AWS - Lambda
ref:
- https://serverless.kpingfan.com/01-lambda-101/05.concurrency/
Lambda
Lambda sample
basic
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import json, urllib, boto3, csv
# Connect to S3
s3 = boto3.resource('s3')
# Connect to SNS
sns = boto3.client('sns')
alertTopic = 'HighBalanceAlert'
# Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
customerTable = dynamodb.Table('Customer');
transactionsTable = dynamodb.Table('Transactions');
# Connect to EC2
ec2 = boto3.resource('ec2')
# Add a tag to the EC2 instance: Key = Snapshots, Value = Created
ec2 = boto3.client('ec2')
response = ec2.create_tags(
Resources=[ec2InstanceId],
Tags=[{'Key': 'Snapshots', 'Value': 'Created'}]
)
print ("***Tag added to EC2 instance with id: " + ec2InstanceId)
S3 triggered, Loops and inserts data into DynamoDB tables
- Examine the code. It performs the following steps:
- Downloads the file from Amazon S3 that triggered the event
- Loops through each line in the file
- Inserts the data into the Customer and Transactions DynamoDB tables
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# TransactionProcessor Lambda function
# This function is triggered by an object being created in an Amazon S3 bucket.
# The file is downloaded and each line is inserted into DynamoDB tables.
from __future__ import print_function
import json, urllib, boto3, csv
# Connect to S3 and DynamoDB
s3 = boto3.resource('s3')
dynamodb = boto3.resource('dynamodb')
# Connect to the DynamoDB tables
customerTable = dynamodb.Table('Customer');
transactionsTable = dynamodb.Table('Transactions');
# This handler is executed every time the Lambda function is triggered
def lambda_handler(event, context):
# Show the incoming event in the debug log
print("Event received by Lambda function: " + json.dumps(event, indent=2))
# Get the bucket and object key from the Event
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key']).decode('utf8')
localFilename = '/tmp/transactions.txt'
# Download the file from S3 to the local filesystem
try:
s3.meta.client.download_file(bucket, key, localFilename)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and the bucket is in the same region as this function.'.format(key, bucket))
raise e
# Read the Transactions CSV file. Delimiter is the '|' character
with open(localFilename) as csvfile:
reader = csv.DictReader(csvfile, delimiter='|')
# Read each row in the file
rowCount = 0
for row in reader:
rowCount += 1
# Show the row in the debug log
print(row['customer_id'], row['customer_address'], row['trn_id'], row['trn_date'], row['trn_amount'])
try:
# Insert Customer ID and Address into Customer DynamoDB table
customerTable.put_item(
Item={
'CustomerId': row['customer_id'],
'Address': row['customer_address']})
# Insert transaction details into Transactions DynamoDB table
transactionsTable.put_item(
Item={
'CustomerId': row['customer_id'],
'TransactionId': row['trn_id'],
'TransactionDate': row['trn_date'],
'TransactionAmount': int(row['trn_amount'])})
except Exception as e:
print(e)
print("Unable to insert data into DynamoDB table".format(e))
# Finished!
return "%d transactions inserted" % rowCount
function to calculate and send Simple Notification Service notification
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# TotalNotifier Lambda function
#
# This function is triggered when values are inserted into the Transactions DynamoDB table.
# Transaction totals are calculated and notifications are sent to SNS if limits are exceeded.
from __future__ import print_function
import json, boto3
# Connect to SNS
sns = boto3.client('sns')
alertTopic = 'HighBalanceAlert'
snsTopicArn = [t['TopicArn'] for t in sns.list_topics()['Topics'] if t['TopicArn'].endswith(':' + alertTopic)][0]
# Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
transactionTotalTableName = 'TransactionTotal'
transactionsTotalTable = dynamodb.Table(transactionTotalTableName);
# This handler is executed every time the Lambda function is triggered
def lambda_handler(event, context):
# Show the incoming event in the debug log
print("Event received by Lambda function: " + json.dumps(event, indent=2))
# For each transaction added, calculate the new Transactions Total
for record in event['Records']:
customerId = record['dynamodb']['NewImage']['CustomerId']['S']
transactionAmount = int(record['dynamodb']['NewImage']['TransactionAmount']['N'])
# Update the customer's total in the TransactionTotal DynamoDB table
response = transactionsTotalTable.update_item(
Key={
'CustomerId': customerId
},
UpdateExpression="add accountBalance :val",
ExpressionAttributeValues={
':val': transactionAmount
},
ReturnValues="UPDATED_NEW"
)
# Retrieve the latest account balance
latestAccountBalance = response['Attributes']['accountBalance']
print("Latest account balance: " + format(latestAccountBalance))
# If balance > $1500, send a message to SNS
if latestAccountBalance >= 1500:
# Construct message to be sent
message = '{"customerID": "' + customerId + '", ' + '"accountBalance": "' + str(latestAccountBalance) + '"}'
print(message)
# Send message to SNS
sns.publish(
TopicArn=snsTopicArn,
Message=message,
Subject='Warning! Account balance is very high',
MessageStructure='raw'
)
# Finished!
return 'Successfully processed {} records.'.format(len(event['Records']))
the Different Ways to Invoke Lambda Functions
https://aws.amazon.com/blogs/architecture/understanding-the-different-ways-to-invoke-lambda-functions/

Synchronous Invokes
- the most straight forward way to invoke the Lambda functions.
- the functions execute immediately when perform the Lambda Invoke API call.
- This can be accomplished through a variety of options, including using the CLI or any of the supported SDKs.
exampl:
synchronous invoke using the CLI:
1
2
3
4
aws lambda invoke \
—function-name MyLambdaFunction \
—invocation-type RequestResponse \
—payload “[JSON string here]”
The Invocation-type flag specifies a value of “RequestResponse”. This instructs AWS to execute the Lambda function and wait for the function to complete.
- When perform a synchronous invoke, are responsible for checking the response and determining if there was an error and if should retry the invoke.
list of services that invoke Lambda functions synchronously:
- Elastic Load Balancing (Application Load Balancer)
- Amazon Cognito
- Amazon Lex
- Amazon Alexa
- Amazon API Gateway
- Amazon CloudFront (Lambda@Edge)
- Amazon Kinesis Data Firehose
Asynchronous Invokes
Here is an example of an asynchronous invoke using the CLI:
1
2
3
4
aws lambda invoke \
—function-name MyLambdaFunction \
—invocation-type Event \
—payload “[JSON string here]”
Notice, the Invocation-type flag specifies “Event.” If the function returns an error, AWS will automatically retry the invoke twice, for a total of three invocations.
Here is a list of services that invoke Lambda functions asynchronously:
- Amazon S3
- Amazon SNS
- Amazon Simple Email Service
- AWS CloudFormation
- Amazon CloudWatch Logs
- Amazon CloudWatch Events
- AWS CodeCommit
AWS Config
- Asynchronous invokes place the invoke request in Lambda service queue and we process the requests as they arrive. should use AWS X-Ray to review how long the request spent in the service queue by checking the “dwell time” segment.
Poll-Based Invokes
- This invocation model is designed to allow to integrate with AWS Stream and Queue based services with no code or server management.
- Lambda will poll the following services on the behalf, retrieve records, and invoke the functions.
The following are supported services:
- Amazon Kinesis
- Amazon SQS
Amazon DynamoDB Streams
- AWS will manage the poller on the behalf and perform Synchronous invokes of the function with this type of integration.
- The retry behavior for this model is based on data expiration in the data source.
- For example, Kinesis Data streams store records for 24 hours by default (up to 168 hours). The specific details of each integration are linked above.
Lambda’s invoke throttling limits
When call AWS Lambda’s Invoke API, a series of throttle limits are evaluated to decide if the call is let through or throttled with a 429 “Too Many Requests” exception.
The throttle limits exist to protect the following components of Lambda’s internal service architecture, and the workload, from noisy neighbors:
- Execution environment:
- An execution environment is a Firecracker microVM where the function code runs.
- A given execution environment only hosts one invocation at a time, but it can be reused for subsequent invocations of the same function version.
- Invoke data plane:
- These are a series of internal web services that, on an invoke, select (or create) a sandbox and route the request to it.
- This is also responsible for enforcing the throttle limits.
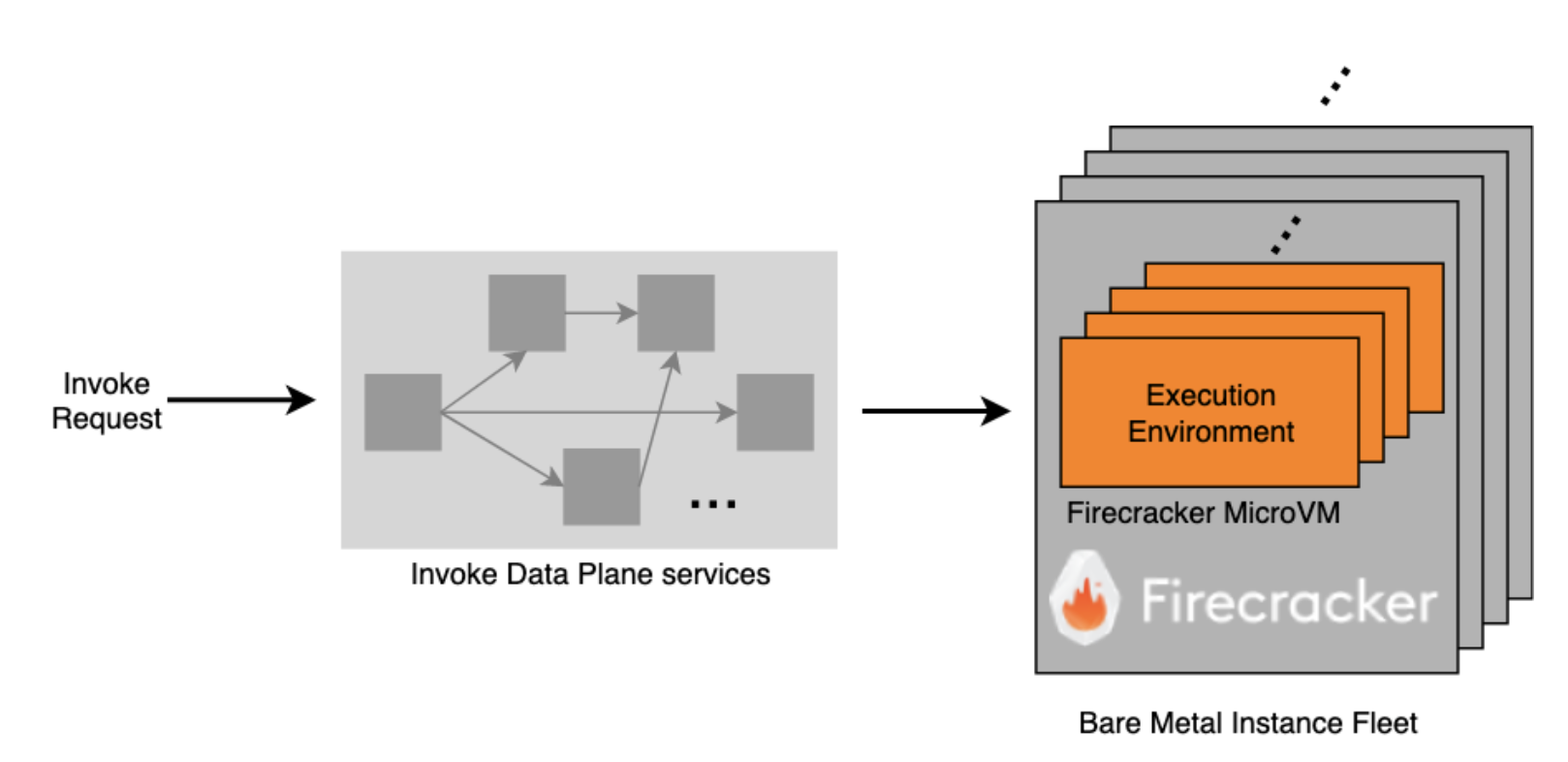
Invoke call flow:
- When make an Invoke API call, it transits through some or all of the Invoke Data Plane services, before reaching an execution environment where the function code is downloaded and executed.
There are three distinct but related throttle limits which together decide if the invoke request is accepted by the data plane or throttled.
Concurrency
https://docs.aws.amazon.com/lambda/latest/dg/lambda-concurrency.html
Concurrent means “existing, happening, or done at the same time”.
Accordingly, the Lambda concurrency limit is a limit on the simultaneous in-flight invocations allowed at any given time.
It is not a
rateortransactions per second (TPS)limit in and of itself, but instead a limit on how many invocations can be in-flight at the same time.the concurrency limit roughly translates to a limit on the maximum number of execution environments (and thus Firecracker microVMs) that the account can claim at any given point in time.
Lambda runs a fleet of multi-tenant bare metal instances, on which Firecracker microVMs are carved out to serve as execution environments for the functions. AWS constantly monitors and scales this fleet based on incoming demand and shares the available capacity fairly among customers.
The concurrency limit helps protect Lambda from a single customer exhausting all the available capacity and causing a denial of service to other customers.
- 当某个Lambda的并发执行数达到默认的1000后,不仅会影响自身的执行,同时会影响同一region下的其他函数,因为默认的quota是应用在一个region下所有Lambda的。
- 例如当ALB后面的Lambda并发数超出最大限制后,挂到API Gateway下面的Lambda一起会被Throttle:

Transactions per second (TPS)
How concurrency limit translates to TPS depends on how long the function invocations last:
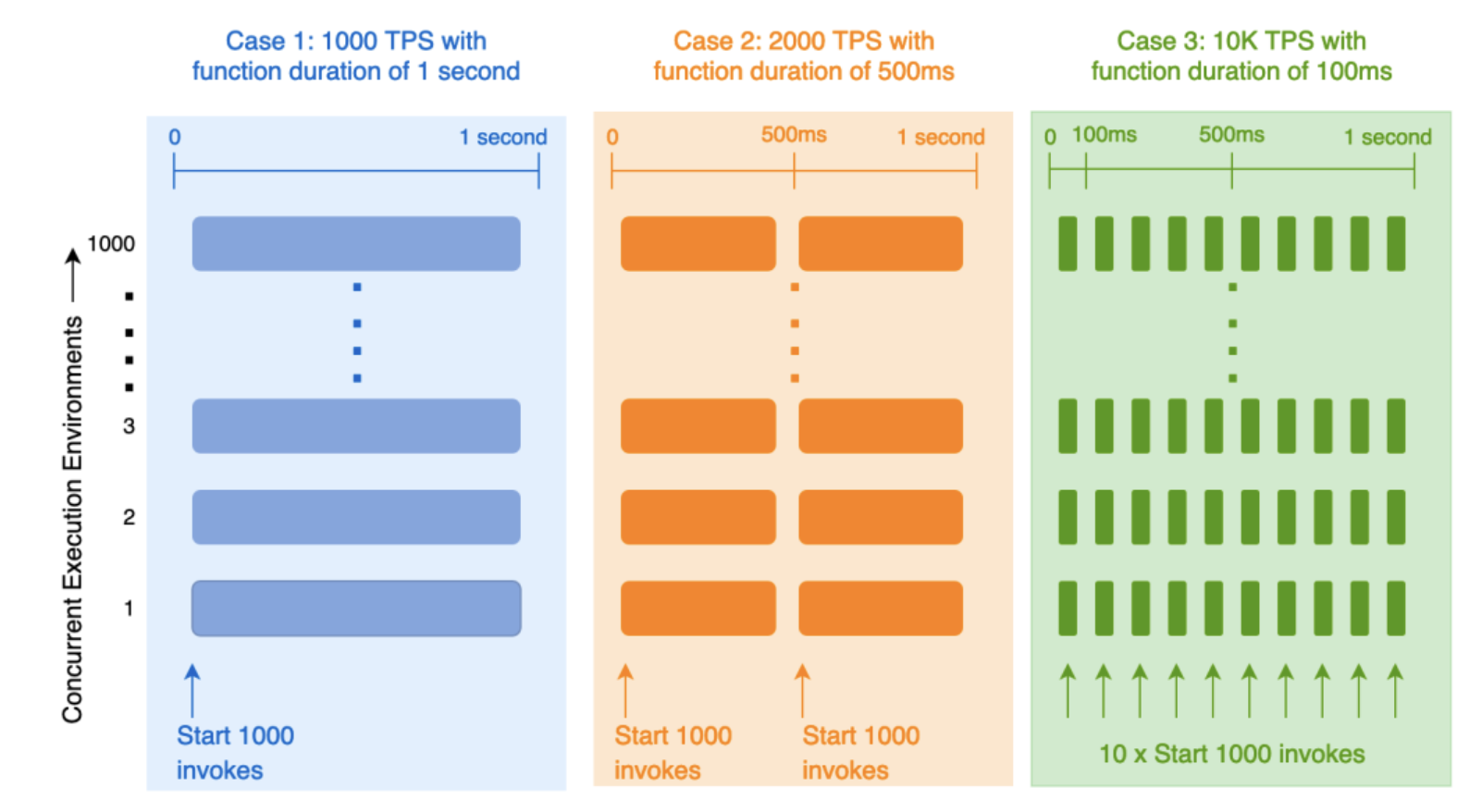
The diagram above considers three cases, each with a different function invocation duration, but a fixed concurrency limit of 1000.
- In the first case, invocations have a constant duration of 1 second.
- This means can initiate 1000 invokes and claim all 1000 execution environments permitted by the concurrency limit.
- These execution environments remain busy for the entire second, and cannot start any more invokes in that second
because the concurrency limit prevents from claiming any more execution environments. - So, the TPS can achieve with a concurrency limit of 1000 and a function duration of 1 second is 1000 TPS.
- In case 2, the invocation duration is halved to 500ms, with the same concurrency limit of 1000.
- it initiate 1000 concurrent invokes at the start of the second as before. These invokes keep the execution environments busy for the first half of the second.
- Once finished, it can start an additional 1000 invokes against the same execution environments while still being within the concurrency limit.
- So, by halving the function duration, doubled the TPS to 2000.
in case 3, if the function duration is 100ms, can initiate 10 rounds of 1000 invokes each in a second, achieving a TPS of 10K.
Taken to an extreme, for a function duration of only 1ms and at a concurrency limit of 1000 (the default limit), an account can drive an invoke TPS of one million.
- For every additional unit of concurrency granted via a limit increase, it implicitly grants an additional 1000 TPS per unit of concurrency increased.
- The high TPS doesn’t require any additional execution environments (Firecracker microVMs), so it’s not problematic from a fleet capacity perspective.
- However, driving over a million TPS from a single account puts stress on the Invoke Data Plane services. They must be protected from noisy neighbor impact as well so all customers have a fair share of the services’ bandwidth.
- A concurrency limit alone isn’t sufficient to protect against this – the TPS limit provides this protection.
Codifying this as an equation:
the TPS can achieve given a concurrency limit is:
- TPS = concurrency / function duration in seconds
As of this writing, the invoke TPS is capped at 10 times the concurrency. Added to the previous equation:
- TPS = min( 10 x concurrency, concurrency / function duration in seconds)
The concurrency factor is common across both terms in the min function, so the key comparison is:
- min(10, 1 / function duration in seconds)
Limits for functions less than 100ms
- If the function duration is exactly 100ms (or 1/10th of a second), both terms in the min function are equal.
- If the function duration is over 100ms, the second term is lower and TPS is limited as per concurrency/function duration.
- If the function duration is under 100ms, the first term is lower and TPS is limited as per 10 x concurrency.
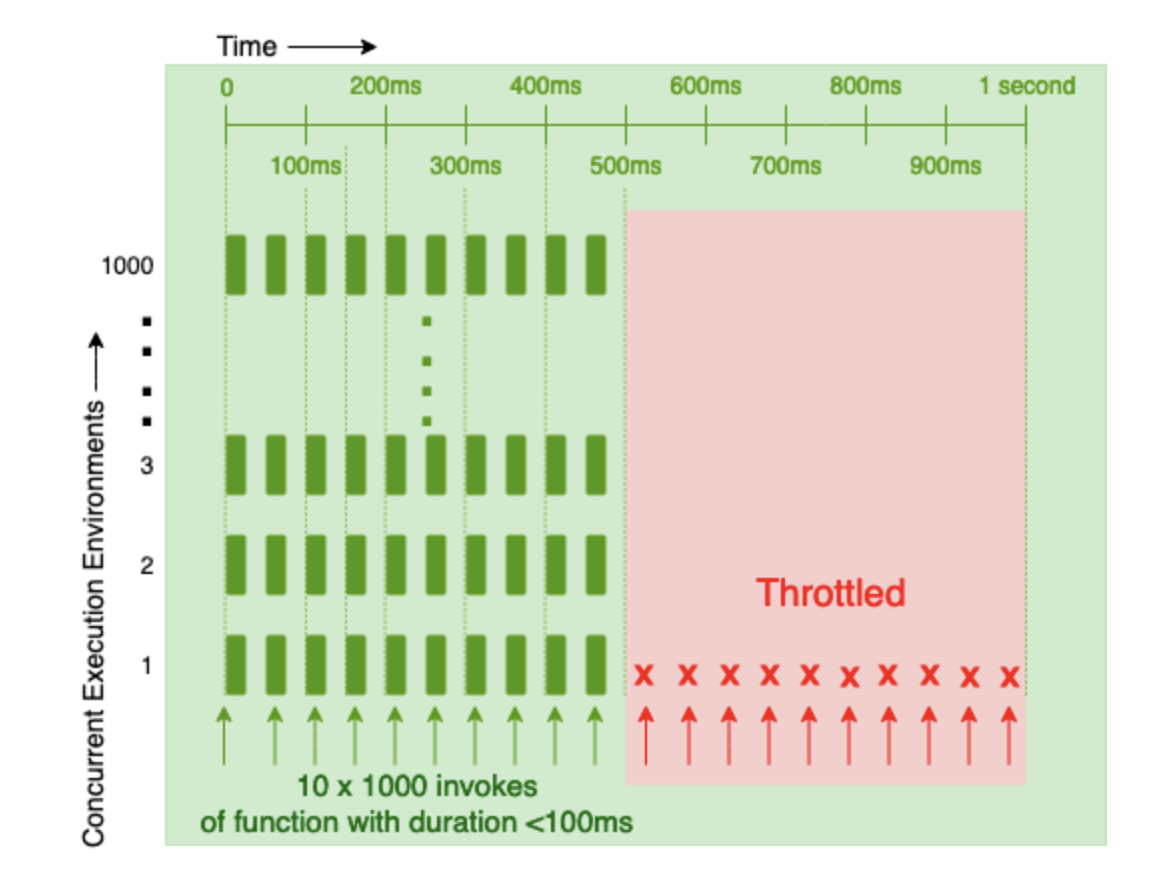
- To summarize, the TPS limit exists to protect the Invoke Data Plane from the high churn of short-lived invocations, for which the concurrency limit alone affords too high of a TPS.
- If drive short invocations of under 100ms, the throughput is capped as though the function duration is 100ms (at 10 x concurrency) as shown in the diagram above.
- This implies that short lived invocations may be TPS limited, rather than concurrency limited.
- However, if the function duration is over 100ms can effectively ignore the 10 x concurrency TPS limit and calculate the available TPS as concurrency/function duration.
Burst
The third throttle limit is the burst limit.
warm execution environment
- Lambda does not keep execution environments provisioned for the entire concurrency limit at all times. That would be wasteful, especially if usage peaks are transient, as is the case with many workloads. Instead, the service spins up execution environments just-in-time as the invoke arrives, if one doesn’t already exist. Once an execution environment is spun up, it remains “warm” for some period of time and is available to host subsequent invocations of the same function version.
cold start
- if an invoke doesn’t find a warm execution environment, it experiences a “cold start” while we provision a new execution environment.
- Cold starts involve certain additional operations over and above the warm invoke path, such as downloading the code or container and initializing the application within the execution environment.
- These initialization operations are typically computationally heavy and so have a lower throughput compared to the warm invoke path. If there are sudden and steep spikes in the number of cold starts, it can put pressure on the invoke services that handle these cold start operations, and also cause undesirable side effects for the application such as increased latencies, reduced cache efficiency and increased fan out on downstream dependencies.
- The burst limit exists to protect against such surges of cold starts, especially for accounts that have a high concurrency limit.
- It ensures that the climb up to a high concurrency limit is gradual so as to smooth out the number of cold starts in a burst.
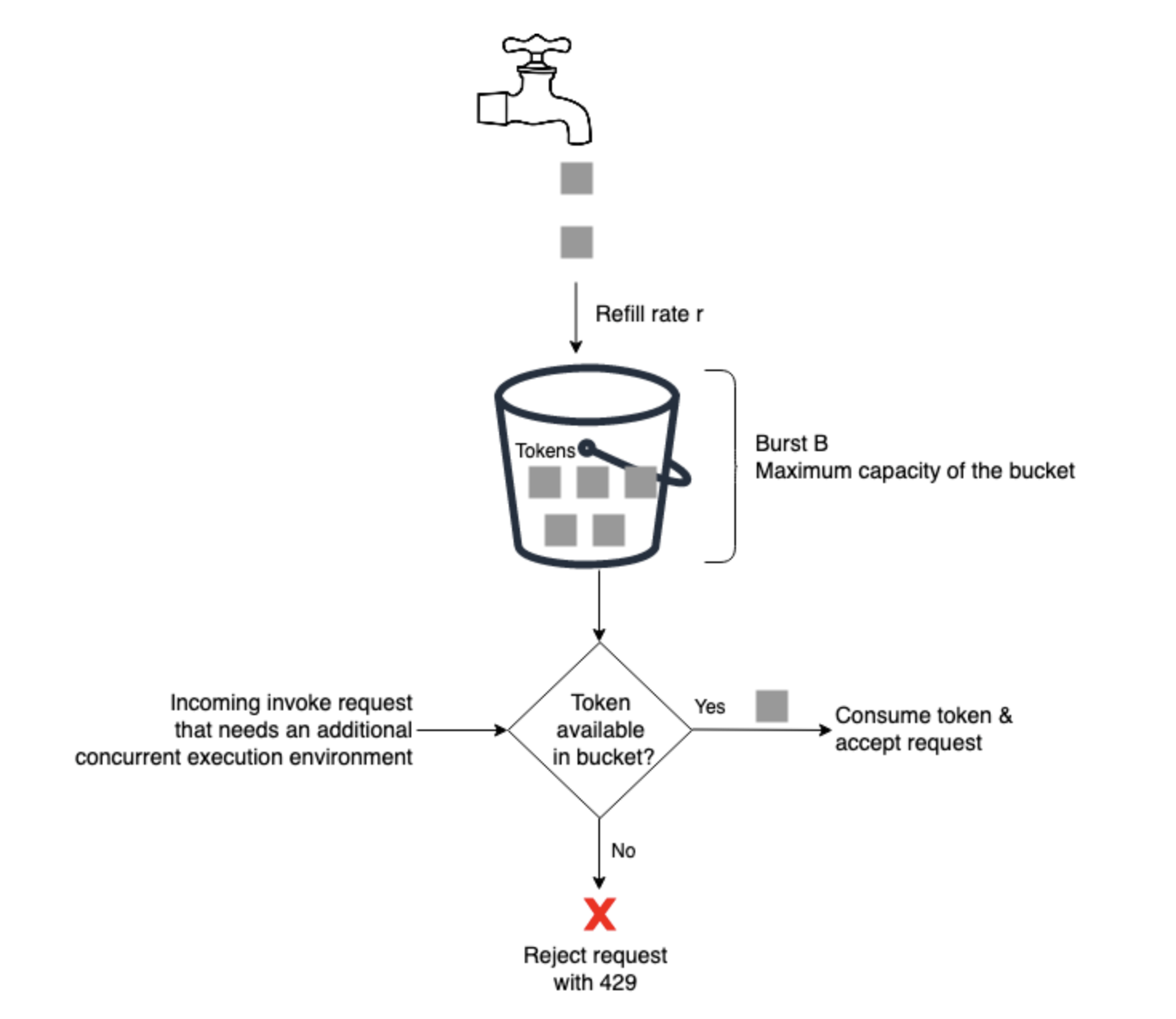
Token Bucket rate-limiting algorithm
- The algorithm used to enforce the burst limit
- Consider a bucket that holds tokens.
- The bucket has a maximum capacity of B tokens (burst).
- The bucket starts full. Each time send an invoke request that requires an additional unit of concurrency, it costs a token from the bucket.
- If the token exists, are granted the additional concurrency and the token is removed from the bucket.
- The bucket is refilled at a constant rate of
r tokens per minute (rate)until it reaches its maximum capacity.
- the rate of climb of concurrency is limited to
r tokens per minute.- Even though the algorithm allows to collect up to B tokens and burst, must wait for the bucket to refill before can burst again, effectively limiting the average rate to r per minute.
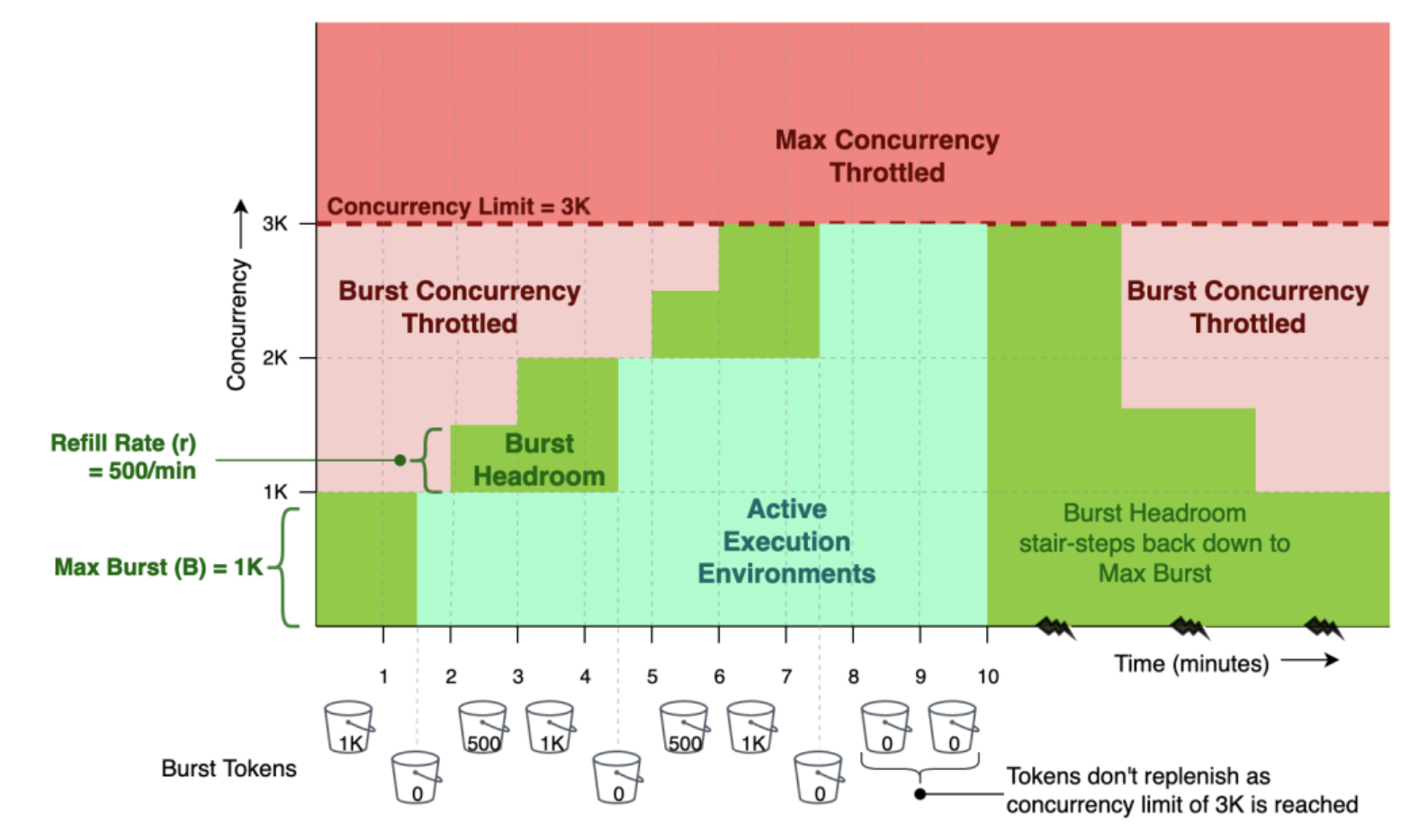
The chart above shows the burst limit in action with a maximum concurrency limit of 3000, a maximum burst(B) of 1000 and a refill rate(r) of 500/minute. The token bucket starts full with 1000 tokens, as is the available burst headroom.
There is a burst activity between minute one and two, which consumes all tokens in the bucket and claims all 1000 concurrent execution environments allowed by the burst limit. At this point the bucket is empty and any attempt to claim additional concurrent execution environments is burst throttled, in spite of max concurrency not being reached yet.
The token bucket and the burst headroom are replenished at minutes two and three with 500 tokens each minute to bring it back up to its maximum capacity of 1000. At minute four, there is no additional refill because the bucket is at maximum capacity. Between minutes four and five, there is a second burst activity which empties the bucket again and claims an additional 1000 execution environments, bringing the total number of active execution environments to 2000.
The bucket continues to replenish at a rate of 500/minute at minutes five and six. At this point, sufficient tokens have been accumulated to cover the entire concurrency limit of 3000, and so the bucket isn’t refilled anymore even when have the third burst activity at minute seven. At minute ten, when all the usage ramps down, the available burst headroom slowly stair steps back down to the maximum initial burst of 1K.
The actual numbers for maximum burst and refill rate vary by Region and are subject to change, please visit the Lambda burst limits page for specific values.
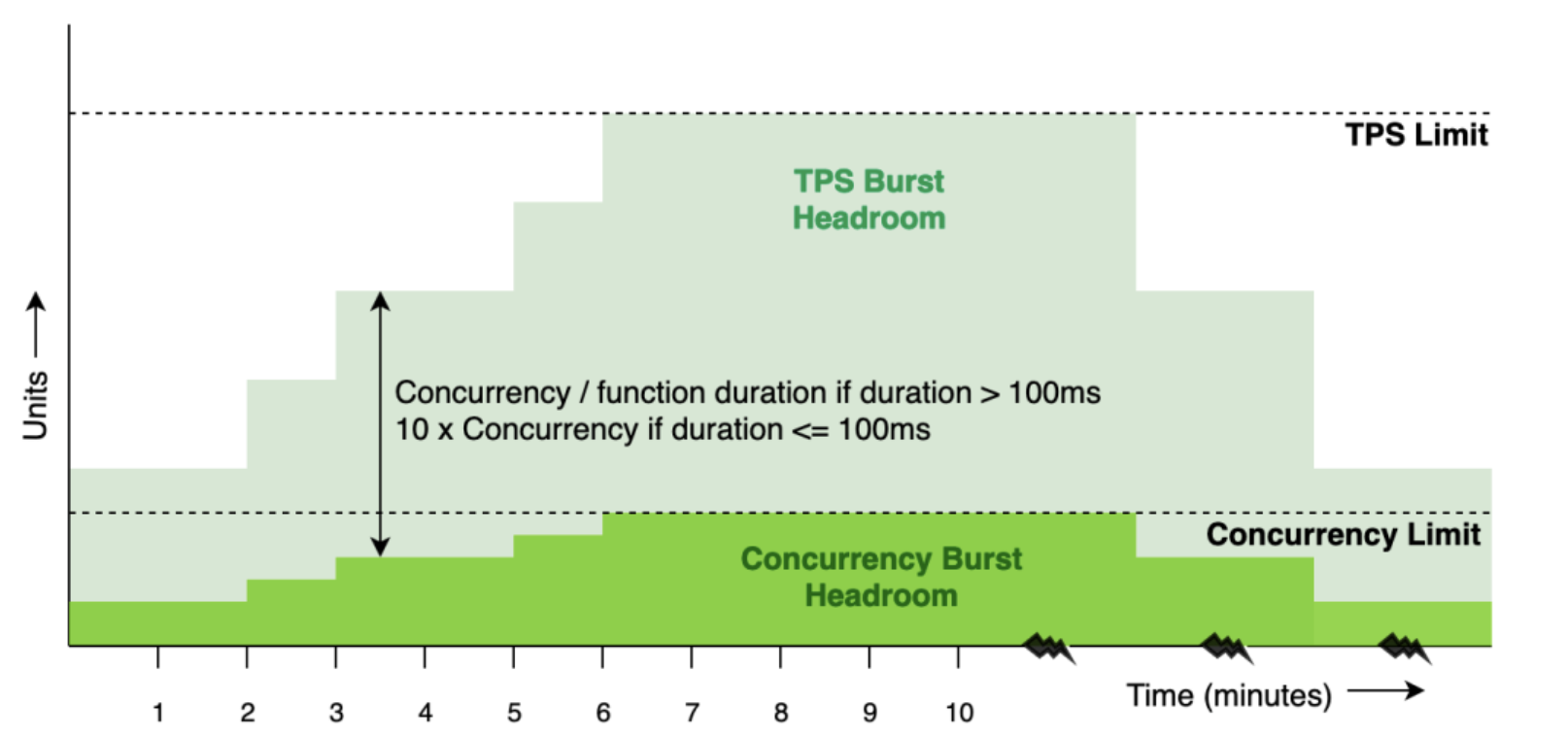
It is important to distinguish that the burst limit isn’t a rate limit on the invoke itself, but a rate limit on how quickly concurrency can rise. However, since invoke TPS is a function of concurrency, it also clamps how quickly TPS can rise (a rate limit for a rate limit). The following chart shows how the TPS burst headroom follows a similar stair step pattern as the concurrency burst headroom, only with a multiplier.
solution
Reserved Concurreny
- 创建新的Lambda:
- 在Lambda的Configuration -> Concurrency页面,进行编辑,设置Reserved concurrency:
- 为了测试Throttle效果,我们把Reserve concurrency设置成0,这样最多同时只有0个函数执行 = 无法执行,永远被throttle:
- 保存后,创建一个测试事件。再运行测试,提示invoke API Rate Exceeded:
- 将Reserve concurrency更改为20,可以看到unreserved account concurrency变为980:
- 注意Unreserved account concurrency值不能低于100:
- 总结:
- 设置Reserved Concurrency并不会带来额外的花费
- 当某个Lambda设置了reserved concurrency后,其他函数就不能使用该concurrency了(参考上图的案例:1000-20 = 980)
Comments powered by Disqus.