AI - MLOps
AI - MLOps
MLOps
definition
machine learning operations
- the process of managing the machine learning life cycle, from development to deployment and monitoring.
set of practices that helps data scientists and engineers to manage the machine learning (ML) life cycle more efficiently.
It aims to bridge the gap between development and operations for machine learning. The goal of MLOps is to ensure that ML models are developed, tested, and deployed in a consistent and reliable way.
MLOps is becoming increasingly important as more and more organizations are using ML models to make critical business decisions.
It involves tasks such as:
Experiment tracking: Keeping track of experiments and results to identify the best models
Model deployment: Deploying models to production and making them accessible to applications
Model monitoring: Monitoring models to detect any issues or degradation in performance
Model retraining: Retraining models with new data to improve their performance
- MLOps is essential for ensuring that machine learning models are
reliable, scalable, and maintainablein production environments.
The importance of MLOps
- managing the ML life cycle
- ensuring the ML models are effectively
developed, deployed, and maintained. Without MLOps, organizations may face several challenges, including:
Increased risk of errors: Manual processes can lead to
errors and inconsistenciesin the ML life cycle, which can impact the accuracy and reliability of ML models.Lack of scalability: Manual processes can become
difficult to manageas ML models and datasets grow in size and complexity, making it difficult to scale ML operations effectively.Reduced efficiency: Manual processes can be
time-consuming and inefficient, slowing down the development and deployment of ML models.Lack of collaboration: Manual processes can make it difficult for data scientists, engineers, and operations teams to collaborate effectively, leading to silos and communication breakdowns.
- MLOps addresses these challenges by providing a framework and set of tools to automate and manage the ML life cycle. It enables organizations to develop, deploy, and maintain ML models more efficiently, reliably, and at scale.
Benefits of MLOps
Improved efficiency: MLOps automates and streamlines the ML life cycle, reducing the time and effort required to develop, deploy, and maintain ML models
Increased scalability: MLOps enables organizations to scale their ML operations more effectively, handling larger datasets and more complex models
Improved reliability: MLOps reduces the risk of errors and inconsistencies, ensuring that ML models are reliable and accurate in production
Enhanced collaboration: MLOps provides a common framework and set of tools for data scientists, engineers, and operations teams to collaborate effectively
Reduced costs: MLOps can help organizations reduce costs by automating and optimizing the ML life cycle, reducing the need for manual intervention
Difference between MLOps and DevOps?
- DevOps: a set of practices that helps organizations to
bridge the gap between software development and operations teams. MLOps: a similar set of practices that specifically addresses the needs of ML models.
key differences:
- Scope:
- DevOps: focuses on the
software developmentlife cycle - MLOps: focuses on the
MLlife cycle
- DevOps: focuses on the
- Complexity:
- ML models are often more complex than traditional software applications, requiring specialized tools and techniques for development and deployment
- Data:
- ML models rely on data for training and inference, which introduces additional challenges for managing and processing data
- Regulation:
- ML models may be subject to regulatory requirements, which can impact the development and deployment process
- Scope:
- Despite these differences, MLOps and DevOps share some common principles, such as the importance of collaboration, automation, and continuous improvement. Organizations that have adopted DevOps practices can often leverage those practices when implementing MLOps.
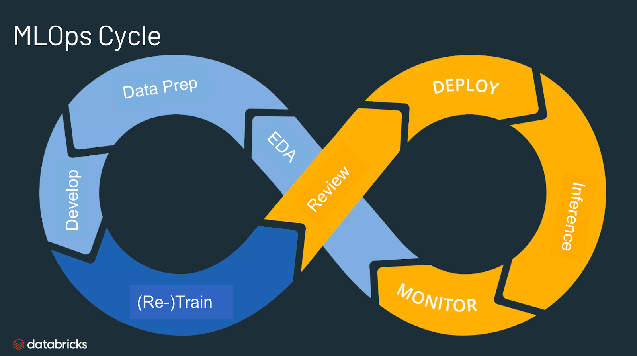
Basic components of MLOps
MLOps consists of several components that work together to manage the ML life cycle, including:
Exploratory data analysis (EDA):
process of exploring and understanding the
datathat will be used to train the ML model. This involves tasks such as:Data visualization: Visualizing the data to identify patterns, trends, and outliers
Data cleaning: Removing duplicate or erroneous data and dealing with missing values
Data prep and feature engineering
- Data preparation:
- involves cleaning, transforming, and formatting the raw data to make it suitable for model training.
Feature engineering:
Transforming the raw data into features that are relevant and useful for the ML model
involves creating new features from the raw data that are more relevant and useful for model training. These steps are essential for ensuring that the ML model is trained on high-quality data and can make accurate predictions.
- Data preparation:
Model training and tuning
Model training and tuning involve training the ML model on the prepared data and optimizing its hyperparameters to achieve the best possible performance.
Common tasks for model training and tuning include:
Selecting the right ML algorithm: Choosing the right ML algorithm for the specific problem and dataset
Training the model: Training the ML model on the training data
Tuning the model: Adjusting the hyperparameters of the ML model to improve its performance
Evaluating the model: Evaluating the performance of the ML model on the test data
Model review and governance
Model review and governance ensure that ML models are developed and deployed responsibly and ethically.
Model validation: Validating the ML model to ensure it meets the desired performance and quality standards
Model fairness: Ensuring the ML model does not exhibit bias or discrimination
Model interpretability: Ensuring the ML model is understandable and explainable
Model security: Ensuring the ML model is secure and protected from attacks
Model inference and serving
Model inference and serving involve deploying the trained ML model to production and making it available for use by applications and end users.
Model deployment: Deploying the ML model to a production environment
Model serving: Making the ML model available for inference by applications and end-users
Model monitoring
Model monitoring involves continuously monitoring the performance and behavior of the ML model in production. Tasks may include:
Model monitoring: Monitoring the performance and behavior of the ML model in production
Tracking model performance: Tracking metrics such as accuracy, precision, and recall to assess the performance of the ML model
Detecting model drift: Detecting when the performance of the ML model degrades over time due to changes in the data or environment
Identifying model issues: Identifying issues such as bias, overfitting, or underfitting that may impact the performance of the ML model
Automated model retraining
Automated model retraining involves retraining the ML model when its performance degrades or when new data becomes available. Automated model retraining includes:
Triggering model retraining: Triggering the retraining process when specific conditions are met, such as a decline in model performance or the availability of new data
Retraining the model: Retraining the ML model using the latest data and updating the model in production
Evaluating the retrained model: Evaluating the performance of the retrained model and ensuring it meets the desired performance standards
AI Readiness
AI Readiness is the maturity level in adopting AI technologies in your organization.
- The amount of MLOps practices determines AI Readiness.
- The AI Readiness ranges from
manual and ad-hoc deployment in the tactical phase to using pipelines in the strategic phase, tocreating fully automated ML pipelinesandusing advanced MLOps in the transformational phase.
ML Ops Best Practices
DATA & CODE MANAGEMENT
DATA SOURCES & DATA VERSIONING
- Is data versioning optional or mandatory?
- E.g., is data versioning a requirement for a system like a regulatory requirement?
- What data sources are available?
- (e.g., owned, public, earned, paid data)
- What is the storage for the above data?
- (e.g., data lake, DWH)
- Is manual labeling required? Do we have human resources for it?
- How to version data for each trained model?
- What tooling is available for data pipelines/workflows?
DATA ANALYSIS & EXPERIMENT MANAGEMENT
- What programming language to use for analysis? (Is SQL sufficient for analysis?)
- What ML algorithm will be used?
- What evaluation metrics need to be computed?
- Are there any infrastructure requirements for model training?
- Reproducibility: What metadata about ML experiments is collected? (data sets, hyper-parameters)
- What IDE are we confident with?
- What ML Framework know-how is there?
FEATURE STORE & WORKFLOWS
- Is this optional or mandatory? Do we have a data governance process such that feature engineering has to be reproducible?
- How are features computed (workflows) during the training and prediction phases?
- Are there any infrastructure requirements for feature computation
- “Buy or make” for feature stores?
- What databases are involved in feature storage?
- Do we design APIs for feature engineering?
FOUNDATIONS
- How do we maintain the code? What source version control system is used?
- How do we monitor the system performance?
- Do we need versioning for notebooks?
- Is there a trunk-based development in place?
- Deployment and testing automation: What is the CI/CD pipeline for the codebase? What tools are used for it?
- Do we track deployment frequency, lead time for changes, mean time to restore, and change failure rate metrics?
METADATA MANAGEMENT
METADATA STORE
- What kind of metadata in code, data, ML pipeline execution and model management need to be collected?
- What is the documentation strategy: Do we treat documentation as a code? (examples: Datasheets for Datasets, Model Card for Model Reporting )
- What operational metrics need to be collected?
- E.g., time to restore, change fail percentage.
- SRE for ML: How outages/failures will be protocolled?
MODEL MANAGEMENT
CI/CT/CD: ML PIPELINE ORCHESTRATION
[Building, testing, packaging and deploying of ML pipeline]
- How often are models expected to be re-trained? Where does this happen (locally or on cloud)?
- What is the formalized workflow for an ML pipeline?
- (e.g., Data prep -> model training -> model eval & validation)
- What tech stack is used?
- Is distributed model training required? Do we have an infrastructure for the distributed training?
- What is the workflow for the CI pipeline? What tools are used?
- What are the non-functional requirements for the ML model? How are they tested? Are these tests integrated into the CI/CT workflow?
MODEL REGISTRY & MODEL VERSIONING
- Is this optional or mandatory?
- Where should new ML models be stored and tracked?
- What versioning standards are used? (e.g., semantic versioning)
MODEL DEPLOYMENT
- What is the delivery format for the model?
- What is the expected time for changes? (Time from commit to production)
- What is the target environment to serve predictions?
- What is your model release policy? Is A/B testing or multi-armed bandit testing required? (e.g., for deciding what model to deploy)
- Is shadow/canary deployment required?
PREDICTION SERVING
- What is the serving mode? (batch or online)
- Is distributed serving required?
- Do you need ML inference accelerators (TPU)?
- What is the expected target volume of predictions per month or hours?
MODEL & DATA & APPLICATION MONITORING
- Is this optional or mandatory?
- What ML metrics are collected?
- What domain-specific metrics are collected?
- How is the model staleness detected? (Data Monitoring)
- How is the data skew detected? (Data Monitoring)
- What operational aspects need to be monitored? (SRE)
- What is the alerting strategy? (thresholds)
- What triggers the model re-training?
- e.g. Latency of model serving
Comments powered by Disqus.