, 关系数据库管理系统, Relational Database Management System 中的表格。集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
1
2
3
4
// 比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
{"site":"www.runoob.com","name":"Grace","num":5}
- 当第一个文档插入时,集合就会被创建。
合法的集合名
- 集合名不能是
空字符串""。 - 集合名不能含有
\0字符(空字符),这个字符表示集合名的结尾。 - 集合名不能以
"system."开头,这是为系统集合保留的前缀。 - 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现
$。
1
2
# 如下实例:
db.col.findOne()
capped collections
固定大小的collection。
它有很高的性能以及队列过期的特性(过期按照插入的顺序). 有点和 “RRD” 概念类似。
是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能
和标准的 collection 不同,你必须要显式的创建一个capped collection,指定一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。
可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。
由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。
要注意的是指定的存储大小包含了数据库的头信息。
1
db.createCollection("mycoll", {capped:true, size:100000})
在 capped collection 中,你能添加新的对象。
能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
删除之后,你必须显式的重新创建这个 collection。
在32bit机器中,capped collection 最大存储为 1e9( 1X109)个字节。
元数据
- 数据库的信息是存储在集合中。它们使用了系统的命名空间:
1
dbname.system.*
在MongoDB数据库中名字空间 <dbname>.system.* 是包含多种系统信息的特殊集合(Collection),如下:
1
2
3
4
5
6
集合命名空间 描述
dbname.system.namespaces 列出所有名字空间。
dbname.system.indexes 列出所有索引。
dbname.system.profile 包含数据库概要(profile)信息。
dbname.system.users 列出所有可访问数据库的用户。
dbname.local.sources 包含复制对端(slave)的服务器信息和状态。
对于修改系统集合中的对象有如下限制。
- 在插入数据,可以创建索引。
- 但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
- 是可修改的。
- 是可删除的。
MongoDB feature
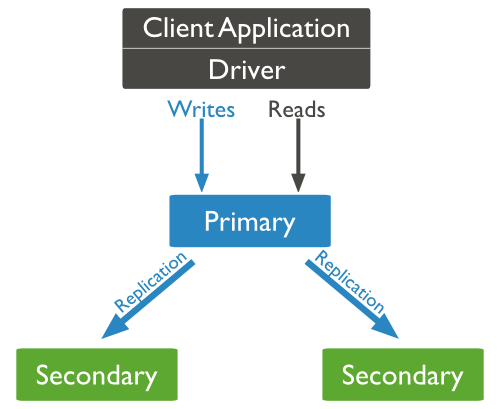
复制(副本集)
1
2
3
4
5
mongod --port "PORT" \
--dbpath "the_DB_DATA_PATH" \
--replSet "REPLICA_SET_INSTANCE_NAME"
rs.add(HOST_NAME:PORT)
- MongoDB复制是将数据同步在多个服务器的过程。
- 复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
- 复制还允许您从硬件故障和服务中断中恢复数据。
- MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
- 副本集设置
- 用
rs.initiate()在Mongo客户端使启动一个新的副本集。 - 用
rs.conf()查看副本集配置 - 用
rs.status()查看副本集状态
- 用
1
2
3
4
5
mongod --port 27017 \
--dbpath "D:\set up\mongodb\data" \
--replSet rs0
# 启动一个名为rs0的MongoDB实例,其端口号为27017。
启动后打开命令提示框并连接上mongoDB服务。
- 副本集添加成员
- 使用多台服务器来启动mongo服务。
- 进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
1
2
3
4
5
6
7
-- 已经启动了一个名为mongod1.net,端口号为27017的Mongo服务。
-- 在客户端命令窗口使用rs.add() 命令将其添加到副本集中
rs.add("mongod1.net:27017")
-- MongoDB中你只能通过主节点将Mongo服务添加到副本集中
-- 判断当前运行的Mongo服务是否为主节点可以使用命令db.isMaster()
分片
- 当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。
- 分片
- 在Mongodb里面存在另一种集群,就是分片技术
- 可以满足MongoDB数据量大量增长的需求。
- 通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵

三个主要组件:
- Shard:
- 用于存储实际的数据块,
- 实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
- Config Server:
- mongod实例
- 存储了整个 ClusterMetadata,其中包括 chunk信息。
- Query Routers:
- 前端路由
- 客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
-- 分片结构端口分布如下:
Shard Server 1:27020
Shard Server 2:27021
Shard Server 3:27022
Shard Server 4:27023
Config Server :27100
Route Process:40000
-- 步骤一:启动Shard Server
[root@100 /]# mkdir -p /www/mongoDB/shard/s0
[root@100 /]# mkdir -p /www/mongoDB/shard/s1
[root@100 /]# mkdir -p /www/mongoDB/shard/s2
[root@100 /]# mkdir -p /www/mongoDB/shard/s3
[root@100 /]# mkdir -p /www/mongoDB/shard/log
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 \
--dbpath=/www/mongoDB/shard/s0 \
--logpath=/www/mongoDB/shard/log/s0.log \
--logappend \
--fork
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 \
--dbpath=/www/mongoDB/shard/s3 \
--logpath=/www/mongoDB/shard/log/s3.log
--logappend \
--fork
-- 步骤二: 启动Config Server
[root@100 /]# mkdir -p /www/mongoDB/shard/config
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 \
--dbpath=/www/mongoDB/shard/config \
--logpath=/www/mongoDB/shard/log/config.log \
--logappend \
--fork
-- 完全可以像启动普通mongodb服务一样启动,不需要添加—shardsvr和configsvr参数。
-- 因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以。
-- 步骤三: 启动Route Process
/usr/local/mongoDB/bin/mongos --port 40000 \
--configdb localhost:27100 \
--logpath=/www/mongoDB/shard/log/route.log \
--fork \
--chunkSize 500
-- mongos启动参数中,chunkSize这一项是用来指定chunk的大小的,单位是MB,默认大小为200MB.
-- 步骤四: 配置Sharding
-- 使用MongoDB Shell登录到mongos,添加Shard节点
[root@100 shard]# /usr/local/mongoDB/bin/mongo admin \
--port 40000
db.runCommand({ addshard:"localhost:27020" })
-- { "shardAdded" : "shard0000", "ok" : 1 }
db.runCommand({ addshard:"localhost:27029" })
-- { "shardAdded" : "shard0009", "ok" : 1 }
-- 设置分片存储的数据库
db.runCommand({ enablesharding:"test" })
-- { "ok" : 1 }
db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}})
{ "collectionsharded" : "test.log", "ok" : 1 }
-- 步骤五: 程序代码内无需太大更改,直接按照连接普通的mongo数据库那样,将数据库连接接入接口40000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
-- 分片结构端口分布如下:
Shard Server 1:27020
Shard Server 2:27021
Shard Server 3:27022
Shard Server 4:27023
Config Server :27100
Route Process:40000
-- 1. 创建Sharding复制集 rs0
# mkdir /data/log
# mkdir /data/db1
# mkdir /data/db2
# nohup mongod --port 27020 \
--dbpath=/data/db1 \
--logpath=/data/log/rs0-1.log \
--logappend \
--fork \
--shardsvr \
--replSet=rs0 &
# nohup mongod --port 27021 \
--dbpath=/data/db2 \
--logpath=/data/log/rs0-2.log \
--logappend \
--fork \
--shardsvr \
--replSet=rs0 &
-- 1.1 复制集rs0配置
-- # mongo localhost:27020
rs.initiate(
{_id: 'rs0', members: [
{_id: 0, host: 'localhost:27020'},
{_id: 1, host: 'localhost:27021'}]})
rs.isMaster() -- #查看主从关系
-- 2. 创建Sharding复制集 rs1
# mkdir /data/db3
# mkdir /data/db4
# nohup mongod --port 27030 \
--dbpath=/data/db3 \
--logpath=/data/log/rs1-1.log \
--logappend \
--fork \
--shardsvr \
--replSet=rs1 &
# nohup mongod --port 27031 \
--dbpath=/data/db4 \
--logpath=/data/log/rs1-2.log \
--logappend \
--fork \
--shardsvr \
--replSet=rs1 &
-- 2.1 复制集rs1配置
-- # mongo localhost:27030
rs.initiate(
{_id: 'rs1', members: [
{_id: 0, host: 'localhost:27030'},
{_id: 1, host: 'localhost:27031'}]})
rs.isMaster() -- #查看主从关系
-- 3. 创建Config复制集 conf
# mkdir /data/conf1
# mkdir /data/conf2
# nohup mongod --port 27100 \
--dbpath=/data/conf1 \
--logpath=/data/log/conf-1.log \
--logappend \
--fork \
--configsvr \
--replSet=conf &
# nohup mongod --port 27101 \
--dbpath=/data/conf2 \
--logpath=/data/log/conf-2.log \
--logappend \
--fork \
--configsvr \
--replSet=conf &
-- 3.1 复制集conf配置
-- # mongo localhost:27100
rs.initiate(
{_id: 'conf', members: [
{_id: 0, host: 'localhost:27100'},
{_id: 1, host: 'localhost:27101'}]})
rs.isMaster() -- #查看主从关系
-- 4. 创建Route
# nohup mongos --port 40000 \
--configdb conf/localhost:27100,localhost:27101 \
--fork \
--logpath=/data/log/route.log \
--logappend &
-- 4.1 设置分片
-- # mongo localhost:40000
use admin
db.runCommand({ addshard: 'rs0/localhost:27020,localhost:27021'})
db.runCommand({ addshard: 'rs1/localhost:27030,localhost:27031'})
db.runCommand({ enablesharding: 'test'})
db.runCommand({ shardcollection: 'test.user', key: {name: 1}})
备份(mongodump)与恢复(mongorestore)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
mongodump -h dbhost -d dbname -o dbdirectory
-- 备份所有MongoDB数据
mongodump \
--host HOST_NAME \
--port PORT_NUMBER
mongodump \
--host runoob.com --port 27017
mongodump \
--dbpath DB_PATH \
--out BACKUP_DIRECTORY
mongodump \
--dbpath /data/db/ \
--out /data/backup/
-- 备份指定数据库的集合。
mongodump \
--db DB_NAME \
--collection COLLECTION
mongodump \
--db test \
--collection mycol
mongorestore \
-h <hostname><:port> \
-d dbname <path>
数据备份
- 用mongodump命令来备份MongoDB数据。
- 可以导出所有数据到指定目录中。
- 可以通过参数指定导出的数据量级转存的服务器。
-h:MongoDB 所在服务器地址,也可以指定端口号:127.0.0.1:27017-d:需要备份的数据库实例,例如:test-o:备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
1
2
3
4
5
-- 在本地使用 27017 启动你的mongod服务。
-- 打开命令提示符窗口,进入MongoDB安装目录的bin目录输入命令mongodump:
mongodump
-- 执行以上命令后,客户端会连接到ip为 127.0.0.1 端口号为 27017 的MongoDB服务上,并备份所有数据到 bin/dump/ 目录中。
-- 命令输出结果如下:
- 数据恢复
--host <:port>, -h <:port>: MongoDB所在服务器地址,默认为: localhost:27017--db , -d: 需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2--drop:- 恢复的时候,先删除当前数据,然后恢复备份的数据。
- 就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦! -
<path>: - mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。
- 不能同时指定
和 --dir 选项,--dir也可以设置备份目录。
--dir:- 指定备份的目录
- 你不能同时指定
和 --dir 选项。
1
2
>mongorestore
-- 执行以上命令输出结果如下:
监控
mongostat
- mongodb自带的状态检测工具
- 间隔固定时间获取mongodb的当前运行状态,并输出。
- 如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。 启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongostat命令,如下所示:
MongoDB 数据类型
MongoDB中常用的几种数据类型。
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,
- 包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数
- MongoDB 中存储的文档必须有一个
_id键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
1
2
3
4
5
6
7
8
var newObject = ObjectId()
newObject.getTimestamp()
// # ISODate("2017-11-25T07:21:10Z")
newObject.str
// # 5a1919e63df83ce79df8b38f
// # ObjectId 转为字符串
string
BSON 字符串都是 UTF-8 编码。
时间戳
- BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
- 后32位是在某秒中操作的一个递增的序数
- 在单个 mongod 实例中,时间戳值通常是唯一的。
- 在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
- BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。
日期类型是有符号的, 负数表示 1970 年之前的日期。
1
2
3
4
5
6
7
8
9
10
11
12
13
var mydate1 = new Date() //格林尼治时间
mydate1
// ISODate("2018-03-04T14:58:51.233Z")
typeof mydate1
// object
var mydate2 = ISODate() //格林尼治时间
mydate2
// ISODate("2018-03-04T15:00:45.479Z")
typeof mydate2
// object
这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。 返回一个时间类型的字符串:
1
2
3
4
5
6
7
8
var mydate1str = mydate1.toString()
mydate1str
// Sun Mar 04 2018 14:58:51 GMT+0000 (UTC)
typeof mydate1str
// string
// 或者
Date()
// Sun Mar 04 2018 15:02:59 GMT+0000 (UTC)
Basic
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
use runoob
-- switched to db runoob
db
-- runoob
show dbs
-- admin 0.000GB
-- config 0.000GB
-- local 0.000GB
db.runoob.insertOne({"name":"Grace"})
-- WriteResult({ "nInserted" : 1 })
show dbs
-- admin 0.000GB
-- config 0.000GB
-- local 0.000GB
-- runoob 0.000GB
db.createCollection("runoob")
show tables
-- runoob
db.runoob.drop()
-- true
show tables
db.dropDatabase()
-- { "dropped" : "runoob", "ok" : 1 }
show dbs
-- admin 0.000GB
-- config 0.000GB
-- local 0.000GB
-- ============ Collection ============
db.createCollection("runoob")
-- { "ok" : 1 }
show collections
-- runoob
-- system.indexes
show tables
runoob
db.mycol2.insert({"name" : "Grace"})
show collections
-- mycol2
db.mycol2.drop()
-- true
-- ============ document ============
db.col.insert(
{
title: 'MongoDB_class',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'Grace',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
document=(
{
title: 'MongoDB_class',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'Grace',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
});
db.col.insert(document)
db.col.find()
创建删除数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
use DATABASE_NAME
-- 如果数据库不存在,则创建数据库,否则切换到指定数据库。
-- 创建了数据库 runoob:
use runoob
switched to db runoob
db
runoob
-- 查看所有数据库
show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
-- 可以看到,我们刚创建的数据库 runoob 并不在数据库的列表中,
-- 要显示它,我们需要向 runoob 数据库插入一些数据。
db.runoob.insertOne({"name":"Grace"})
WriteResult({ "nInserted" : 1 })
show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
runoob 0.000GB
- MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
- 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
db.dropDatabase()
-- 删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
use runoob
switched to db runoob
-- 执行删除命令:
db.dropDatabase()
{ "dropped" : "runoob", "ok" : 1 }
show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
创建删除集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
use runoob
switched to db runoob
-- 先创建集合,类似数据库中的表
db.createCollection("runoob")
{ "ok" : 1 }
show collections
runoob
system.indexes
show tables
runoob
db.runoob.drop()
true
show tables
-- 创建固定集合 mycol,整个集合空间大小 6142800 B, 文档最大个数为 10000 个。
db.createCollection(
"mycol", {
capped : true,
autoIndexId : true,
size : 6142800,
max : 10000 }
)
{ "ok" : 1 }
-- 在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
db.mycol2.insert({"name" : "Grace"})
show collections
mycol2
-- 删除集合 mycol2
db.mycol2.drop()
true
插入文档
- 文档的数据结构和 JSON 基本一样。
- 所有存储在集合中的数据都是 BSON 格式。
- BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
MongoDB 使用 insert() 或 save() 方法向集合中插入文档,
1
2
3
db.COLLECTION_NAME.insert(document)
或
db.COLLECTION_NAME.save(document)
save():- 如果 _id 主键存在则更新数据,如果不存在就插入数据。
- 该方法新版本中已废弃,用
db.collection.insertOne()或db.collection.replaceOne()来代替。 - 如果不指定 _id 字段 save() 方法类似于 insert() 方法。
- 如果指定 _id 字段,则会更新该 _id 的数据。
insert():- 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)
或
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
db.collection.insertOne(): 用于向集合插入一个新文档db.collection.insertMany(): 用于向集合插入多个文档- document:要写入的文档。
- writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
- ordered:指定是否按顺序写入,默认 true,按顺序写入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
-- 以下文档可以存储在 MongoDB 的 runoob 数据库 的 col 集合中:
db.col.insert(
{
title: 'MongoDB_class',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'Grace',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
-- col 是集合名,
-- 如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
-- 查看已插入文档:
db.col.find()
-- {
-- "_id" : ObjectId("56064886ade2f21f36b03134"),
-- "title" : "MongoDB_class",
-- "description" : "MongoDB 是一个 Nosql 数据库",
-- "by" : "Grace",
-- "url" : "https://www.runoob.com",
-- "tags" : [ "mongodb", "database", "NoSQL" ],
-- "likes" : 100
-- }
-- 我们也可以将数据定义为一个变量,如下所示:
document=(
{
title: 'MongoDB_class',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'Grace',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
});
db.col.insert(document)
WriteResult({ "nInserted" : 1 })
db.col.save(document) 命令。
var res = db.collection.insertMany([{"b": 3}, {'c': 4}])
res
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("571a22a911a82a1d94c02337"),
ObjectId("571a22a911a82a1d94c02338")
]
}
更新文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。
update(): 用于更新已存在的文档query: update的查询条件,类似sql update查询内where后面的。update: update的对象和一些更新的操作符(如$,$inc…)等,也可以理解为sql update查询内set后面的upsert: 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。multi: 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。writeConcern:可选,抛出异常的级别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
db['your_collection'].countDocuments({ my_key: { $exists: true } })
db['your_collection'].countDocuments({ my_key: "xxx" })
db['your_collection'].updateMany({}, { $unset: { my_key: 1 } })
db['your_collection'].updateMany({ my_key: "xxx"}, { $unset: { my_key: 1 } })
db['your_collection'].updateMany({ my_key: "xx"},{ $set: { my_2nd_key: true } })
db["scans"].updateMany(
{ repo: "git@github.pie.apple.com:aidp-security/vulnerable-secrets-code-samples.git"},
{ $set: { is_test_scan: true } }
)
db["scans"].updateMany(
{ repo: "git@github.pie.apple.com:aidp-security/GenAI-Test-JavaTC1-VulnerableJavaApp.git"},
{ $set: { is_test_scan: true } }
)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
// -- 实例
mdb.col.insert(
{
title: 'MongoDB_class',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'Grace',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
}
)
-- 修改第一条发现的文档
-- 更新标题(title):
db.col.update(
{'title':'MongoDB_class'},
{
$set:{
'title':'MongoDB'
}
}
)
-- WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
db.col.find().pretty()
-- {
-- "_id" : ObjectId("56064f89ade2f21f36b03136"),
-- "title" : "MongoDB",
-- "description" : "MongoDB 是一个 Nosql 数据库",
-- "by" : "Grace",
-- "url" : "https://www.runoob.com",
-- "tags" : [
-- "mongodb",
-- "database",
-- "NoSQL"
-- ],
-- "likes" : 100
-- }
-- 修改多条相同的文档,则需要设置 multi 参数为 true。
db.col.update(
{'title':'MongoDB_class'},
{$set:{'title':'MongoDB'}},
{multi:true}
)
-- 只更新第一条记录:
db.col.update(
{ "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
-- 全部更新:
db.col.update(
{ "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
-- 只添加第一条:
db.col.update(
{ "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
-- 全部添加进去:
db.col.update(
{ "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
-- 全部更新:
db.col.update(
{ "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
-- 只更新第一条记录:
db.col.update(
{ "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
save()方法- 通过传入的文档来替换已有文档
_id主键存在就更新,不存在就插入。- document : 文档数据。
- writeConcern :可选,抛出异常的级别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
-- 替换了 _id 为 56064f89ade2f21f36b03136 的文档数据:
db.col.save(
{
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Runoob",
"url" : "https://www.runoob.com",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 110
})
-- 替换成功
>db.col.find().pretty()
{
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Runoob",
"url" : "https://www.runoob.com",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 110
}
删除文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
db.collection.remove(
<query>,
<justOne>
)
-- MongoDB 是 2.6 版本以后
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
db.inventory.deleteMany({})
db.inventory.deleteMany({ status: "A" })
db.inventory.deleteOne( { status: "D" } )
remove()函数是用来移除集合中的数据。query:(可选)删除的文档的条件。justOne: (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。writeConcern:(可选)抛出异常的级别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
-- 执行两次插入操作:
db.col.insert(
{
title: 'MongoDB_class',
description: 'MongoDB 是一个 Nosql 数据库',
by: 'Grace',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
db.col.find()
{ "_id" : ObjectId("56066169ade2f21f36b03137"), ... }
{ "_id" : ObjectId("5606616dade2f21f36b03138"), ... }
-- 移除 title 为 'MongoDB_class' 的文档:删除两条数据
db.col.remove({'title':'MongoDB_class'})
WriteResult({ "nRemoved" : 2 })
-- 只删除第一条找到的记录可以设置 justOne 为 1,如下所示:
db.col.remove({'title':'MongoDB_class'},1)
删除所有数据
db.col.remove({})
db.col.find()
官方推荐使用 deleteOne() 和 deleteMany() 方法。
1
2
3
4
5
6
7
-- 删除集合下全部文档:
db.inventory.deleteMany({})
-- 删除 status 等于 D 的一个文档:
db.inventory.deleteOne( { status: "D" } )
-- 删除 status 等于 A 的全部文档:
db.inventory.deleteMany({ status : "A" })
查询文档
1
2
db.collection.find(query, projection)
db.collection.find().pretty()
findOne()方法- 只返回一个文档。
find()方法- 以非结构化的方式来显示所有文档。
query:可选,使用查询操作符指定查询条件projection:可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
pretty()方法- 以易读的方式来读取数据
- 以格式化的方式来显示所有文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
查询了集合 col 中的数据:
db.col.find().pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB_class",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Grace",
"url" : "https://www.runoob.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
AND 条件
1
db.col.find({key1:value1, key2:value2}).pretty()
find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
1
2
3
-- 通过键来查询数据
-- 类似于 WHERE 语句:WHERE by='Grace' AND title='MongoDB_class'
db.col.find({"by":"Grace", "title":"MongoDB_class"}).pretty()
OR 条件
1
2
3
4
5
6
7
8
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
1
2
3
4
5
6
7
8
9
10
-- 查询键 by 值为 Grace
-- 或
-- 键 title 值为 MongoDB_class 的文档。
db.col.find(
{$or:[
{"by":"Grace"},
{"title": "MongoDB_class"}
]}
).pretty()
AND 和 OR 联合使用
1
2
3
4
5
6
7
8
-- 类似常规 SQL 语句为: 'where likes>50 AND (by = 'Grace' OR title = 'MongoDB_class')'
db.col.find({
"likes": {$gt:50},
$or: [
{"by": "Grace"},
{"title": "MongoDB_class"}]
}).pretty()
条件操作符
MongoDB 与 RDBMS Where 语句比较
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| = | { | db.col.find({“by”:”ana”}).pretty() | where by = ‘ana’ |
| < | { | db.col.find({“likes”:{$lt:50}}).pretty() | where likes < 50 |
| <= | { | db.col.find({“likes”:{$lte:50}}).pretty() | where likes <= 50 |
| > | { | db.col.find({“likes”:{$gt:50}}).pretty() | where likes > 50 |
| >= | { | db.col.find({“likes”:{$gte:50}}).pretty() | where likes >= 50 |
| != | { | db.col.find({“likes”:{$ne:50}}).pretty() | where likes != 50 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
db.col.insert({
title: 'PHP 教程',
description: 'PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。',
by: '菜鸟教程',
url: 'https://www.runoob.com',
tags: ['php'],
likes: 200
})
db.col.insert({
title: 'Java 教程',
description: 'Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。',
by: '菜鸟教程',
url: 'https://www.runoob.com',
tags: ['java'],
likes: 150
})
db.col.insert({
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'https://www.runoob.com',
tags: ['mongodb'],
likes: 100
})
db.col.find()
db.col.find({likes : {$gt : 100}})
{ ..., "likes" : 200 }
{ ..., "likes" : 150 }
db.col.find({likes : {$gte : 100}})
{ ..., "likes" : 200 }
{ ..., "likes" : 150 }
{ ..., "likes" : 100 }
db.col.find({likes : {$lt : 150}})
{ ..., "likes" : 100 }
db.col.find({likes : {$lte : 150}})
{ ..., "likes" : 150 }
{ ..., "likes" : 100 }
db.col.find({likes : {$lt :200, $gt : 100}})
{ "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "菜鸟教程", "url" : "https://www.runoob.com", "tags" : [ "java" ], "likes" : 150 }
>
$type 操作符
$type: 基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
db.col.insert(
{
title: 'PHP 教程',
description: 'PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。',
by: '菜鸟教程',
url: 'https://www.runoob.com',
tags: ['php'],
likes: 200
})
db.col.insert(
{
title: 'Java 教程',
description: 'Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。',
by: '菜鸟教程',
url: 'https://www.runoob.com',
tags: ['java'],
likes: 150
})
db.col.insert(
{
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'https://www.runoob.com',
tags: ['mongodb'],
likes: 100
})
-- 使用find()命令查看数据:
db.col.find()
-- 获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令:
db.col.find({"title" : {$type : 2}})
db.col.find({"title" : {$type : 'string'}})
Limit() 与 Skip()
1
2
3
db.COLLECTION_NAME.find().limit(NUMBER)
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
Limit():- 在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,
- limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
- 如果没指定limit()方法中的参数, 则显示集合中的所有数据。
1
2
3
4
5
6
7
-- 显示查询文档中的两条记录:
db.col.find(
{},
{"title":1,_id:0}
).limit(2)
{ "title" : "PHP 教程" }
{ "title" : "Java 教程" }
Skip():- 使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,
- skip方法同样接受一个数字参数作为跳过的记录条数。
- skip()方法默认参数为 0 。
1
2
3
-- 只显示第二条文档数据
db.col.find({},{"title":1,_id:0}).limit(1).skip(1)
{ "title" : "Java 教程" }
排序
1
db.COLLECTION_NAME.find().sort({KEY:1})
sort():- 对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,
- 1 为升序排列,而 -1 是用于降序排列。
1
2
3
4
5
6
7
8
-- 集合中的数据按字段 likes 的降序排列:
db.col.find({},{"title":1,_id:0}).sort({"likes":-1})
{ "title" : "PHP 教程" }
{ "title" : "Java 教程" }
{ "title" : "MongoDB 教程" }
-- Limit与Skip方法MongoDB 索引
-- skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
index
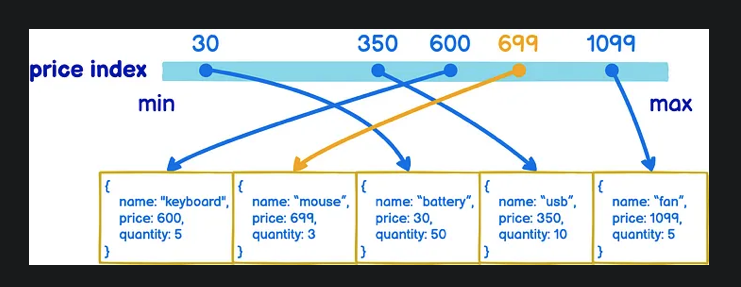
假如你今天開一間五金行,要用資料庫來記錄各個商品的庫存(inventory)狀況,那你的 collection 裡面就會有鍵盤. 滑鼠. 電風扇等等商品的價格跟數量
這時如果根據價格幫他們建 index,讓商品從最便宜排到最貴,那 MongoDB 並不會去修改資料在硬碟中的位置,而是會另外建一個 price 排序過後的清單並用指標指向資料位置。如此一來,當你想要找價格 699 元的東西時,Mongo 就會很快的從那個清單來找,再藉由指標拿到真實資料
因為 index 只是另外建一個清單,所以想在同一個 collection 內建多個 index 也是沒問題的唷!譬如說我可以同時幫 price 跟 quantity 建 index,這樣在根據價格或數量做 query 時就都有 index 可以用

1
db.collection.createIndex(keys, options)
- 索引通常能够极大的提高查询的效率
- 如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
- 扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
- 索引是特殊的数据结构
- 索引存储在一个易于遍历读取的数据集合中
索引是对数据库表中一列或多列的值进行排序的一种结构
createIndex(): 创建索引。- 注意在 3.0.0 版本前创建索引方法为
db.collection.ensureIndex(),是 createIndex() 的别名。 Key: 值为索引字段,1 为指定按升序创建索引,降序为 -1- Parameter Type Description
backgroundBoolean- 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。
uniqueBoolean- 建立的索引是否唯一。指定为true创建唯一索引。默认值为false.
namestring- 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。
dropDupsBoolean- 3.0+版本已废弃。
- 在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false.
sparseBoolean- 对文档中不存在的字段数据不启用索引;
- 这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档。
- 默认值为 false.
expireAfterSecondsinteger- 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。
vindex version- 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。
weightsdocument- 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。
default_languagestring- 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语
language_overridestring- 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language.
- 注意在 3.0.0 版本前创建索引方法为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
db.col.createIndex({"title":1})
-- 设置使用多个字段创建索引(关系型数据库中称作复合索引)。
db.col.createIndex({"title":1,"description":-1})
-- 在后台创建索引:
db.values.createIndex({open: 1, close: 1}, {background: true})
通过在创建索引时加 background:true 的选项,让创建工作在后台执行
-- 查看集合索引
db.col.getIndexes()
-- 查看集合索引大小
db.col.totalIndexSize()
-- 删除集合所有索引
db.col.dropIndexes()
-- 删除集合指定索引
db.col.dropIndex("索引名称")
-- 利用 TTL 集合对存储的数据进行失效时间设置:
-- 经过指定的时间段后或在指定的时间点过期,MongoDB 独立线程去清除数据。
-- 类似于设置定时自动删除任务,可以清除历史记录或日志等前提条件,设置 Index 的关键字段为日期类型 new Date()。
-- 例如数据记录中 createDate 为日期类型时:
-- 设置时间180秒后自动清除。
-- 设置在创建记录后,180 秒左右删除。
db.col.createIndex({"createDate": 1},{expireAfterSeconds: 180})
-- 由记录中设定日期点清除。
-- 设置 A 记录在 2019 年 1 月 22 日晚上 11 点左右删除,
-- A 记录中需添加 "ClearUpDate": new Date('Jan 22, 2019 23:00:00'),且 Index中expireAfterSeconds 设值为 0。
db.col.createIndex({"ClearUpDate": 1},{expireAfterSeconds: 0})
-- 索引关键字段必须是 Date 类型。
-- 非立即执行:扫描 Document 过期数据并删除是独立线程执行,默认 60s 扫描一次,删除也不一定是立即删除成功。
-- 单字段索引,混合索引不支持。
index types
Single Field Indexes 单索引实例
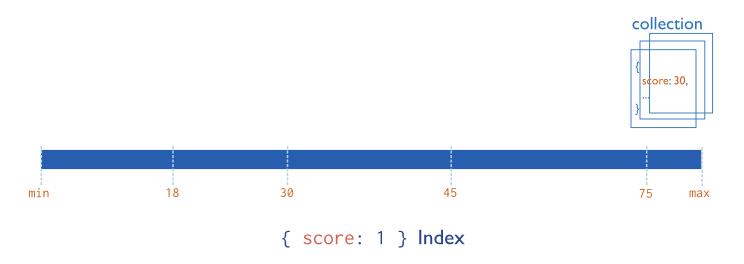
Create an Ascending Index on a Single Field
- Consider a collection named records that holds documents that resemble the following sample document:
1
2
3
4
5
6
7
8
9
10
11
12
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}
-- creates an ascending index on the score field of the records collection:
db.records.createIndex( { score: 1 } )
-- The created index will support queries that select on the field score, such as the following:
db.records.find( { score: 2 } )
db.records.find( { score: { $gt: 10 } } )
The value of the field in the index specification describes the kind of index for that field.
- value of
1specifies an index that orders items in ascending order. - value of
-1specifies an index that orders items in descending order.
Create an Index on an Embedded Field
- create indexes on fields within embedded documents,
- there is a maximum index size of the embedded document in the index.
- indexes on embedded fields allow you to use a “dot notation,” to introspect into embedded documents.
Consider a collection named records that holds documents that resemble the following sample document:
1
2
3
4
5
6
7
8
9
10
11
12
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}
-- creates an index on the location.state field:
db.records.createIndex( { "location.state": 1 } )
-- support queries that select on the field location.state, such as the following:
db.records.find( { "location.state": "CA" } )
db.records.find( { "location.city": "Albany", "location.state": "NY" } )
例: 文档评分集合
- 用例数据结构大致如下,我们会建立索引的字段有
score以及mail.date
1
2
3
4
5
6
7
8
9
{
"_id" : ObjectId("562ba634ef2109c32a3e3ca5"),
"mail" : {
"date" : ISODate("2015-10-15T17:11:58.000+08:00"),
"receivedDate" : ISODate("2015-10-24T23:39:32.069+08:00"),
"subject" : "ab"
},
"score" : 0
}
- 重要的文档数量指标的关系为:
- nscanned >= nscannedObjects >= n,
- 扫描数(索引条目) >= 查询数(通过索引到硬盘上查询的文档数) >= 返回数(匹配查询条件的文档数)
我们查询score分数大于0的值。
- 不建立索引
db.mails.find({ "score": { $gt: 0 }}).explain()- mongoDB总共扫描了27249条文档并返回了1297条文档数据。
- 运行这条查询大概花了0.366秒
- 使用索引的结果
- 使用
db.mails.ensureIndex({ "score": 1 })将score字段依据升序来创建索引。 - 其nscannedObjects和nscanned都缩小至1297,也就是实际返回的文档数。
- 表明查询通过索引减少了大量的迭代过程。
- 查询的时间也减少至 0.242 秒。可见通过索引提高了我们这种多值查询的效率。
- 使用
- 我们再回到1.1,索引的本质是树(B树),最小的值在最左边的叶子上,最大的值在最右边的叶子上。这种数据结构能够让查找数据, 循序存取, 插入数据及删除的动作,都在对数时间内完成。
Compound Indexes 复合索引

MongoDB imposes a limit of 32 fields for any compound index.
索引的值是按照一定顺序排列的。因此在使用索引对文档排序是非常快。
- 然而当我们需要对两个字段排序时,单索引就无法满足了。这样就引入复合索引,
复合索引是建立在多个字段上的索引。
The order of the fields listed in a compound index is important. The index will contain references to documents sorted first by the values of the item field and, within each value of the item field, sorted by values of the stock field.
- In addition to
supporting queries that match on all the index fields, compound indexes cansupport queries that match on the prefix of the index fields.
Create a Compound Index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
"_id": ObjectId(...),
"item": "Banana",
"category": ["food", "produce", "grocery"],
"location": "4th Street Store",
"stock": 4,
"type": "cases"
}
-- creates an ascending index on the item and stock fields:
db.products.createIndex( { "item": 1, "stock": 1 } )
-- the index supports queries on the item field as well as both item and stock fields:
db.products.find( { item: "Banana" } )
db.products.find( { item: "Banana", stock: { $gt: 5 } } )
例: 文档评分集合
- 既然扩展到多个字段,那么不同的方向对生成的索引就有影响了。
{ "score": 1, "mail.date": -1 }与{ "score": 1, "mail.date": 1 }就是不一样的索引。
- 当然,这只对需要多字段条件排序是,其方向才显得比较重要。
- 复合索引对不同的查询可以表现为不同的索引。
{ "score": 1, "mail.date": -1 }即可以对两个字段排序,也可以对{ "score": 1 }进行排序。- 如果只是基于单一键进行排序,MongoDB可以简单地从相反方向读取索引。
- 比如这个索引就可以对{ “score”: -1 }有效。
查询score大于0的文档并且还获取最近10天的文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
-- 查询语句
db.mails.find(
{
"score": { $gt: 0},
"mail.date": { $gt: ISODate("2015-12-18T0000:00.000+08:00") }
}
).sort({ "mail.date": -1})
-- 在现有的索引下的查询过程:
由于只对score建了索引
查询依据第一个条件("score": { $gt: 0})扫描到1297个文档
然而通过第二个条件("mail.date": { $gt: ISODate("2015-12-18T0000:00.000+08:00") })得到81个匹配条件的文档。
其运行的时间有0.276秒。
-- 创建了单独的索引
{ "mail.date": 1 },
-- 复合索引
{ "score": 1, "mail.date": -1 }
{ "score": 1, "mail.date": 1 }
{ "mail.date": 1, "score": 1 }
{ "mail.date": 1, "score": -1 }
其”cursor”为”BtreeCursor mail.date_1_score_1 reverse”数目:
- reverse 的意思是查询结果是以”mail.date”倒序返回,所以将索引反向。
- nscanned的值并不理想,扫描了索引的5723个条目,当然通过复合索引还是减少了文档的扫描数。
- 那么我们通过传递.explain()参数true来查看其他query plan的过程。
- 在”allPlans”数组中总共有6个plan,
- 第一个是
mail.date_1_score_1 reverse - 第二个是
mail.date_1_score_-1其与上一次差不多也是查询了索引的5723个条目。 - 第三个是
mail.date_1 reverse也就是{mail.date: 1 }索引的反向
其”nscanned”, “nscannedObjects”, “n”数目:
- mongoDB通过索引找到了83个条目,然后依据索引在硬盘上找到了82条文档记录,但是最后与查询条件匹配发现没有一条满足查询条件的(这里很可能是score字段没有满足)。
这与mongoDB的查询优化器的工作有关。
- 如果一个索引够精确匹配一个查询,那么查询优化器就会使用这个索引。
- 如果有几个索引都适合你的查询。
- MongoDB会从这些索引子集中查询计划选择一个,这些查询计划是并行执行的。
- 最早返回100个结果的就是胜者,其他的查询计划就会被终止。
- explain()输出的信息里的”allPlans”字段显示了本次查询尝试的每个查询计划。
也就是说,基于索引"mail.date_1 reverse"的查询在没有完成其查询计划时,就被终止了。其记录保留终止前所处理的数据量。
- 让我们把这个索引查询跑完
- 通过.hint()加上索引来指定使用某个索引。
1
2
3
4
5
6
7
-- 运行
db.mails.find(
{
"score": { $gt: 0},
"mail.date": { $gt: ISODate("2015-12-18T0000:00.000+08:00") }
}
).sort({ "mail.date": -1}).hint({ "mail.date": -1 }).explain(true):
这样就发现了,通过这个索引扫描的文档比原来的多得多,特别是在消耗硬盘读写的地方也增加到了6198。 当然,在这次数据量的测试集上,使用不同索引的速度比较还是不太明显。两者都接近于0.3秒左右。其他四个索引的处理过程也大致如此,成为落选者。
Sort Order
- Indexes store references to fields in either ascending (1) or descending (-1) sort order.
- For single-field indexes, the sort order of keys doesn’t matter because MongoDB can traverse the index in either direction.
- For compound indexes, sort order can matter in determining whether the index can support a sort operation.
1
2
3
4
5
6
7
8
9
10
db.events.createIndex( { "username" : 1, "date" : -1 } )
-- index can support these sort operations:
db.events.find().sort( { username: 1, date: -1 } )
db.events.find().sort( { username: -1, date: 1 } )
-- However, the above index cannot support sorting by ascending username values and then by ascending date values, such as the following:
db.events.find().sort( { username: 1, date: 1 } )
index intersection
通过这个功能,mongoDB可以使用多个索引之间的交集来处理查询。
- mongoDB中的索引
{ "score": 1, "mail.date": -1 }只能查询score的顺序或者对两个字段进行查询,但是不能使用索引对 “mail.date” 字段进行查询和排序。 - 如果建立两个索引
{ "score": 1 }, { "mail.date": -1 },这两个索引即可以单独使用,也可以在一个查询中使用。
值得注意的是索引在查询排序上的限制,当排序需要完全与查询条件的索引时 是无法使用索引交集的。
- 将复合索引都进行删除,只保留
{ "mail.date": 1}, {"score": 1 }。 - 进行原始查询语句
1
2
3
4
5
6
db.mails.find(
{
"score": { $gt: 0},
"mail.date": { $gt: ISODate("2015-12-18T0000:00.000+08:00") }
}
).sort({ "mail.date": -1})
- 其采用的索引还是
score_1,但是在allPlans中还是有Complex Plan的cursor,只不过其查询索引的数目才到1379条,比不上单索引罢了。
Sometimes, one index is more selective than another. But it doesn”t mean that it returns more quickly the result.
虽然对”name”字段进行所能能过滤掉很多文档,但是最终还是需要针对整个查询语句进行数据比较。
而针对”date”可能会导致索引的条目太多,但是其后的”name”匹配会相对更加简单。
Partial Indexes
https://www.mongodb.com/docs/manual/core/index-partial/
索引的坑
为什么我前面这样介绍索引呢?因为索引是一切后续操作的前导,就是前两篇文章讲到的MR和AF操作就需要先进行查询操作。我在进行AF计算测试时,尝试将一个月的数据进行统计(大约1387w条数据),程序无法跑通,总是报getmore error:
1
2
3
4
5
Error: command failed: {
"errmsg" : "exception: getMore: cursor didn't exist on server, possible restart or timeout?",
"code" : 13127,
"ok" : 0
}
这个错误发生的原因是游标(cursor,返回查询结果的指针)的”超时销毁”机制。
- 游标是通过迭代来遍历结果的。
- 当游标完成结果的迭代时,它会清除自身。
- 而”超时销毁”就是当游标没有完成迭代,但是超过10分钟内没有使用的情形下(进入stale),游标被强制销毁。这种机制当然是我们希望的:
- 极少有应用程序希望用户花费数分钟坐在那里等待结果。
但是也会遇到问题。
- 当数据量太大时,主机无法在10分钟内完成当次的计算任务,使得游标被回收。
- mongoDB返回这个错误,使得程序无法执行。
- 而出现这个原因也是因为提取较大的子数据集时,查询不使用会更快。
- 因为索引需要进行两次查找:一次是查找索引条目,一次是根据索引指针去查找相应的文档。
这时我们就只能通过实验来判断是否需要使用索引了。
- 我们采用前两篇的执行逻辑来寻聚合操作。可以得出:在当前环境下,没有索引的查询速度还是比有索引的情况要快。如果若要给一个参考值的话,可以应用权威指南里的内容:这个数据可能会在2%~60%之间变动。
索引的创建
在数据量超大的情形下,任何数据库系统在创建索引时都是一个耗时的大工程。MongoDB也不例外。
- MongoDB 创建索引比较耗时,如果在数据写入完毕以后再去创建索引,创建的过程会异常的漫长;
所以,尽可能在设计表的时候就明确需要那些索引,创建集合的同时创建索引,之后再写入数据;
- MongoDB索引的创建有两种选择,一个是前台方式,一个是后台方式。
前台方式
- 如果集合里面有很多数据,并且你使用的是前台索引,那么此时创建索引会把这个集合锁起来,所有对这个集合的写入操作都会挂起,查询操作也会异常的缓慢;
此时,如果集合中数据已经有很多,创建索引的过程可能需要好几个小时,挂起的写入数据会堆积在内存里面,很有可能把内存撑爆;
缺省情况下,当为一个集合创建索引时,这个操作将阻塞其他的所有操作。即该集合上的无法正常读写,直到索引创建完毕
- 任意基于所有数据库申请读或写锁都将等待直到前台完成索引创建操作
后台方式
将索引创建置于到后台,适用于那些需要长时间创建索引的情形
这样子在创建索引期间,MongoDB依旧可以正常的为提供读写操作服务
等同于关系型数据库在创建索引的时候指定online,而MongoDB则是指定background
其目的都是相同的,即在索引创建期间,尽可能的以一种占用较少的资源占用方式来实现,同时又可以提供读写服务
- 代价:
- 索引创建时间变长
- 后台创建索引不会影响 MongoDB 的使用,但是耗费的时间会更久;
- 在后台创建索引期间,MongoDB 执行效能会下降,应在合理的时间段内完成索引的创建,不影响正常的业务。
- 后台创建索引的示例:
1
2
db.people.createIndex( { name: 1}, {background: true} )
db.people.createIndex( { name: 1}, {background: true, sparse: true } )
注意:缺省情况下background选项的值为false。
注意事项
- 创建期间
如前所述:基于后台创建索引时,其他的数据库操作能被完成。但是对于mongo shell会话或者你正在创建索引的这个连接将不可用,直到所有创建完毕。如果需要做一些其它的操作。则需要再建立其它的连接。
在索引创建期间,即使完成了部分索引的创建,索引依旧不可用,但是一旦创建完成即可使用。
- 基于后台创建索引期间不能完成涉及该集合的相关管理操作
1
2
3
4
5
- repairDatabase
- db.collection.drop()
- compact
意外中断索引创建
如果在后台创建索引期间,mongod实例异常终止,当mongod实例重新启动后,未完成的索引创建将作为前台进程来执行
如果索引创建失败,比如由于重复的键等,mongod将提示错误并退出
在一个索引创建失败后启动mongod,可以使用
storage.indexBuildRetry or --noIndexBuildRetry跳过索引创建来启动
- 索引创建期间性能
后台创建索引比前台慢,如果索引大于实际可用内存,则需要更长的时间来完成索引创建;
所有涉及到该集合的相关操作在后台期间其执行效率会下降,应在合理的维护空挡期完成索引的创建。
- 正确方法中断创建索引进程
- ctrl + c 中断的是与 MongoDB 的连接,并不能中断创建索引的进程;
- 重启 MongoDB 也不能中断创建索引的进程;
- 正确的方法是,先查看创建索引进程的 pid 进程号
- 然后,从返回的内容中找到类似于下面的内容,这串数字就是 pid 进程号;
- 最后,杀死 pid 进程
1
2
3
4
5
6
7
8
9
10
11
12
db.currentOp(
{
$or: [
{ op: "command", "query.createIndexes": { $exists: true } },
{ op: "insert", ns: /\.system\.indexes\b/ }
]
}
)
-- 然后,从返回的内容中找到类似于下面的内容,这串数字就是 pid 进程号;
"opid" : 1153352,
-- 最后,杀死 pid 进程
db.killOp(pid 进程号)
- 查看索引的创建进度
- 可使用
db.currentOp()命令观察索引创建的完成进度
- 可使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
-- 创建一个500w文档的集合
for (var i=1;i<=5000000;i++){
db.inventory.insert({
id:i,item:"item"+i,
stock:Math.floor(i*Math.random())})
}
WriteResult({ "nInserted" : 1 })
db.inventory.find().limit(3)
{ "_id" : ObjectId("581bfc674b0d633653f4427e"),
"id" : 1, "item" : "item1", "stock" : 0 }
{ "_id" : ObjectId("581bfc674b0d633653f4427f"),
"id" : 2, "item" : "item2", "stock" : 0 }
{ "_id" : ObjectId("581bfc674b0d633653f44280"),
"id" : 3, "item" : "item3", "stock" : 1 }
db.inventory.find().count()
5000000
-- 创建索引
db.inventory.createIndex({item:1,unique:true})
-- 查看索引完成进度
db.currentOp(
{
$or: [
{ op: "command",
"query.createIndexes": { $exists: true}
},
{ op: "insert", ns: /\.system\.indexes\b/
}
]
}
)
db.currentOp(
{
$or: [
{ op: "command", "query.createIndexes": { $exists: true } },
{ op: "insert", ns: /\.system\.indexes\b/ }
]
}
)
-- 结果如下
{
"inprog": [
{
"desc": "conn1", //连接描述
"threadId": "139911670933248", //线程id
"connectionId": 1,
"client": "127.0.0.1:37524", //ip及端口
"active": true, //活动状态
"opid": 5014925,
"secs_running": 21, //已执行的时间
"microsecs_running": NumberLong(21800738),
"op": "command",
"ns": "test.$cmd",
"query": {
"createIndexes": "inventory", //这里描述了基于inventory正在创建索引
"indexes": [
{
"ns": "test.inventory",
"key": {
"item": 1,
"unique": true
},
"name": "item_1_unique_true"
}
]
},
"msg": "Index Build Index Build: 3103284/5000000 62%", //这里是完成的百分比
"progress": {
"done": 3103722,
"total": 5000000
},
"numYields": 0,
"locks": { //当前持有的锁
"Global": "w",
"Database": "W",
"Collection": "w"
},
"waitingForLock": false,
"lockStats": { //锁的状态信息
"Global": {
"acquireCount": {
"r": NumberLong(1),
"w": NumberLong(1)
}
},
"Database": {
"acquireCount": {
"W": NumberLong(1)
}
},
"Collection": {
"acquireCount": {
"w": NumberLong(1)
}
}
}
}
],
"ok": 1
}
-- 如果返回如下内容,则表示索引创建成功
mongo { "inprog" : [ ], "ok" : 1 }
-- 后台方式创建索引
db.inventory.createIndex({item:1,unique:true},{background: true})
- 利用expalin进行性能查询分析
1
2
3
4
5
6
7
8
9
-- 创建索引前:
db.stu.find({name:"test20000"}).explain("executionStats")
-- executionStats下的executionTimeMills表示整体查询时间,单位毫秒。
-- 创建索引后:
db.stu.ensureIndex({"name":1})
db.stu.find({name:"test20000"}).explain("executionStats")
-- 时间由原来的806毫秒,减少到了3毫秒,性能提升很高。
- 索引的命名规则
- 缺省情况下,索引名以键名加上其创建顺序(1或者-1)组合
- 创建索引时最好指定 索引 name
- 如果不指定索引的 name,则mongo会在索引 key 后面加 _1 后缀,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
-- 索引创建后,其索引名为item_1_quantity_-1
db.products.createIndex( {item: 1, quantity:-1 } )
-- 可以指定自定义的索引名称
db.products.createIndex(
{ item: 1, quantity: -1 } ,
{ name: "inventory_idx" } )
db.test.ensureIndex(
{'page_id':1},
{"name":"page_id"},
{background:true})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "EPO.test"
},
{
"v" : 2,
"key" : {
"page_id" : 1
},
"name" : "page_id",
"ns" : "EPO.test"
}
]
大数据量创建索引导致锁库的解决方案
在MongoDB中,对于大数据量(百万、千万以及亿级别)的数据创建索引,执行 db.collection.ensureIndex({key:1}) 之后,打开另一个终端,任何操作都不能执行。
根本原因
- 在数据库建立索引时,默认是”foreground” 也就是前台建立索引,但是,当你的数据库数据量很大时,在建立索引的时会读取数据文件,大量的文件读写会阻止其他的操作,命令没有显性指定 background,所以命令会锁库。
解决方案
- 执行
db.collection.ensureIndex({key:1},{background: true}),这样就不会锁库了,建立索引就会在后台处理了。(注:”{key:1}” 中,1 表示升序 - asc,-1 表示降序 - desc ) - 在后台建立索引的时候,不能对建立索引的 collection 进行一些坏灭型的操作,如:运行 repairDatabase,drop,compat,当你在建立索引的时候运行这些操作的会报错。
Aggregation Operations 聚合
1
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
- MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
- 有点类似 SQL 语句中的 count(*)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
集合中的数据如下:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'runoob.com',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'runoob.com',
url: 'https://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'https://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
-- 计算每个作者所写的文章数
db.mycol.aggregate([{
$group : {
_id : "$by_user",
num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "runoob.com",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
-- 类似sql语句:
select by_user, count(*) from mycol group by by_user
-- $sum 计算总和。
db.mycol.aggregate([{
$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
-- $avg 计算平均值
db.mycol.aggregate([{
$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
-- $min 获取集合中所有文档对应值得最小值。
db.mycol.aggregate([{
$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
-- $max 获取集合中所有文档对应值得最大值。
db.mycol.aggregate([{
$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])
-- $push 将值加入一个数组中,不会判断是否有重复的值。
db.mycol.aggregate([{
$group : {_id : "$by_user", url : {$push: "$url"}}}])
-- $addToSet 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。
db.mycol.aggregate([{
$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])
-- $first 根据资源文档的排序获取第一个文档数据。
db.mycol.aggregate([{
$group : {_id : "$by_user", first_url : {$first : "$url"}}}])
-- $last 根据资源文档的排序获取最后一个文档数据
db.mycol.aggregate([{
$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
管道
- 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
- MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
- 表达式:处理输入文档并输出。
- 表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合框架中常用的几个操作:
$project:修改输入文档的结构。可以用来重命名. 增加或删除域,也可以用于创建计算结果以及嵌套文档。$match:用于过滤数据,只输出符合条件的文档。使用MongoDB的标准查询操作。$limit:用来限制MongoDB聚合管道返回的文档数。$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。$group:将集合中的文档分组,可用于统计结果。$sort:将输入文档排序后输出。$geoNear:输出接近某一地理位置的有序文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
-- 1. $project 实例
db.article.aggregate({
$project : {title : 1 ,author : 1 ,}});
-- 这样结果中就只还有_id,tilte和author三个字段
-- 默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
db.article.aggregate({
$project : {_id : 0 ,title : 1 ,author : 1}});
-- 2.$match实例
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
-- $match用于获取分数大于70小于或等于90记录,
-- 然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
-- 3.$skip实例
db.article.aggregate({ $skip : 5 });
-- 经过$skip管道操作符处理后,前五个文档被"过滤"掉。
Explain 效能分析工具
針對資料庫內的資料進行查詢、新增、刪修都需要迅速地找到該筆資料,因此建立索引很重要。至於要如何評估指令的效能如何,例如參數設計、順序,就需要使用 MongoDB 的 explain 指令,其他資料庫如 Oracle, MSSQL 叫做 execution plan。
既然加 index 可以加速 query,那是不是拼命幫各個欄位加 index 就好?也不是這樣,重點在於你加的 index 有沒有被 query planner 吃到。加了太多沒路用的 index 只不過是佔空間,而且還會拖慢寫入的速度。
透過 explain,你可以不斷檢驗 index 是不是真的適合你的應用,避免自己加了一堆「感覺有用」的 index,但其實只是多佔空間而已。
1
2
3
4
5
db.test.find({index_name:"a",systime:1600000001000000}).explain()
db.test.find({index_name:"a",systime:1600000001000000}).explain("executionStats")
db.test.find({index_name:"a",systime:1600000001000000}).explain("allPlansExecution")
如果想找到價錢 699 的商品,Mongo 會怎麼做搜尋:
- 沒 index 的情況下
- 方法很簡單,只要在 find({ price:699 }) 後面加上 explain() 就可以了
(跑出來會有一大串,我們先看其中的 queryPlanner.winningPlan)
stage = 'COLLSCAN',意思是這次 query 是把整個 collection 都找(scan)過一遍,可想而知效率一定非常的差。- 如果想看更詳細的執行情況的話,可以帶參數 explain(“executionStats”),就可以看到這次 query 的過程總共檢查了 1000 筆資料(就全部啦XD),最後符合條件的資料卻只有 1 筆,好像很可憐
- 加上 index
- 解決命中率只有千分之一的窘境呢,那就是加一個 { price: 1 } index,
建一個 index,讓他根據 price 從小排到大
- 有了 index 後馬上來看看 explain,果然從 COLLSCAN 變成
IXSCAN+FETCH了。 - 注意當有多個步驟(stage)時要從內層往外看,所以是先做 IXSCAN 再做 FETCH,意思是先從 price_1 index 中找到 699(Index Scan),再去把那些資料抓出來(Fetch)。因此我們剛新增的 price_1 是有幫助的。
1
db.coll.createIndex({ price: 1 })
選擇 query plan
Mongo 在多個 index 時,是怎麼選擇「他所認為的最佳的 query plain」
現在 price 跟 quantity 欄位上都有 index。如果我今天想要補庫存,要找「庫存量只剩一個,且價錢低於一萬的商品」,那怎麼使用 index 來找會最快呢?這邊有兩個方案:
- 方案一:
- 利用 quantity index 快速找到 quantity == 1 的那些商品(假設有 200 個好了)
- 再從 200 個中一個一個檢查,找出 price < 10000 的商品
- 方案二:
- 先利用 price index 快速找到 price < 10000 的商品(只是家五金行,一萬塊以下的商品會超多,所以假設有 800 個)
- 再從 800 個中一個一個檢查,找出 quantity == 1 的商品
比較一下,方案一光是第一步的 quantity == 1 就可以篩選掉不少資料,再從中找 price < 10000 應該很快,CPU 總共只需要做 200 多次比較;而方案二的第一步 price < 10000 可以篩選掉的資料很少,加上第二步可能要做 800 多次的比較。所以沒意外的話應該是方案一比較好
但這畢竟是我們人工判斷的結果,之所以能這樣判斷是因為我們知道這是一家五金行的資料. 也知道他的資料特性(一萬塊以下的商品會超多)。但對資料庫而言裡面就只是一堆資料,所以 MongoDB 自己有一套方法來選出最佳方案。
不知道哪個方法快?那就跑跑看吧!
- 對 MongoDB 而言,因為不知道裡面的資料長什麼樣子,所以他會直接把各個可能的 plan 都試跑一下,看哪個 plan 最先回傳 101 筆結果,就會被選出來當
winning plan - 用
explain("allPlansExecution")來看各個 plan 執行的狀況 - 可以看到當方案一(先用 quantity index)抓到前 101 筆資料時,方案二(先用 price index )才剛抓到 15 筆資料而已,所以正如我們預期的,方案一確實比方案二快上許多
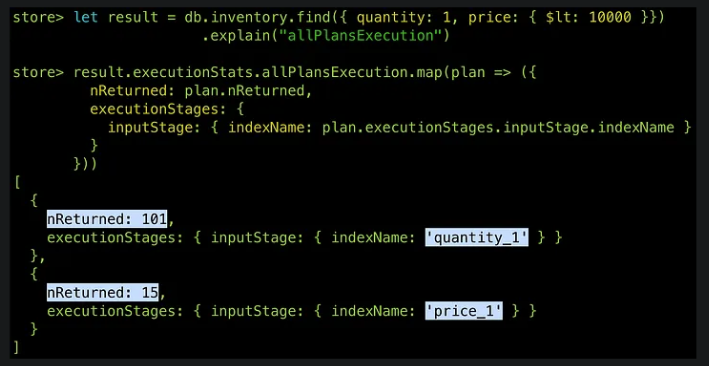
而 MongoDB 其實也不會每次都做方案之間的比較,他只要比過一次就會把結果 cache 起來,避免每次 query 都浪費在做一樣的事情。
所以如果你在 production 上加了 index 之後 MongoDB 沒有馬上使用新的 index,那也不代表他不好,只是可能要過個幾天才會被 MongoDB 用上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 命令行语句.explain("pattern")
db.test.find({index_name:"event_detail_abc",systime:1600000001000000}).explain("executionStats")
-- 聚合语句的explain大概这样:
db.test.aggregate([
{ $match: {
kfuin: 2885772560,
sa_list: { $in: [ "2_+8613266776354", "4_8643975168", "3_wxe232d626118f1acd_oDzMB5R1jrfOc3RXxVlXWcKXJNss", "7_12345@qq.com" ] },
sensor_event: "小程序启动",
time: { $gte: 1620252229000000.0 } }
},
{ $group: { _id: null, count: { $sum: 1 } } }
],{explain:true})
-- #或者explain放前面也行
db.collection.explain().aggregate()
強迫推銷 index
雖然 MongoDB 大部分情況下都會選擇最佳方案,但在極少數的情況下也可能會選錯。所以如果你加了一個你覺得「超級好用. 一定要用. 不用會出大事」的 index,但 MongoDB 卻遲遲沒有用上,那就可以用 hint(index) 來強迫推銷 MongoDB 一定要使用你的 index
以剛剛的例子來說,MongoDB 認為最佳方案是優先使用 quantity_1,跑出來的結果是:總共需要檢查 148 個 document 才能得到結果
但如果我覺得 price_1 才是真正對他好的 index,那就可以在 query 時加上 hint(“price_1”) 提醒(強迫)他用這個 index 來做搜尋,然後看看結果是不是跟你想的一樣好。
explain分析的案例
- 复合索引的顺序对于排序查询生效情况
- 前言:数据组成也非常重要。
- 如下, time_num 越大性能差异越明显, time_num 很小的时候性能差异几乎可以忽略。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
var coll_name = "coll"
var time_num = 100000
var name_num = 10
var docs =[]
for (var i = 1; i <= time_num ; i++){
for (var j = 1; j <= name_num ; j++){
var str_name = "name_" + (j).toString()
docs.push({name:str_name,time:(i)})
}
}
db.getCollection(coll_name).save(docs)
-- 创建如下索引:
db.coll.createIndex({name:1,time:-1})
-- 执行如下如何数据组织形式的查询语句:
db.coll.find(
{name:"name_5"}).sort({name:1,age:-1}).limit(3).explain("executionStats")
db.coll.find(
{name:"name_5"}).sort({name:-1,age:1}).limit(3).explain("executionStats")
-- 执行不符合属于组织形式的查询:
db.coll.find(
{name:"name_5"}).sort({name:1,age:1}).limit(3).explain("executionStats")
- 设置与不设置分片的explain分析
- 在shell命令行贴上如下语句;然后分别往test集合和testunshard集合分别插入如下数据。
- 对于前者对test集合设置分片;但是却不对testunshard开启分片。
- 注意:对于test集合以 kfuin 为分片键。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
var msg_num = 500000;
var index_num = 1000;
var coll_name = "collection1"
var docs = [];
for (var i = 1; i < msg_num; i++){
var index_name_val = "event_detail_2852199351_wx58b4690f0ab8193f_" + (i%index_num).toString()
docs.push({kfuin:2852119999,index_name:index_name_val,systime:(1600000000000000 + 1000000 * i)})
}
-- 向test集合插入50万条数据
db.test.save(docs)
db.test.count()
-- 向testunshard集合插入同样的50万条数据
db.testunshard.save(docs)
db.testunshard.count()
验证一:对于 分片集群 的查询操作带与不带 分片键 的效果。 结论:
- 对于分片集群执行查询操作的时候带上分片键字段mongos会将请求直接路由到对应分片;
- 如果不带分片字段则请求会扩散到每个分片。完全符合预期
- 分片键字段只要带上就好,测试发现对出现顺序是没要求的。
对一个分片集群执行查询操作时带上分片键字段(kfuin) 效果:请求只打到目标分片上去
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- (1)查询时不带分片键:
db.test.find(
{
index_name:"event_detail_abc",
systime:1600000001000000
}
).explain("executionStats")
-- (2)查询时带分片键字段
db.test.find(
{
kfuin:2852119999,
index_name:"event_detail_abc",
systime:1600000001000000
}
).explain("executionStats")
验证二:带不带 分片键 对查询效率的影响(注:此处是对kfuin进行的hash分片)。
- 同样上面的两张截图。可以看到对于不带分片键的查询只需要292ms,带上分片键后却需要830毫秒。
- 细查发现对于前者仅仅执行50万次totalDocsExamined,执行0次totalKeysExamined;
- 但是后者则全部都执行了50万次。其中”IXSCAN”阶段耗费了不少时间的,而且可以看到优化选择器是选择了为了创建hash分片而设的那个hash索引。
如果本分片有更多主号的数据是不是就能体现出效果了呢?
- 试一下。为此将kfuin字段换成28521998 继续插入50万条。
- 注:通过db.stats()验证过kfuin为此数值时数据正好位于分片0上了的。
- 此时前者耗时476ms,其中totalDocsExamined为100万,totalKeysExamined为0;
- 后者耗时为788ms,其中totalDocsExamined和totalKeysExamined依然是50万。
结论:
- 现在在实际场景下一个分片中应该是有N多个主号的数据每个主号下有M条数据;
- 对于不带分片键的查询来说其需要遍历所有
N*M条数据,而带了分片键(即使只是hash分片)的请求来说则可以将扫描的数据量将至2*M(综合totalDocsExamined和totalKeysExamined)。所以这里结论就很显然了。 - 对于hash分片,带分片键能显著提高性能。
注意:如果再考虑实际情况另外两个分片依然也有很多数据的情况就知道不带分片键的效果会更差。两点:
- ①另外两个分片的数据量如果大于当前分片则进度会被数据量最大的那个分片拖后腿
- ②梁歪两个分片去做这种无用功会影响集群整体的吞吐量。
问题:有没有更好的方式来提升整体性能呢? 分析:对于带有分片键的查询我们发现命中的”kfuin_hashed”这个索引;前面分析过了,这是合理的。不过针对我们的业务场景我们可以尝试建立针对性的索引,例如再建一个{kfuin:1,index_name:1}的复合索引。
1
db.test.createIndex({kfuin:1,index_name:1})
然后我们再执行查询。发现: ①不带分片键的查询耗时472ms,其中totalDocsExamined为100万,totalKeysExamined为0;仔细观察没有命中任何索引。 ②带分片键的查询:”executionTimeMillis” : 5, “totalKeysExamined” : 500, “totalDocsExamined” : 500,显然有了质的飞跃;再仔细观察发现其命中了新建的复合索引,堪称完美。
验证三:查询字段顺序 是否与 (复合)索引字段顺序 一致会影响索引的命中吗?
- 验证方法很简单。执行下面两条指令对比效果。 结论:
- 测试下来是没有影响的。
- 经过观察explain在IXSCAN阶段的输出可以看到其依然能匹配到我们上面创建的复合索引。
- mongos完全可以针对你的这种情况匹配到对应索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
db.test.find(
{
index_name:"event_detail_abc",
kfuin:2852119999,
systime:1600000001000000
}
).explain("executionStats")
db.test.find(
{
kfuin:2852119999,
index_name:"event_detail_abc",
systime:1600000001000000
}
).explain("executionStats")
验证四:如果仅有复合索引的后缀字段(无前缀字段)还能命中目标复合索引吗?
结论:
- 仅有 index_name 字段的情况下就不会命中
{kfuin:1,index_name:1}这个复合索引,其查询测试又退化到单纯的集合扫描了。
1
2
3
4
5
6
7
8
9
db.test.find(
{
index_name:"event_detail_abc",
systime:1600000001000000
}
).explain("executionStats")
-- "executionTimeMillis" : 475,
-- "totalKeysExamined" : 0,
-- "totalDocsExamined" : 1000001。
验证五:仅有kfuin前缀字段会命中{kfuin:1,index_name:1}复合索引吗? 答:
- 经过验证可以命中这个复合索引,而且请求也只是打到分片0。
- 但是因为测试数据的原因,耗时显得有些太长了。
1
2
3
4
5
6
7
8
db.test.find(
{
kfuin:2852119999, systime:1600000001000000
}
).explain("executionStats")
-- "executionTimeMillis" : 1603,
-- "totalKeysExamined" : 499999,
-- "totalDocsExamined" : 499999。
验证六:有必要验证下是否对被用于范围查询的字段建索引对性能的影响 结论:
- 肯定是有用的啦!
- 对于经常被用于比较操作
(gt/lt)的字段(一般字段值及其分散)建立索引也是有用的,能极大的提升查找效率。
- 首先验证下对单个范围字段 systime 在
$gt/$lt操作下的性能情况。建立索引会如何?- 这里实际上又分为两种情况,一种是不指定排序, 一种是指定排序(sort)。两者完全不一样。
注:上述测试数据systime字段的取值为
1600000000000000~1600500000000000- 不指定排序
- 速度非常的快,文档遍历数和索引遍历数都非常的少。
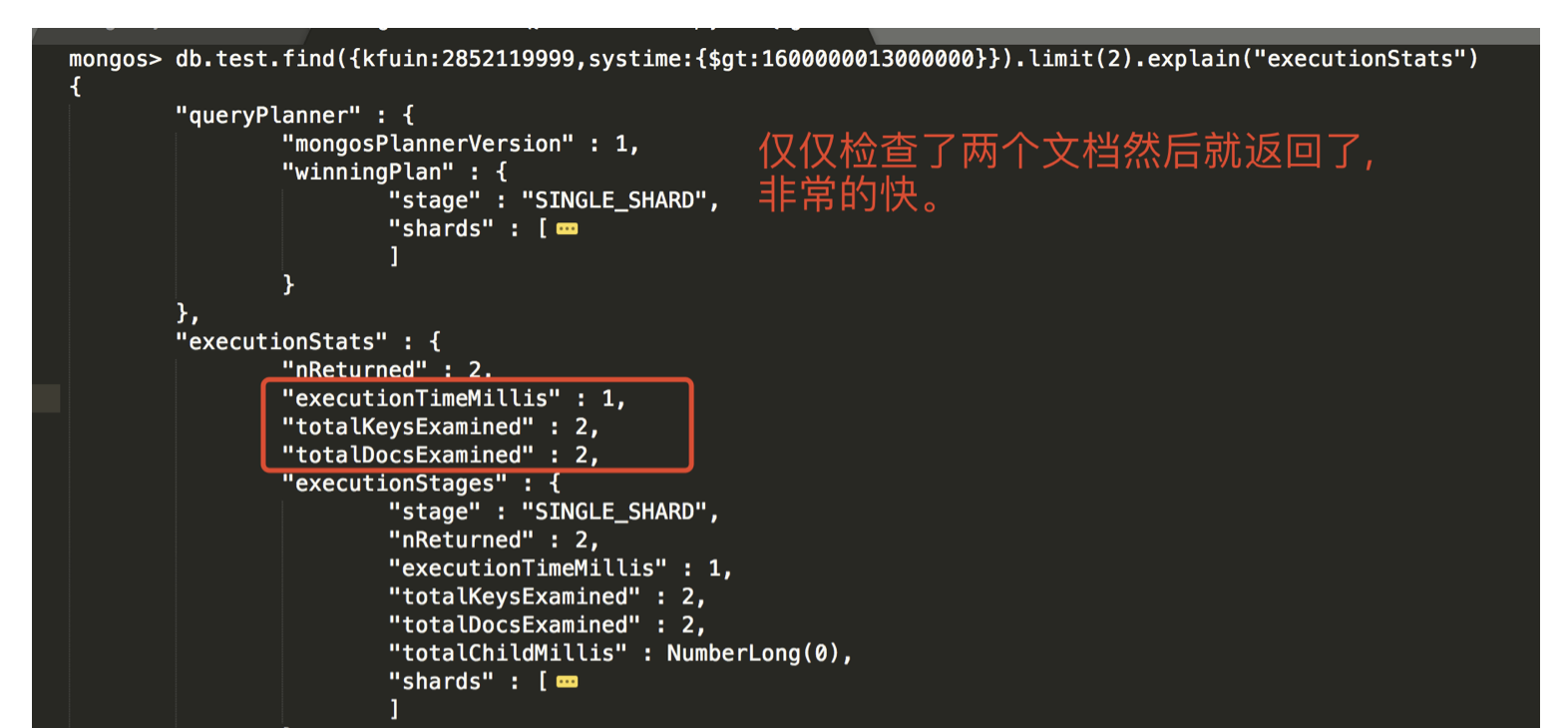
- 请注意 在没有执行排序的情况下其语义是:”找到任意两条systime大于 1600000013000000 的即可;注意是任意两条是否最紧挨着比较数值都不关心。” 显然这不是我们想要的!!!
- 因此这情况并不是我们实际应用的场景。留在这里是给大家提个醒,即”指定排序和不指定排序完全是两个不同的概念”。
1 2 3 4 5 6 7
-- 不指定排序 db.test.find( { kfuin:2852119999, systime:{$gt:1600000013000000} } ).limit(2).explain("executionStats")
- 指定排序
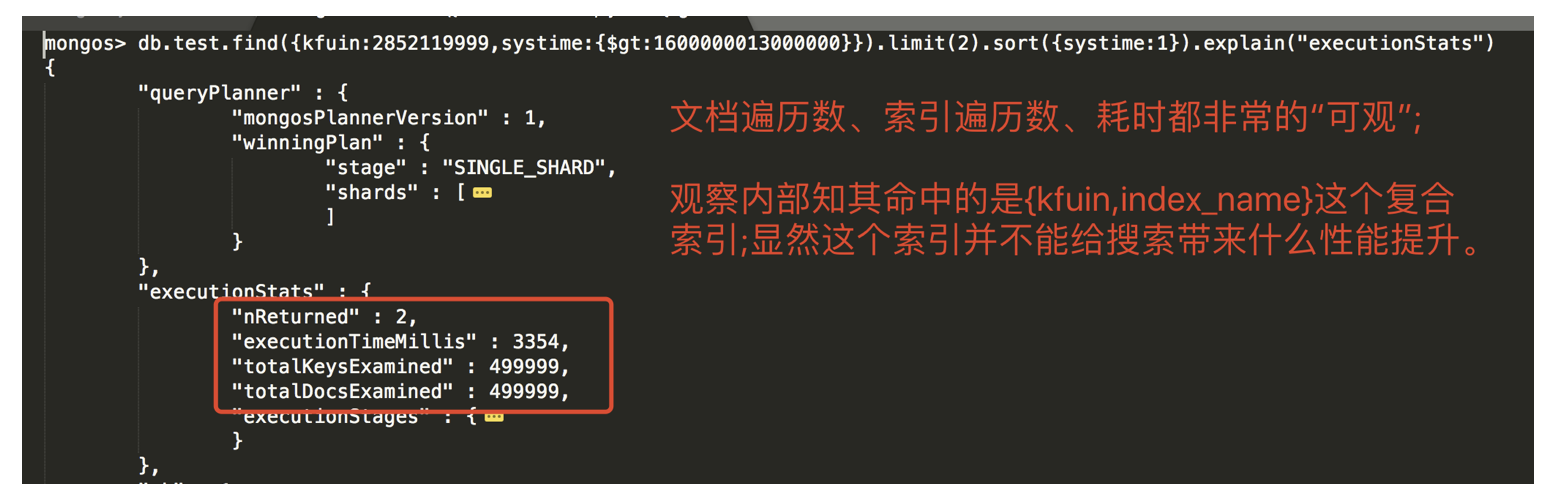
- 查询指令如下。这个时候的语义是:”查询大于1600000013000000的数据按照升序排列然后取前两条(即我们期望的是返回systime为1600000014000000/1600000015000000的两条数据,而不是随便大于比较数值的两条)。”
- 果然查询速度感官可见的慢了好多个数量级。见上右图。
1 2 3 4 5 6 7
-- 指定排序 db.test.find( { kfuin:2852119999, systime:{$gt:1600000013000000} } ).limit(2).sort({systime:1}).explain("executionStats")
- 对systime建立一个单字段的索引
- 然后再执行上面一样的带有排序的查询语句。肉眼可见的快。
```sql – 单字段的索引 – //对systime字段建立单字段索引 db.test.createIndex({systime:1}) db.test.getIndexes()
db.test.find( { kfuin:2852119999, systime:{$gt:1600000013000000} } ).limit(2).sort({systime:1}).explain(“executionStats”) ```
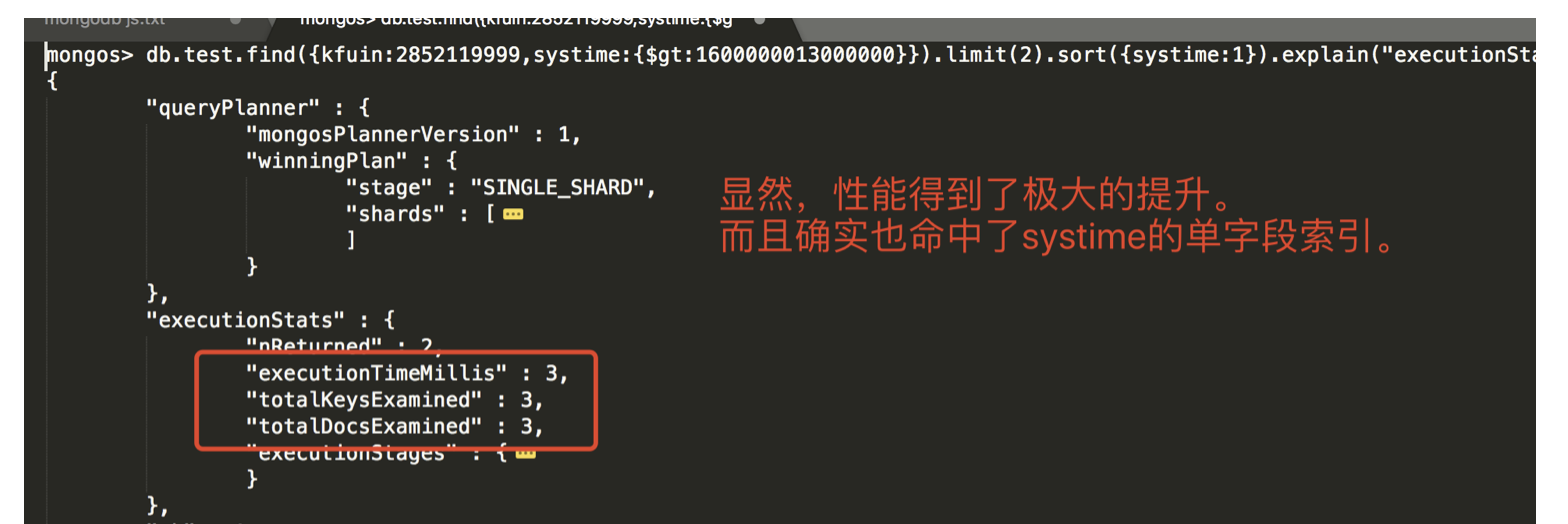
- 用一个能命中
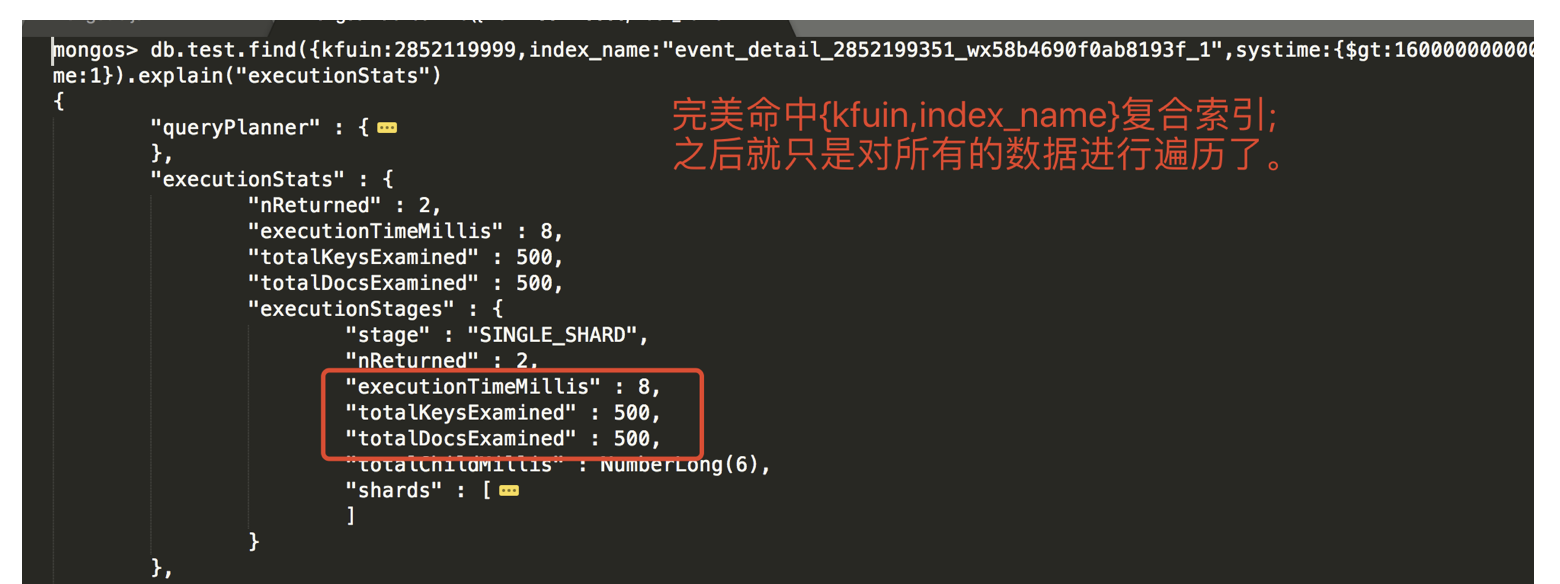
{kfuin,index_name}这个复合索引的查询语句,同时也带上对 systime 的比较操作。看看能不能同时命中复合索引和systime字段的单字段索引。- 查询语句如下。见下图,从结果上看只是命中
了{kfuin,index_name}这个复合索引,并没有说同时命中两个索引。(这里猜测:一次请求最多只能命中一个索引)。 - 文档扫描数为500恰好是满足{kfuin,index_name}后的所有记录条数(500000/1000=500),也就是说{kfuin,index_name}复合索引生效后将范围缩小至500条数据,然后mongo遍历了所有的这500条数据。
- 结论:
- 就测试来看不会说完美命中复合索引后,对缩小范围后数据再命中systime单字段索引的说法。
- 也就是说如果想进一步提升性能的话可能需要建立{kfuin,index_name,systime}三字段的复合索引,而不是{kfuin,index_name}两字段复合索引+systime单字段索引。
1 2 3 4 5 6 7
db.test.find( { kfuin:2852119999, index_name:"event_detail_abc", systime:{$gt:1600000000000000} } ).limit(2).sort({systime:1}).explain("executionStats")
- 查询语句如下。见下图,从结果上看只是命中
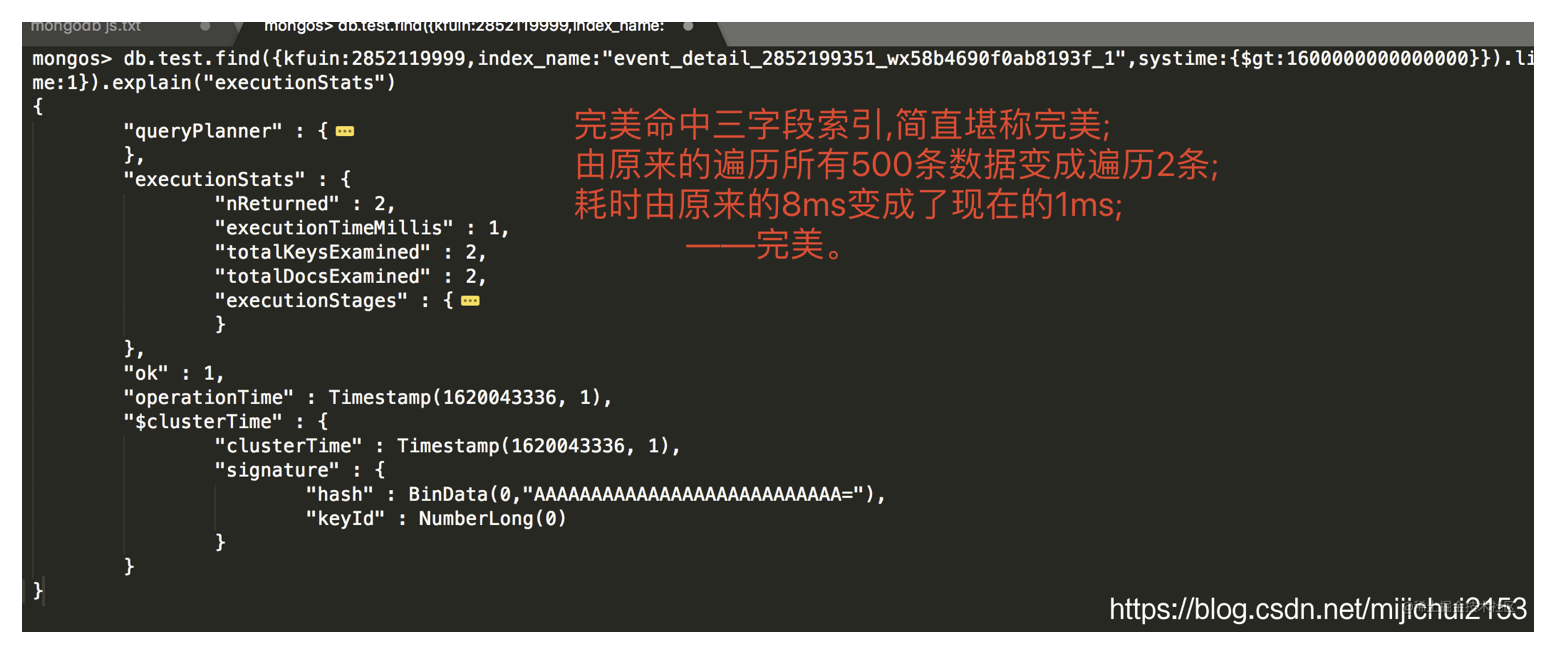
- 验证下
{kfuin:1, index_name:1, systime:1}三字段索引是不是能进一步提升性能。- 结论:
- 对于经常被用于比较操作(gt/lt)的字段(一般字段值及其分散)建立索引同样能极大的提升效率;
- 不要想着mongo会智能到帮你命中一个复合索引后再命中一个单字段索引,这只是你的一厢情愿。建立与查询语句全字段匹配的索引能更进一步的提升查询效率。
- ```sql – //首先将systime的单字段索引, {kfuin:1,index_name:1}的双字段复合索引 删了 db.test.dropIndex(“systime_1”) db.test.dropIndex(“kfuin_1_index_name_1”)
– //然后建立
{kfuin:1, index_name:1, systime:1}的三字段复合索引 db.test.createIndex({kfuin:1, index_name:1, systime:1}) db.test.getIndexes()– 重复执行1.4的操作,效果如下:
db.test.find( { kfuin:2852119999, index_name:”event_detail_abc”, systime:{$gt:1600000000000000} } ).limit(2).sort({systime:1}).explain(“executionStats”) ```
- 结论:
- 不指定排序
验证七:在上述查询语句的基础上新增一个session_id字段的匹配会怎样?
- 首先看下我们选中用来测试的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
db.test.find({kfuin:2852119999,index_name:"event_detail_abc"}).count()
500
db.test.find({kfuin:2852119999,index_name:"event_detail_abc"})
-- //数据如下:
{ "_id" : ObjectId("6075858edc709741eac38ce7"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600000001000000 }
{ "_id" : ObjectId("60758592dc709741eac390cf"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600001001000000 }
{ "_id" : ObjectId("60758597dc709741eac394b7"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600002001000000 }
{ "_id" : ObjectId("6075859cdc709741eac3989f"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600003001000000 }
{ "_id" : ObjectId("607585a1dc709741eac39c87"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600004001000000 }
{ "_id" : ObjectId("607585a5dc709741eac3a06f"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600005001000000 }
{ "_id" : ObjectId("607585aadc709741eac3a457"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600006001000000 }
{ "_id" : ObjectId("607585afdc709741eac3a83f"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600007001000000 }
{ "_id" : ObjectId("607585b3dc709741eac3ac27"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600008001000000 }
- 保持不设置 session_id 字段看看执行效果
1
2
3
4
-- #注意session_id字段的前后顺序对查询没有任何影响
db.test.find(
{kfuin:2852119999,index_name:"event_detail_abc",session_id:"session_id",systime:{$gt:1600000000000000}}
).limit(2).sort({systime:1}).explain("executionStats")
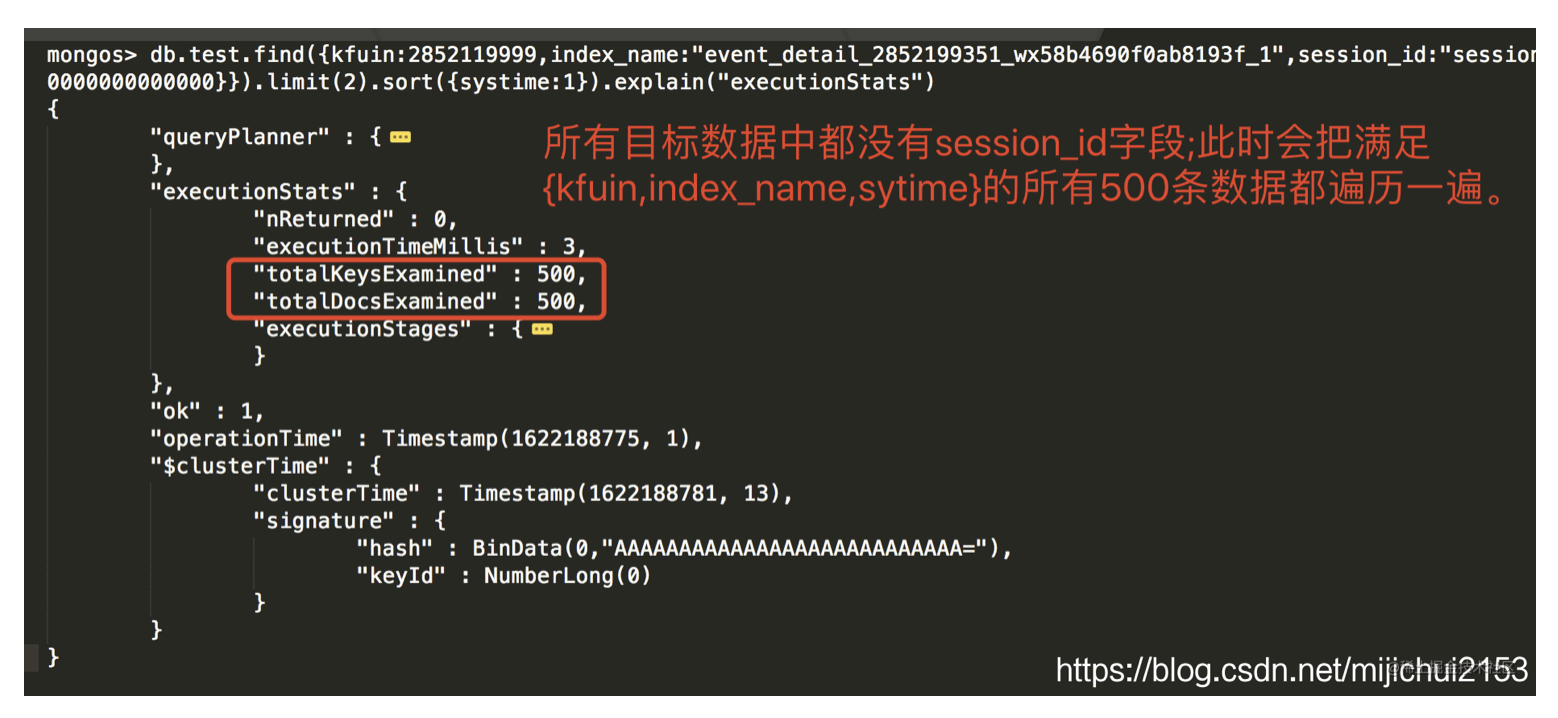
- 我们给其中的第5. 6条数据设置 session_id 字段使之满足session_id的匹配条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
-- #给第五条数据设置session_id字段
-- #给第六条数据设置session_id字段
db.test.update({kfuin:2852119999,index_name:"event_detail_abc","systime":1600004001000000},{$set:{session_id:"session_id"}})
db.test.update({kfuin:2852119999,index_name:"event_detail_abc","systime":1600005001000000},{$set:{session_id:"session_id"}})
-- #此时数据如下:
db.test.find({kfuin:2852119999,index_name:"event_detail_abc"})
{ "_id" : ObjectId("6075858edc709741eac38ce7"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600000001000000 }
{ "_id" : ObjectId("60758592dc709741eac390cf"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600001001000000 }
{ "_id" : ObjectId("60758597dc709741eac394b7"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600002001000000 }
{ "_id" : ObjectId("6075859cdc709741eac3989f"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600003001000000 }
{ "_id" : ObjectId("607585a1dc709741eac39c87"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600004001000000, "session_id" : "session_id" }
{ "_id" : ObjectId("607585a5dc709741eac3a06f"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600005001000000, "session_id" : "session_id" }
{ "_id" : ObjectId("607585aadc709741eac3a457"), "kfuin" : 2852119999, "index_name" : "event_detail_abc", "systime" : 1600006001000000 }
-- 此时执行上述查询语句
db.test.find(
{
kfuin:2852119999,
index_name:"event_detail_abc",
session_id:"session_id",
systime:{$gt:1600000000000000}
}
).limit(2).sort({systime:1}).explain("executionStats")
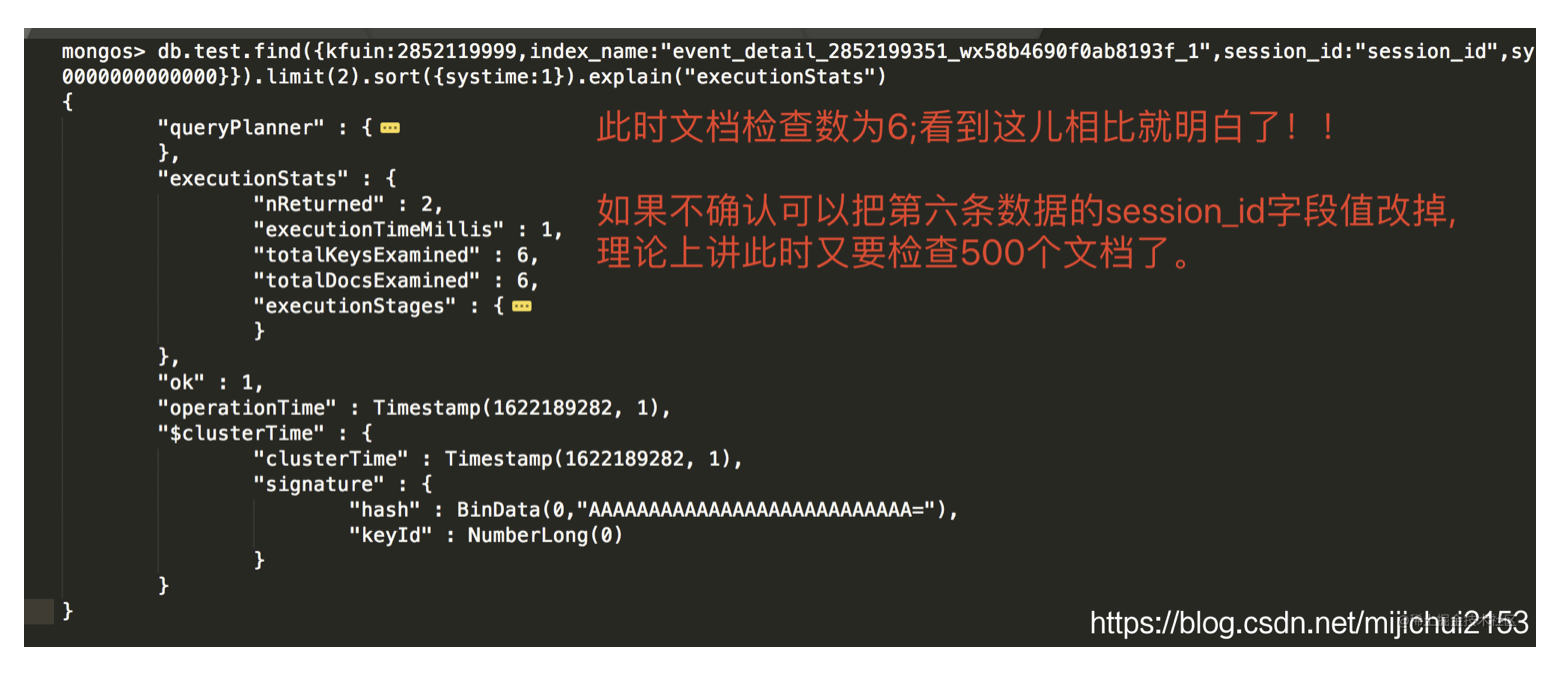
总结:
- 这里想捞取的数据条件是
{ kfuin:2852119999, index_name:"event_detail_abc", session_id:"session_id", systime:{$gt:1600000000000000}}.limit(2).sort(systime:1); - 翻译过来就是满足
- kfuin, index_name 固定值.
- session_id 也固定值
- systime 大于某值.
- 两条数据,且是 systime 从小打到排序的前两条。
- ①根据explain可知该请求命中了
{kfuin:1, index_name:1, systime:1}这个复合索引; - ②即查询条件中新增
session_id字段并不会影响命中该复合索引 - ③不考虑 session_id 字段,满足上述条件的数据有500条
- ④考虑到又要匹配 session_id 的值,mongo就会对于
{kfuin:1, index_name:1, systime:1}索引得到的500条数据(注意:这500条数据是从小到大严格有序的)依次匹配session_id值; - 如果提前匹配到了就提前返回,直至遍历完这个500条数据。至此,就一目了然了。
继续分析:
- 对于包含session_id的查询场景复合索引
{kfuin:1, index_name:1, systime:1}满足高效搜索的要求吗?如果不满足的话要怎么办?? - 先说一下这个问题的背景。目前对于所存的数据可能会有两种查询方式。
- 查询一:指定(kfuin,index_name,systime)来查询;
- 查询二:指定(kfuin,index_name,session_id,systime)来查询。
注意:对于索引字段,出现的前后顺序非常重要;对于查询语句则不关心。
- 保持现状会怎样?经过前面的分析我们知道仅依赖
{kfuin:1, index_name:1, systime:1}三字段索引的话实际上会对满足这个三个条件的所有数据(n)进行遍历,虽然说有可能提前找到满足条件的数据,但其期望复杂度依然是O(n)。至此。结论一:三字段索引不能满足需求。
优化索引的话要如何优化?
- 根据目前情况来看可以建立一个四字段复合索引,如下为systime和session_id字段个不相同时的测试结果。
显然我么想要2. 3的效果,但这需要建立两个索引。
序号, 索引, 查询, 效果:
1, 仅
{kfuin:1,index_name:1,systime:1,session_id:1}, 带session_id文档检查数为1,索引检查数为501,耗时3ms。2, 仅
{kfuin:1,index_name:1,systime:1,session_id:1}, 不带session_id索引检查数为2,文档检查数为2,耗时0ms。3, 仅
{kfuin:1,index_name:1,session_id:1,systime:1}, 带session_id文档检查数为1,索引检查数为1,耗时1ms。4, 仅
{kfuin:1,index_name:1,session_id:1,systime:1}, 不带session_id索引检查数为501,文档检查数为500,耗时1ms。
验证八. 消息记录存储索引验证
关于消息记录存储其模型如下,
sacc 字典序较小的社交号 bacc 字典序较大的社交号 time chan??? msg day
该模型无非支持三类查询
- ①某账号对的消息记录拉取
- ②某账号对的日历卡拉取
- ③某账号对特定类型消息的查询。
分别对应如下三个索引:
1
2
3
{sacc:1,bacc:1,time:1} #应对所有账号对的拉取
{sacc:1,bacc:1,day:1} #日历卡拉取(可有可无)
{sacc:1,bacc:1,sort:1,time:1} #应对账号对的图片筛选
现在面临的挑战是
- qd业务场景中有主号通路和工号通路的消息,这两个通路的消息最终都落在两个qq号上;
- 但是企点的业务却要对这两个通路做区分。即有时候是只拉取主号通路的消息,有时候又只拉取工号通路的消息。
- 与此同时,也还要求能支持账号对对主. 工号通路消息的完整拉取。
- 这意味着要引入chan字段了。
- 验证点
{sacc:1,bacc:1,chan:1,time:1}索引对find{sacc:"",bacc:"",time:{"$gt":123456}}.sort({time:1})是否完美生效。- 分析: 对于上述查询语句
{sacc:1,bacc:1,time:1}索引肯定是能完美生效的; - 我们就验证有chan的这个索引是否也能完美起作用。
- 造数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/*
数据集如下:
account1有account1_num个取值,范围为(2852000000 ~ 2852000000+account1_num);
account2有account2_num个取值,范围为(726045513175435_{0~account2_num});
每个账号对有 couple_acc_msg_num 条消息;消息时间为 1600000000 开始没10秒发送一条;
对于每个账号对的 couple_acc_msg_num 条消息间隔性的氛围三份;一份chan为1. 一份chan为2. 一份无chan;
每个账号对的时间范围为1600000000没10秒一条,持续发couple_acc_msg_num条
注:对于下述场景消息时间范围为 1600000000~1600300000(1600000000+30000*10)
*/
account1_beg = 2852000000
account1_num = 10
account2_prefix = "726045513175435"
account2_num = 10
couple_acc_msg_num = 30000
for (var acc1 = account1_beg; acc1 < account1_beg+account1_num; acc1++){
var docs = [];
for (var acc2_index = 0; acc2_index < account2_num; acc2_index++){
account1 = acc1.toString();
account2 = account2_prefix + "_" + acc2_index.toString()
for (var msg_num = 0; msg_num < couple_acc_msg_num; msg_num ++){
var time_sec = 1600000000 + msg_num*10
if (msg_num % 3 == 0){
docs.push({sacc:account1,bacc:account2,chan:1,time:time_sec})
}else if(msg_num %3 == 1){
docs.push({sacc:account1,bacc:account2,chan:2,time:time_sec})
}else{
docs.push({sacc:account1,bacc:account2,time:time_sec})
}
}
}
db.coll2.save(docs)
print("finish ",account1)
}
case1:没有索引 —— 遍历全部300万条数据
1
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")
case2:建立{sacc:1,bacc:1,chan:1,time:1}索引
1
2
db.coll2.createIndex({sacc:1,bacc:1,chan:1,time:1})
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")
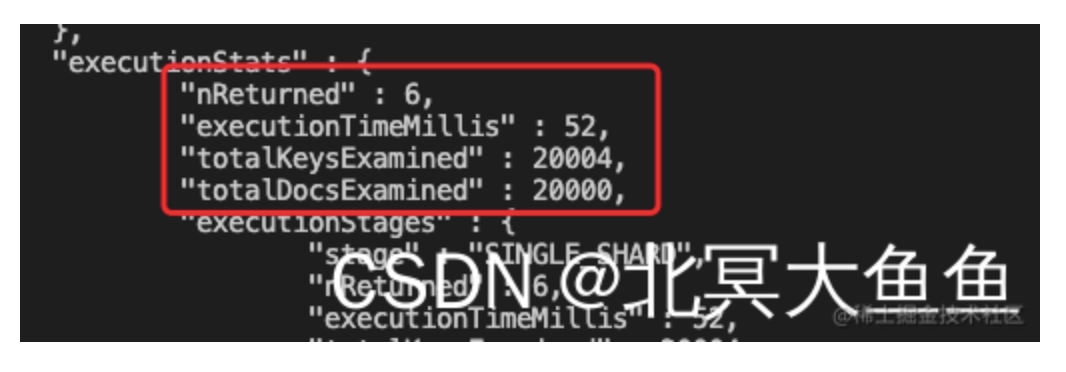
case3:建立{sacc:1,bacc:1,time:1}索引 注:在上述两个索引都存在的情况下果断命中 {sacc:1,bacc:1,time:1};达到最理想效果。
1
2
db.coll2.createIndex({sacc:1,bacc:1,time:1})
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")
case4:移除前面索引,建立{sacc:1,bacc:1,time:1,chan:1}索引
1
2
3
4
5
6
db.coll2.dropIndex("sacc_1_bacc_1_time_1")
db.coll2.dropIndex("sacc_1_bacc_1_chan_1_time_1")
db.coll2.createIndex({sacc:1,bacc:1,time:1,chan:1})
-- #显然对于如下查询效率非常高 2ms 6 6
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")
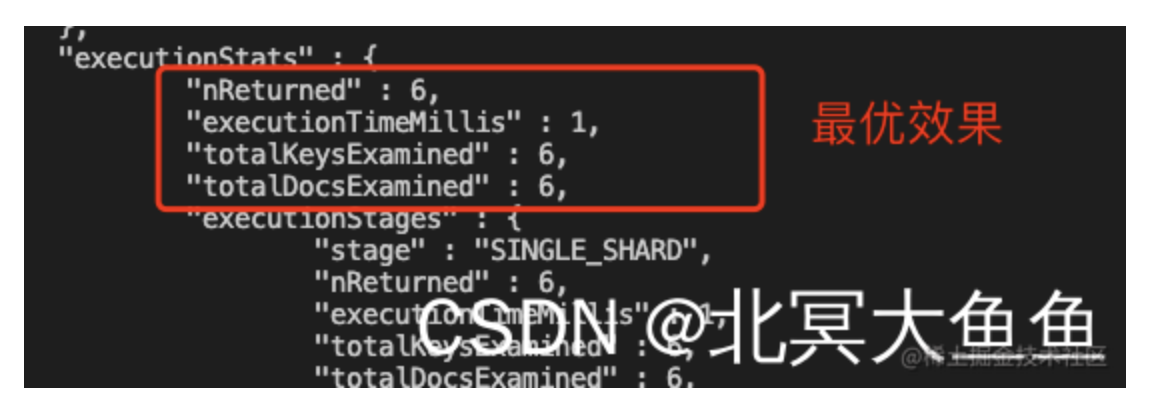
case5: 和case4索引保持一致,验证过滤条件包括chan的效果
1
2
-- #再看看指定chan字段的查询如何 1ms 18 6
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",chan:1,time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")

case6:case5的索引和仅有{sacc:1,bacc:1,time:1}效果应该差不多吧—— 多一个chan还是有作用的。
1
2
3
db.coll2.dropIndex("sacc_1_bacc_1_time_1_chan_1")
db.coll2.createIndex({sacc:1,bacc:1,time:1})
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",chan:1,time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")
效果如下。就测试结果来看还是有点区别的。多一个chan字段至少能在降低DocsExamined上有作用。
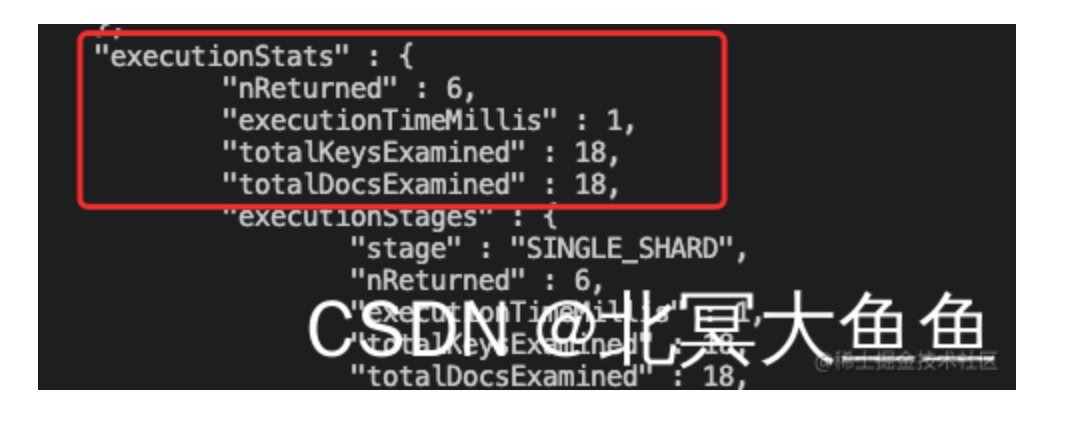
3.结论 经测试由于主. 工号通路情况的存在,不得不对三种场景都再额外建立一个包含chan字段的索引。索引数由三个变成了六个。注:这个是最完善的索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{sacc:1,bacc:1,time:1} #应对所有账号对的拉取
{sacc:1,bacc:1,day:1} #日历卡拉取(可有可无)
{sacc:1,bacc:1,sort:1,time:1} #应对账号对的图片筛选
{sacc:1,bacc:1,chan:1,time:1} #用于区分通路,主要是为了区分主. 工号通路
{sacc:1,bacc:1,chan:1,day:1} #用于区分主工号通路的日历卡拉取(可有可无)
{sacc:1,bacc:1,chan:1,sort:1,time:1} #用于区分主. 工号通路的图片筛选
-- 再额外加一个查找单条数据和保证幂等性的索引,如下:
{sacc:1,bacc:1,subkey:1} ,{unique:true} #单条数据查找和幂等性保证
-- 另外还要有一个片键索引,如下:
{sacc:1, bacc: "hashed"} #片键索引
-- 分析:关于日历的索引是可以不要的。因为这种场景可以通过time字段限定时间范围(例如就一个月),即使性能没有达到最优,但整体遍历的数据是可控的。最终经过权衡取舍,保留如下6个索引:
{sacc:1, bacc: "hashed"} #片键索引
{sacc:1,bacc:1,time:1} #应对所有账号对的拉取
{sacc:1,bacc:1,sort:1,time:1} #应对账号对的图片筛选
{sacc:1,bacc:1,chan:1,time:1} #用于区分通路,主要是为了区分主. 工号通路
{sacc:1,bacc:1,chan:1,sort:1,time:1} #用于区分主. 工号通路的图片筛选
{sacc:1,bacc:1,subkey:1} ,{unique:true} #单条数据查找和幂等性保证
继续造数据:这里造了单表过亿的数据。详细分布为:100个主号,每个主号100万条数据;100万条数据里面有1万个cid,每个cid有10通会话,每通会话里面有9条消息。 脚本如下,插入一个主号的100万数据后立马把docs清空,然后再插下一个主号就可以避免kill了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
kfuin_beg = 0
kfuin_end = 100
for(var num = kfuin_beg; num < kfuin_end; num++){
var kfuin_num = num+1;//主号数
var cid_num = 10000 //1万个cid
var session_num = 10//每个cid有10通会话
var detail_num = 9//每个session有9条消息
var docs = [];
for(var i = num; i < kfuin_num; i++){
for(var j = 0; j < cid_num; j++){
for(var k = 0; k < session_num; k++){
var kfuin_val = i + 2852000000
var session_index_name_val = "event_session_" + kfuin_val.toString() + "_wx58b4690f0ab8193f-" + j.toString()
var session_id_val = "session_id" + "_wx58b4690f0ab8193f-" + j.toString() + "_" +(k).toString()
var systime_val = 1600000000000000 + k*1000
docs.push({kfuin:kfuin_val,index_name:session_index_name_val,session_id:session_id_val,systime:systime_val})
for(var h = 0; h < detail_num; h++){
var detail_index_val = "event_detail_" + kfuin_val.toString() + "_wx58b4690f0ab8193f-" + j.toString()
systime_val = 1600000000000000 + k*1000 + h
docs.push({kfuin:kfuin_val,index_name:detail_index_val,session_id:session_id_val,systime:systime_val})
}
}
}
}
db.coll1.save(docs)
}
目前插入1kw条数据,[0,9)。好像得设完分片再插数据,否则不太行。查询语句主要有一下几个:
1
2
3
4
5
6
7
8
//1.拉取一级节点
db.coll1.find({kfuin:2852000000,index_name:"event_session_2852000000_wx58b4690f0ab8193f-0",systime:{$gt:1600000000004000}}).sort({systime:1}).limit(3).explain("executionStats")
//2.根据time拉取二级节点
db.coll1.find({kfuin:2852000000,index_name:"event_detail_2852000000_wx58b4690f0ab8193f-0",systime:{$gt:1600000000004000}}).sort({systime:1}).limit(3).explain("executionStats")
//3.根据session_id和time拉取二级节点
db.coll1.find({kfuin:2852000000,index_name:"event_detail_2852000000_wx58b4690f0ab8193f-0",session_id:"session_id_wx58b4690f0ab8193f-0_7",systime:{$gt:1600000000007004}}).sort({systime:1}).limit(3).explain("executionStats")
可以比较下建立如下索引前后的执行效率,非常有效:
1
2
db.coll1.createIndex({kfuin:1,index_name:1,session_id:1,systime:1})
db.coll1.createIndex(`{kfuin:1, index_name:1, systime:1}`)
deduplicate
group
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
db.test_backup_.aggregate([
{ $sort: { A: -1 } },
{
$group: {
_id: {
A: "$A",
B: "$B"
},
doc: {
$first:
{
A: "$A",
B: "$B",
C: "$C"
}
}
}
},
{ $out: "test" }
], { allowDiskUse: true } )
db.col.aggregate([
{ $group: {
_id: "$name",
doc: { $first: "$$ROOT" }
}},
{ $replaceRoot: { newRoot: "$doc" } }
])
db.col.aggregate([
{ $sort: { last_evaluation: -1 } },
{
$group: {
_id: {
resource: "$resource",
rule: "$rule" },
doc: { $first: "$$ROOT" }
}
},
{ $out: "col" }
], { allowDiskUse: true } )
index
Use Update with upsert=true.
- Update will look for the document that matches the input query,
- then it will modify the fields you want and then,
- you can tell it
upsert:Trueif you want to insert if no document matches the query.
1
2
3
4
5
6
7
8
9
10
11
12
# { _id:'...', user: 'A', title: 'Physics', Bank: 'Bank_A' }
# { _id:'...', user: 'A', title: 'Chemistry', Bank: 'Bank_B' }
# { _id:'...', user: 'B', title: 'Chemistry', Bank: 'Bank_A' }
doc = { user: 'B', title: 'Chemistry', Bank:'Bank_A' }
db.collection.insert(doc)
here, this duplicate doc will get inserted in database.
# { _id:'...', user: 'A', title: 'Physics', Bank: 'Bank_A' }
# { _id:'...', user: 'A', title: 'Chemistry', Bank: 'Bank_B' }
# { _id:'...', user: 'B', title: 'Chemistry', Bank: 'Bank_A' }
# { _id:'...', user: 'B', title: 'Chemistry', Bank: 'Bank_A' }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 1
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
db.collection.update(doc, doc, {upsert:true})
# 2
db.collection.createIndex(
{user: 1, title: 1, Bank: 1},
{unique:true}
)
# 3
# bulk insert and simultaneously prevent duplicates.
documents = [{'_id':'hello'}, {'_id':'world'}, {'_id':'hello'}]
collection.insert_many(documents, ordered=False)
# if ordered=True then mongo will stop attempting to insert if it encounters an duplicate _id.
# If ordered=False, mongo will attempt to insert all documents.
# 4
{
'index': '1',
'movie_name': '霸王别姬',
'pic': 'https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c',
'release': '上映时间:1993-01-01',
'score': '9.5'
}
# 那么应该把这条数据作为查询语句,然后执行collection.update_one(query,{'$set':query},upsert=True)。
query={
'_id': ObjectId('5d23fc92c2a80d7e578a2ae2'),
'index': '1',
'movie_name': '霸王别姬',
'pic': 'https://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', 'release': '上映时间:1993-01-01',
'score': '9.5'
}
collection.update_one(query,{'$set':query},upsert=True)
重复数据,指的是某些字段是相同的文档重复插入。也就是说在一个集合里面,某些字段有重复值。
没有并发的环境
- 先查询相关字段,如果查询到,就更新,如果没有查询到就插入。
1
2
3
4
5
6
7
8
9
10
filter={
'_id': 'lkj',
'index': '1',
'movie_name': '霸王别姬',
}
if db.collection.find(filter).count() == 0:
db.collection.insert_one(document)
else:
# 重置更新abbs字段
db.collection.update_one(filter, update)
- 使用update_one()
- 将参数upsert设置为true, 会查找有没有匹配的文档,有的话就更新,没有的话就插入。
- 如果upsert为默认值false时,如果没有找到匹配的文档,并不会执行插入。
1
2
3
4
5
6
filter={
'_id': 'lkj',
'index': '1',
'movie_name': '霸王别姬',
}
db.collection.update_one(filter, update, upsert=true)
但是这两种操作并不原子,也就是说,存在并发的场景下,可能出现冲突。
upsert设置为true的update函数也不是线程安全的。多个命令同时进行,都没有查询到匹配的文档时,会都执行插入,这样就会有多个文档了。
存在并发的环境 - 唯一索引
- 需要建立唯一索引,这样就不会有重复插入的情况了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
db.collection.createIndex(
<key and index type specification>, { unique: true }
)
# 单一字段索引
db.collection.createIndex({key:1},{unique:true})
# 组合字段索引
db.collection.createIndex({key_one:1,key_two:1},{unique:true})
# 然后直接尝试插入或者更新,抛出异常的时候再次使用更新即可
try:
db.collection.insert_one(document)
except DuplicateKeyError:
db.collection.update_one(filter, update)
# 或者:
try:
db.collection.update_one(filter, update, upsert=true)
except DuplicateKeyError:
db.collection.update_one(filter, update, upsert=true)
为了避免多次插入同一个文档,只有在查询字段是唯一索引的情况下才使用upsert: true
给定一个名为people的集合,其中没有文档的name字段持有值Andy。考虑当多个客户端同时发出以下upsert: true的更新时。
1
2
3
4
5
6
7
8
9
db.people.update(
{ name: "Andy" },
{
name: "Andy",
rating: 1,
score: 1
},
{ upsert: true }
)
如果所有的update()操作都在任何客户端成功插入数据之前完成了查询部分,并且在name字段上没有唯一索引,那么每次update操作都可能导致插入。
为了防止MongoDB不止一次地插入同一个文档,在name字段上创建一个唯一索引。
- 有了唯一索引,如果多个应用程序以upsert: true发出同一个更新,只会有一个update()成功插入一个新文档。
可能的剩余操作:
- 更新最新插入的文件,或者
- 试图插入一个重复的文档时失败。
- 如果操作因为重复的索引键错误而失败,应用程序可以重试操作,该操作将作为更新操作成功。
Get result
execution time
The execution time of a MongoDB query can vary based on several factors, including
- the complexity of the query,
- The time taken by a query can be influenced by the query filter, as it determines the number of documents that need to be examined and returned.
- A more selective query filter that matches a smaller number of documents can generally be executed faster.
- the size of the data set,
- the available indexes,
- and the hardware and network configuration.
MongoDB provides various features and optimizations to help improve query performance. To make MongoDB queries faster, consider the following approaches:
- Indexing:
- Properly indexing the data can significantly improve query performance.
- Indexes allow MongoDB to locate and retrieve documents more efficiently.
- Create indexes on fields commonly used in queries, sorting, and filtering operations.
- MongoDB provides different types of indexes, such as
single-field indexes, compound indexes, and multi-key indexes.
- Query Optimization:
- MongoDB provides a query optimizer that evaluates and selects the most efficient query plan for each query.
- It takes into account available indexes, query predicates, and other factors to determine the optimal execution plan.
- Understanding how the query optimizer works and structuring the queries appropriately can improve performance.
- Aggregation Framework:
- MongoDB’s Aggregation Framework allows perform complex data processing and transformation tasks on the server side.
- More efficient than retrieving large result sets and performing computations on the client side.
- Sharding:
- Large dataset that exceeds the capacity of a single machine, MongoDB’s sharding feature allows you to
distribute data across multiple servers. - Sharding helps improve query performance by parallelizing the query execution across multiple shards. You can find more information about sharding in the official documentation: Sharding
- Large dataset that exceeds the capacity of a single machine, MongoDB’s sharding feature allows you to
Query Optimization
在使用 MongoDB 時,如果完全沒有幫 collection 建立 index ,那在搜尋時就會需要把整個 collection 翻過來一個一個找過。
Query Plan
MongoDB提供了执行计划来帮助我们分析,一条语句执行情况
这条语句不会真正的被执行,只是为优化或者其他操作提供依据。
一般的,执行计划通常在索引中应用较多,通过执行计划查看创建的索引的应用情况。
查询计划逻辑:
在给定可用索引的情况下,MongoDB查询优化器处理查询并且选择出针对某查询而言最高效的查询计划。每次查询执行的时候,查询系统都会使用该查询计划。
查询优化器仅缓存那些有多个可行计划的 query shape。
对于每个查询,查询计划程序在查询计划缓存中搜索适合 query shape 的查询计划。如果没有匹配到合适的查询计划,则查询计划程序会生成候选计划,以便在试用期内进行评估。查询计划程序选择获胜计划,创建包含获胜计划的缓存条目,并使用它来生成结果文档。
如果存在匹配条目,则查询计划程序将根据该条目生成计划,并通过重新计划机制评估其性能。 此机制根据计划性能进行通过/失败决策,并保留或逐出缓存条目。 在逐出时,查询计划程序使用常规计划过程选择新计划并对其进行缓存。 查询计划程序执行计划并返回查询的结果文档。
语法参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
db.collection.explain(verbosity).<method(...)>
-- // method 支持查看以下语句的执行计划
aggregate()
count()
distinct()
find()
group()
remove()
update()
-- // 通过help查看帮助信息
db.collection.explain().help()
db.collection.explain().find().help()
-- // 你也可以这样使用执行计划,如查询某个集合的find语句的执行计划
db.collection.<method(...)>.explain()
db.collection.find().explain()
Query Plan verbosity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
db.test.explain().aggregate()
-- 准备数据
db.test.drop()
db.test.insertMany([
{"name": "zhangkai", "age": 18},
{"name": "wangkai", "age": 28},
{"name": "likai", "age": 10},
{"name": "zhaokai", "age": 21}
])
-- 为了后续的执行结果信息更全面,这里再创建两个索引 test_id1 和 test_id2
-- 两个索引都为age字段创建索引,1表示升序, -1表示降序
db.test.createIndex({"age": 1}, {"name": "test_id1"})
db.test.createIndex({"age": -1}, {"name": "test_id2"})
执行计划的返回结果的详细程度由可选参数verbosity参数决定,通常有三种模式:
queryPlanner:- 默认模式
- MongoDB运行查询优化器 对当前的查询进行评估并选择一个最佳的查询计划。
executionStats:- MongoDB运行查询优化器 对当前的查询进行评估并选择一个最佳的查询计划进行执行,在执行完毕后返回这个最佳执行计划执行完成时的相关统计信息,对于那些被拒绝的执行计划,不返回其统计信息。
allPlansExecution:- 该模式包括上述2种模式的所有信息,即按照最佳的执行计划执行以及列出统计信息,如果存在其他候选计划,也会列出这些候选的执行计划。
queryPlanner
知道语句的执行情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
-- 下面两条执行计划等价
db.test.explain("queryPlanner").find({"age": {"$gt": 20}})
db.test.explain().find({"age": {"$gt": 20}})
{
"queryPlanner" : {
"plannerVersion" : 1, // 查询计划版本
"namespace" : "t1.test", // 被查询对象,也就是被查询的集合
"indexFilterSet" : false, // 决定了查询优化器对于某一类型的查询将如何使用index,后面会展开来说
"parsedQuery" : { // 解析查询,即过滤条件是什么,此处是 age > 20
"age" : { "$gt" : 20 } },
"winningPlan" : { // 查询优化器针对该query所返回的最优执行计划的详细内容
"stage" : "FETCH", // 最优执行计划的stage,这里返回是FETCH,可以理解为通过返回的index位置去检索具体的文档
"inputStage" : {
"stage" : "IXSCAN", // 此时的stage是IXSCAN,表示进行的是 index scanning
"keyPattern" : {
"age" : 1 // 所扫描的index内容
},
"indexName" : "test_id1", // 最优计划选择的索引名称
"isMultiKey" : false, // 是否是多键索引,因为这里用到的索引是单列索引,所以这里是false
"multiKeyPaths" : { "age" : [ ] },
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward", // 此query的查询顺序,forward是升序,降序则是backward
"indexBounds" : { // 最优计划所扫描的索引范围
"age" : [
"(20.0, inf.0]" // [MinKey,MaxKey],最小从20.0开始到无穷大
]
}
}
},
"rejectedPlans" : [ ] // 其他计划,因为不是最优而被查询优化器拒绝(reject),这里为空
},
"serverInfo" : { // 服务器信息,包括主机名和ip,MongoDB的version等信息
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
operationTime: Timestamp({ t: 1688410560, i: 1 })
}
executionStats
返回最优计划的详细的执行信息。
- 必须是 executionStats 或者 allPlansExecution 模式中,才返回executionStats结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
db.test.explain("executionStats").find({"age": {"$gt": 20}})
{
"queryPlanner" : {
"plannerVersion" : 1, // 查询计划版本
"namespace" : "t1.test", // 被查询对象,也就是被查询的集合
"indexFilterSet" : false, // 决定了查询优化器对于某一类型的查询将如何使用index,后面会展开来说
"parsedQuery" : { // 解析查询,即过滤条件是什么,此处是 age > 20
"age" : {
"$gt" : 20
}
},
"winningPlan" : { // 查询优化器针对该query所返回的最优执行计划的详细内容
"stage" : "FETCH", // 最优执行计划的stage,这里返回是FETCH,可以理解为通过返回的index位置去检索具体的文档
"inputStage" : {
"stage" : "IXSCAN", // 此时的stage是IXSCAN,表示进行的是 index scanning
"keyPattern" : {
"age" : 1 // 所扫描的index内容
},
"indexName" : "test_id1", // 最优计划选择的索引名称
"isMultiKey" : false, // 是否是多键索引,因为这里用到的索引是单列索引,所以这里是false
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward", // 此query的查询顺序,forward是升序,降序则是backward
"indexBounds" : { // 最优计划所扫描的索引范围
"age" : [
"(20.0, inf.0]" // [MinKey,MaxKey],最小从20.0开始到无穷大
]
}
}
},
"rejectedPlans" : [ ] // 其他计划,因为不是最优而被查询优化器拒绝(reject),这里为空
},
"executionStats" : {
"executionSuccess" : true, // 是否执行成功
"nReturned" : 2, // 此query匹配到的文档数
"executionTimeMillis" : 0, // 查询计划选择和查询执行所需的总时间,单位:毫秒
"totalKeysExamined" : 2, // 扫描的索引条目数
"totalDocsExamined" : 2, // 扫描的文档数
"executionStages" : { // 最优计划完整的执行信息
"stage" : "FETCH", // 根据索引结果扫描具体文档
"nReturned" : 2, // 由于是 FETCH,这里的结果跟上面的nReturned结果一致
"executionTimeMillisEstimate" : 0,
"works" : 3, // 查询执行阶段执行的"工作单元"的数量。 查询执行阶段将其工作分为小单元。 "工作单位"可能包括检查单个索引键,从集合中提取单个文档,将投影应用于单个文档或执行内部记账
"advanced" : 2, // 返回到父阶段的结果数
"needTime" : 0, // 未将中间结果返回给其父级的工作循环数
"needYield" : 0, // 存储层请求查询系统产生锁定的次数
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1, // 执行阶段是否已到达流的结尾
"invalidates" : 0,
"docsExamined" : 2, // 跟totalDocsExamined结果一致
"alreadyHasObj" : 0,
"inputStage" : { // 一个小的工作单元,一个执行计划中,可以有一个或者多个inputStage
"stage" : "IXSCAN",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 3,
"advanced" : 2,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"age" : 1
},
"indexName" : "test_id1",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(20.0, inf.0]"
]
},
"keysExamined" : 2,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0
}
}
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
执行计划的结果是以阶段树的形式呈现,每个阶段将其结果(文档或者索引键)传递给父节点,叶子节点访问集合或者索引,中间节点操纵由子节点产生的文档或者索引键,最后汇总到根节点。
queryPlanner.winningPlan.stage参数,常用的有:
- COLLSCAN 全表扫描
- IXSCAN 索引扫描
- FETCH 根据索引检索指定的文档
- SHARD_MERGE 将各个分片的返回结果进行merge
- SORT 表明在内存中进行了排序
- LIMIT 使用limit限制返回结果数量
- SKIP 使用skip进行跳过
- IDHACK 针对_id字段进行查询
- SHANRDING_FILTER 通过mongos对分片数据进行查询
- COUNT 利用db.coll.explain().count()进行count运算
- COUNTSCAN count不使用用index进行count时的stage返回
- COUNT_SCAN count使用了Index进行count时的stage返回
- SUBPLA 未使用到索引的
$or查询的stage返回 - TEXT 使用全文索引进行查询时候的stage返回
- PROJECTION 限定返回字段时候stage的返回
allPlansExecution
返回了更为详细的执行计划结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
db.test.explain("allPlansExecution").find({"age": {"$gt": 20}})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.test",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$gt" : 20
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "test_id1",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(20.0, inf.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 2,
"executionTimeMillis" : 0,
"totalKeysExamined" : 2,
"totalDocsExamined" : 2,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 3,
"advanced" : 2,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"docsExamined" : 2,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 2,
"executionTimeMillisEstimate" : 0,
"works" : 3,
"advanced" : 2,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"age" : 1
},
"indexName" : "test_id1",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(20.0, inf.0]"
]
},
"keysExamined" : 2,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0
}
},
"allPlansExecution" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
query shape
- 由 query,sort 和 projection 的组合组成。
- 即查询谓词,排序和投影规范的组合。
- 投影意味着仅选择必要的数据,而不是选择文档的整个数据。 如果文档有5个字段,而我们只需要显示3个字段,则仅从其中选择3个字段。 MongoDB提供了一些投影运算符,可以帮助我们实现该目标。
Plan Cache Flushes 计划缓存刷新
- 索引或集合等目录操作会刷新计划缓存。
- mongod 重启或关闭计划缓存(会丢失)将不会被留存。
IndexFilter 索引过滤器
https://docs.mongodb.com/v3.6/core/query-plans/#index-filters
执行计划的重点还是queryPlanner和executionStats部分。
- 确定优化程序为 query shape 评估的索引。
对于给定 query shape 如果存在 Index Filters,则优化程序仅考虑过滤器中指定的那些索引。
当 query shape 存在索引过滤器时,MongoDB 会忽略 hint()。查询MongoDB为 query shape 是否使用了索引过滤器,检查 db.collection.explain() 或 cursor.explain() 方法的 indexFilterSet (boolean 类型)字段。
Index Filters 仅影响优化程序评估的索引; 优化器仍然可以选择集合扫描作为给定 query shape 的获胜计划。
Index Filters 在服务器进程的持续时间内存在,并且在关闭后不会保留。 MongoDB还提供了手动删除过滤器的命令。
由于 Index Filters 会覆盖优化程序的预期行为以及hint() 方法,谨慎使用。
决定了查询优化器对于某一类型的查询将如何使用index,且仅影响指定的查询类型。
- 为指定类型的查询提前设置使用某一个或者从多个备选索引中选择指定索引。
- IndexFilter指定的索引必须存在,如果索引不存在——也没事!全表扫描呗!
- IndexFilter的优先级高于hint,这点是在生产中要注意的。
- IndexFilter一定程度上解决了某些问题,但它使用相对麻烦,谨慎使用!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
-- // 首先,集合 test 有三个索引
db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_", // MongoDB自动创建的索引
"ns" : "t1.test"
},
{
"v" : 2,
"key" : {
"age" : 1
},
"name" : "test_id1", // 我们手动创建的索引
"ns" : "t1.test"
},
{
"v" : 2,
"key" : {
"age" : -1
},
"name" : "test_id2", // 我们手动创建的索引
"ns" : "t1.test"
}
]
-- // 在查询时,MongoDB会自动的帮我们选择使用哪个索引
-- // 以下两种查询查询优化器都会选择使用 test_id2 索引
db.test.explain().find({"age": {"$gt":18}})
db.test.explain().find({"age": 18})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.test",
"indexFilterSet" : false, // 注意这个值是false
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : -1
},
"indexName" : "test_id2", // 查询优化器选择了test_id2这个索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
},
"rejectedPlans" : [
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "test_id1", // 并将test_id1索引排除
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
}
]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
如果有些应用场景下需要特定索引,而不是用查询优化器帮助我们选择的索引,该怎么办?
- 通过 hint 明确指定索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
db.test.explain().find({"age": {"$gt":18}}).hint("test_id1")
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.test",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$gt" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "test_id1", // hint告诉查询优化器选择使用指定的索引test_id1
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(18.0, inf.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
- 其他的解决方式,就是提前声明为某一类查询指定特定的索引(索引必须存在),当有这类查询时,自动使用特定索引,或者从指定的几个索引中选择一个,而不是通过hint显式指定,且不影响其他类型的查询,这就用到了IndexFilter。
1
2
3
4
5
6
7
-- // 创建IndexFilter
db.runCommand({
planCacheSetFilter: "test",
query: {"age": 18}, // 只要查询类型是 age等于某个值,该IndexFilter就会被应用,并不特指18
// indexes:[{age: 1}] // 跟下面一行等价
indexes:["test_id1"] // 可以有多个备选索引
})
上面的IndexFilter的意思是
- 当查询集合test时,且查询类型是age等于某个值时(只作用于该类型的查询),就从 indexes 数组中选择一个索引,或者从多个备选索引中,选择一个最优的索引,
- 当然,你也可以像示例中一样,只写一个索引test_id1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
-- 来看应用:
-- // 对于查询是 age 等于某个值这种类型的查询,查询优化器都会选择我们指定的IndexFilter
db.test.explain().find({"age": 18})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.test",
"indexFilterSet" : true, // IndexFilter被应用
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "test_id1", // 使用了IndexFilter指定的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
- 如果某一类型的查询设定了IndexFilter,那么执行时通过hint指定了其他的index,查询优化器将会忽略hint所设置index,仍然使用indexfilter中设定的查询计划,也就是下面这种情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
db.test.explain().find({"age": 18}).hint("test_id2") // 希望在查询时使用 test_id2 索引
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "t1.test",
"indexFilterSet" : true, // 创建的indexFilter被应用
"parsedQuery" : {
"age" : {
"$eq" : 18
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : 1
},
"indexName" : "test_id1", // 忽略hint指定的test_id2,选择IndexFilter指定的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[18.0, 18.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "cs",
"port" : 27017,
"version" : "3.6.12",
"gitVersion" : "c2b9acad0248ca06b14ef1640734b5d0595b55f1"
},
"ok" : 1
}
- IndexFilter不会影响其他类型的查询,如下面的查询类型,查询优化器还是按照原来的规则选择最优计划:
1
2
db.test.explain().find({"age": {"$gt":18}})
db.test.explain().find({"age": {"$gt":18}}).hint("test_id1")
- IndexFilter的其他操作:
1
2
3
4
5
6
7
8
9
10
-- // 查看指定集合中的IndexFilter数组
db.runCommand({planCacheListFilters: "test"})
-- // 删除IndexFilter
db.runCommand({
planCacheClearFilters: "test",
// query: {"age": 18}, // 对应创建IndexFilter时的注释的那一行
indexes:["test_id1"]
})
-- 当然,在有些情况下,你删除指定的IndexFilter会失败,终极的解决办法是——重启MongoDB服务。
runCommand
planCacheListFilters
运行这个命令用户必须要有 planCacheIndexFilter 操作的权限。
- 列出与集合 query shape 有关联的索引过滤器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
db.runCommand( { planCacheListFilters: <collection_name> } )
{
"filters" : [
{
"query" : <query>
"sort" : <sort>,
"projection" : <projection>,
"indexes" : [
<index1>,
...
]
},
...
],
"ok" : 1
}
- filters 包含索引过滤器信息的文档数组。
- filters.query 与此过滤器关联的查询谓词。
- 虽然查询显示了用于创建索引过滤器的特定值,但谓词中的值无关紧要; 即,查询谓词包括仅在值不同的类似查询。
- 例如,对于
{ "type": "electronics", "status" : "A" }的查询谓词等同如下查询谓词: javascript { type: "food", status: "A" } { type: "utensil", status: "D" }
- sort . projection 和 find 一起构成了索引过滤器的 query shape。
- filters.sort 与此过滤器关联的 sort,可以是一个空文档。
- filters.projection 与此过滤器关联的 projection,可以是一个空文档。
- filters.indexes 此 query shape 的索引数组。查询优化程序仅评估列出的索引和集合扫描,从中选择最佳查询计划。
- ok 命令执行状态。
planCacheClearFilters
运行这个命令用户必须要有 planCacheIndexFilter 操作的权限。
删除集合上的索引过滤器。尽管索引过滤器仅存在于服务器进程中重启进程后不保留,仍可以使用 planCacheClearFilters 命令删除索引过滤器。
指定 query shape 删除指定的索引过滤器。或者忽略 query shape 删除集合上所有的索引过滤器。命令语法格式如下:
1
2
3
4
5
6
7
8
db.runCommand(
{
planCacheClearFilters: <collection_name>,
query: <query pattern>,
sort: <sort specification>,
projection: <projection specification>
}
)
- planCacheClearFilters string 类型
- query. sort. projection 都是 document 类型。
- 在集合上删除指定的索引过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
-- orders 集合包含如下两个索引过滤器:
{
"query" : { "status" : "A" },
"sort" : { "ord_date" : -1 },
"projection" : { },
"indexes" : [ { "status" : 1, "cust_id" : 1 } ]
}
{
"query" : { "status" : "A" },
"sort" : { },
"projection" : { },
"indexes" : [ { "status" : 1, "cust_id" : 1 } ]
}
-- 如下命令仅删除第二个索引过滤器:
db.runCommand(
{
planCacheClearFilters: "orders",
query: { "status" : "A" }
}
)
-- 由于查询谓词中的值在确定query shape 时无关紧要,因此以下命令(等同于上)也会删除第二个索引过滤器:
db.runCommand(
{
planCacheClearFilters: "orders",
query: { "status" : "P" }
}
)
- 删除集合上所有的索引过滤器
1
2
3
4
5
db.runCommand(
{
planCacheClearFilters: "orders"
}
)
planCacheSetFilter
运行这个命令用户必须要有 planCacheIndexFilter 操作的权限。
- 为集合设置索引过滤器。
对于 query shape 已存在索引过滤器则此命令会重写之前的索引过滤器。命令语法如下:
- 索引过滤器仅存在于服务器进行运行时,进程关闭以后不予以保留。
1
2
3
4
5
6
7
8
9
db.runCommand(
{
planCacheSetFilter: <collection>,
query: <query>,
sort: <sort>,
projection: <projection>,
indexes: [ <index1>, <index2>, ...]
}
)
在仅包含谓词的 query shape 上设置过滤器
- 在 orders 集合仅包含 status 字段上的相等匹配但没有任何 projection 和 sort 的查询上创建索引过滤器,以便对于,查询优化器仅评估两个指定的索引以及获胜计划的集合扫描:
1 2 3 4 5 6 7 8 9 10
db.runCommand( { planCacheSetFilter: "orders", query: { status: "A" }, indexes: [ { cust_id: 1, status: 1 }, { status: 1, order_date: -1 } ] } )
- 在查询谓词中,只有谓词的结构(包括字段名称)是重要的; 值是无关紧要的。 因此,创建的过滤器适用于以下操作:
- db.orders.find( { status: “D” } )
- db.orders.find( { status: “P” } )
包括谓词,投影和排序的 query shape 上设置过滤器
- 以下示例为 orders 集合上谓词在 item 字段上相等匹配的查询,其中仅投影 quantity 字段,并指定按 order_date 升序排序的查询创建索引过滤器。
1 2 3 4 5 6 7 8 9 10 11
db.runCommand( { planCacheSetFilter: "orders", query: { item: "ABC" }, projection: { quantity: 1, _id: 0 }, sort: { order_date: 1 }, indexes: [ { item: 1, order_date: 1 , quantity: 1 } ] } )
Comments powered by Disqus.