LLM - Evaluation
Evaluation
Table of contents:
Overview
Model evaluation
In traditional machine learning, assess how well a model is doing by looking at its performance on training and validation data sets where the output is already known.
- calculate simple metrics such as accuracy, which states the fraction of all predictions that are correct
- because the models are deterministic.

But with large language models
- the output is non-deterministic and language-based
evaluation is much more challenging.
- Example:
- the sentence, Mike really loves drinking tea. This is quite similar to Mike adores sipping tea. But how do you measure the similarity?
other two sentences. Mike does not drink coffee, and Mike does drink coffee. There is only one word difference between these two sentences. However, the meaning is completely different.
Now, for humans like us with squishy organic brains, we can see the similarities and differences. But when you train a model on millions of sentences, you need an automated, structured way to make measurements.

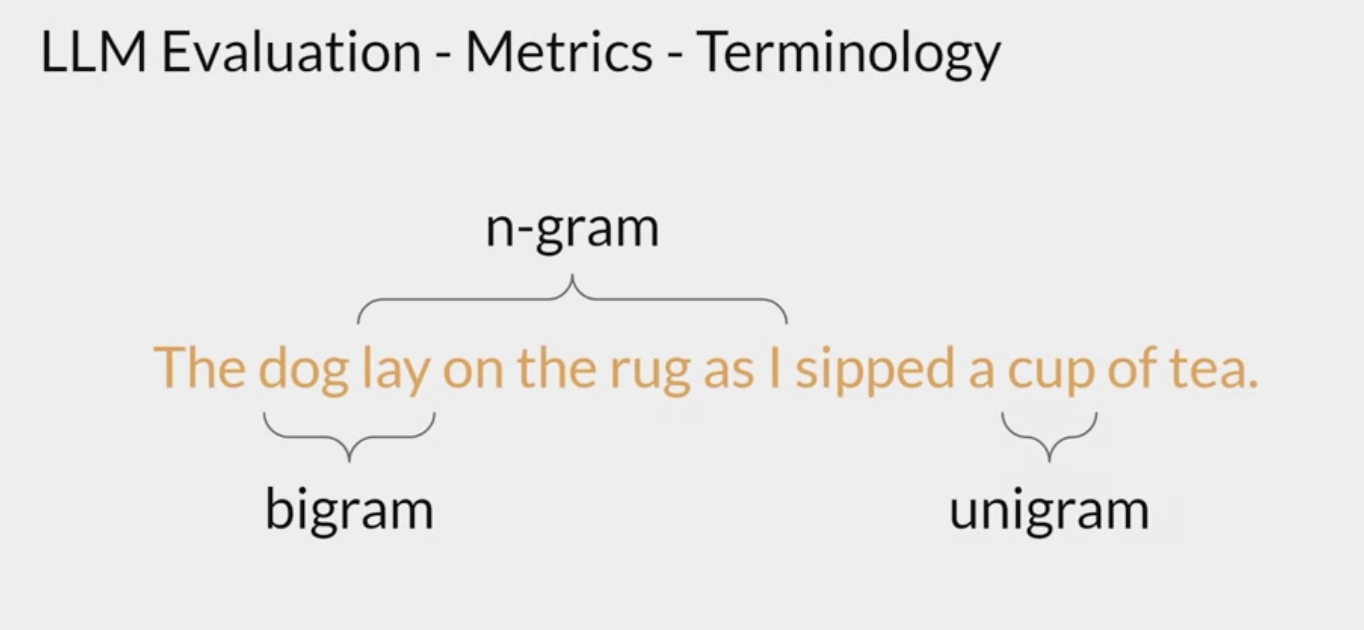
evaluation terminology
terminology
- unigram: equivalent to a single word.
- bigram: two words
- n-gram is a group of n-words.
evaluation metrics
ROUGE and BLEU, are two widely used evaluation metrics for different tasks.
- Both rouge and BLEU are quite simple metrics and are relatively low-cost to calculate.
- You can use them for simple reference as you iterate over the models,
- you shouldn’t use them alone to report the final evaluation of a large language model.
- Use rouge for diagnostic evaluation of summarization tasks
- use BLEU for translation tasks.
ROUGE
- Recall Oriented Understudy for Gisting Evaluation
- primarily employed to assess the quality of automatically generated summaries by comparing them to human-generated reference summaries.
- ROUGE-1 measures the number of word matches between the reference and generated output, while ROUGE-2 considers bigram matches.
BLEU
- bilingual evaluation understudy
- an algorithm designed to evaluate the quality of machine-translated text, again, by comparing it to human-generated translations.
- BLEU is French for blue. You might hear people calling this blue
ROUGE
ROUGE-1 metric
These are very basic metrics that only focused on individual words and don’t consider the ordering of the words.
- It can be deceptive.
It’s easily possible to generate sentences that score well but would be subjectively poor.
- imagine that the sentence generated by the model was different by just one word.
- it is not cold outside.
- The scores would be the same.

ROUGE-2 metric
taking into account bigrams or collections of two words at a time from the reference and generated sentence.
By working with pairs of words you’re acknowledging in a very simple way, the ordering of the words in the sentence.
the scores are lower than the ROUGE-1 scores.
With longer sentences, they’re a greater chance that bigrams don’t match, and the scores may be even lower.

ROUGE-l metric
Rouge-L score:
recall: measures the number of words or unigrams that are matched between the reference and the generated output, divided by the number of words or unigrams in the reference.precision: measures the unigram matches divided by the output size.F1: the harmonic mean of both of these values.
Rather than continue on with ROUGE numbers growing bigger to n-grams of three or fours, let’s look for the longest common subsequence present in both the generated output and the reference output.
In this case, the longest matching sub-sequences are,
it isandcold outside, each with a length of two.now use the LCS value to calculate the recall precision and F1 score, where the numerator in both the recall and precision calculations is the length of the longest common subsequence, in this case, two.

As with all of the rouge scores, you need to take the values in context.
You can only use the scores to compare the capabilities of models if the scores were determined for the same task.
- For example, summarization.
- Rouge scores for different tasks are not comparable to one another.
problem with simple rouge scores: it’s possible for a bad completion to result in a good score.
for example
generated output: cold, cold, cold, cold.
- The Rouge-1 precision score will be perfect.
- As this generated output contains one of the words from the reference sentence, it will score quite highly, even though the same word is repeated multiple times.
- One way to counter this issue: use clipping function to limit the number of unigram matches to the maximum count for that unigram within the reference.
- there is one appearance of
coldand the reference and so a modified precision with a clip on the unigram matches results in a dramatically reduced score. 
- there is one appearance of
- However, you’ll still be challenged if their generated words are all present, but just in a different order.
- For example, with this generated sentence, outside cold it is.
- This sentence was called perfectly even on the modified precision with the clipping function as all of the words and the generated output are present in the reference.

- Whilst using a different rouge score can help experimenting with a n-gram size that will calculate the most useful score will be dependent on the sentence, the sentence size, and the use case.
BLEU
BLEU
- bilingual evaluation under study.
- useful for evaluating the quality of
machine-translated text quantifies the quality of a translation by checking how many n-grams in the machine-generated translation match those in the reference translation.
- The score itself is calculated using the average precision over multiple n-gram sizes.
- like the Rouge-1 score, but calculated for a range of n-gram sizes and then averaged.
- To calculate the score, you average precision across a range of different n-gram sizes.
- carry out multiple calculations and then average all of the results to find the BLEU score.
- Calculating the BLEU score is easy with pre-written libraries from providers like Hugging Face.
For example,
- The reference human-provided sentence: I am very happy to say that I am drinking a warm cup of tea.
- The first candidate: I am very happy that I am drinking a cup of tea. The BLEU score is 0.495.
- As we get closer and closer to the original sentence, we get a score that is closer and closer to one.

benchmarks
LLMs are complex, and simple evaluation metrics like the rouge and blur scores, can only tell you so much about the capabilities of the model.
make use of pre-existing datasets, and associated benchmarks that have been established.
to measure and compare LLMs more holistically
Selecting the
right evaluation datasetis vital, to accurately assess an LLM’s performance, and understand its true capabilities.select datasets that isolate specific model skills, like reasoning or common sense knowledge, and those that focus on potential risks, such as disinformation or copyright infringement.
consider whether the model has seen the evaluation data during training.
- get a more accurate and useful sense of the model’s capabilities by evaluating its performance on data that it hasn’t seen before.
Benchmarks cover a wide range of tasks and scenarios.
- They do this by designing or collecting datasets that test specific aspects of an LLM.
benchmarks that are pushing LLMs further.

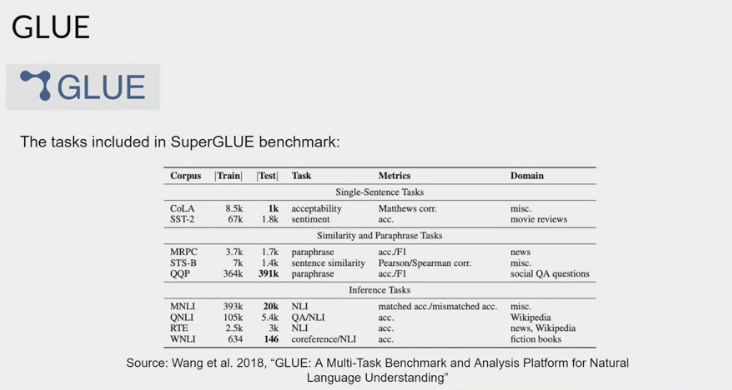
- GLUE:
- General Language Understanding Evaluation
- introduced in 2018.
- a collection of natural language tasks, such as sentiment analysis and question-answering.
- to encourage the development of models that can generalize across multiple tasks
- use the benchmark to measure and compare the model performance.
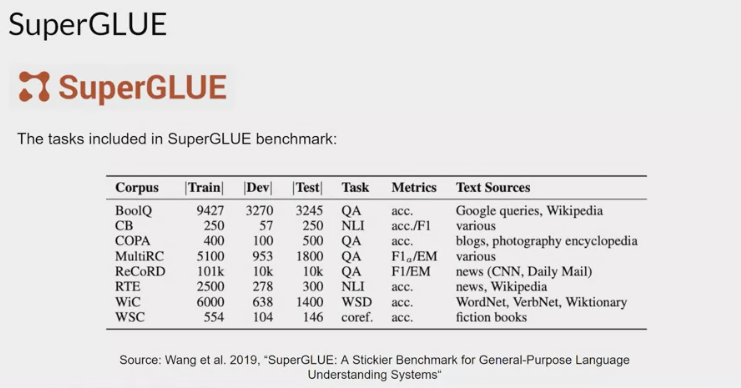
- SuperGLUE:
- introduced in 2019
- to address limitations in its predecessor.
- It consists of a series of tasks, which are not included in GLUE, or more challenging versions of the same tasks.
- includes tasks such as multi-sentence reasoning, and reading comprehension. Both the GLUE and SuperGLUE benchmarks have leaderboards that can be used to compare and contrast evaluated models.
- As models get larger, their performance against benchmarks such as SuperGLUE start to match human ability on specific tasks.
- models are able to perform as well as humans on the benchmarks tests, but subjectively we can see that they’re not performing at human level at tasks in general.
- an arms race between the emergent properties of LLMs, and the benchmarks that aim to measure them.
- MMLU:
- Massive Multitask Language Understanding
designed specifically for modern LLMs.
- To perform well models must possess extensive world knowledge and problem-solving ability.
- Models are tested on tasks that extend way beyond basic language understanding.
elementary mathematics, US history, computer science, law, and more.

- BIG-bench
consists of 204 tasks, ranging through
linguistics, childhood development, math, common sense reasoning, biology, physics, social bias, software development and more.BIG-bench comes in three different sizes, and part of the reason for this is to keep costs achievable, as running these large benchmarks can incur large inference costs.
- HELM:
- Holistic Evaluation of Language Models
- aims to improve the transparency of models, and to offer guidance on which models perform well for specific tasks.
- HELM takes a multimetric approach, measuring seven metrics across 16 core scenarios, ensuring that trade-offs between models and metrics are clearly exposed.
- it assesses on metrics beyond basic accuracy measures, like precision of the F1 score.
- includes metrics for fairness, bias, and toxicity, which are becoming increasingly important to assess as LLMs become more capable of human-like language generation, and in turn of exhibiting potentially harmful behavior.
- a living benchmark that aims to continuously evolve with the addition of new scenarios, metrics, and models.

other
computation-based evaluation pipeline
evaluate the performance of foundation models and tuned models
- evaluated using a set of metrics against the evaluation dataset
evaluation dataset
- create an evaluation dataset that contains prompt and ground truth pairs.
- For each pair, the prompt is the input that you want to evaluate, and the ground truth is the ideal response for that prompt.
- During evaluation, the prompt in each pair of the evaluation dataset is passed to the model to produce an output.
The output generated by the modelandthe ground truth from the evaluation datasetare used to compute the evaluation metrics.
dataset must include a minimum of 1 prompt and ground truth pair and at least 10 pairs for meaningful metrics.
- The more examples you give, the more meaningful the results.
The type of metrics used for evaluation depends on the task that you are evaluating.
| Task | Metric |
|---|---|
| Classification | Micro-F1, Macro-F1, Per class F1 |
| Summarization | ROUGE-L |
| Question answering | Exact Match |
| Text generation | BLEU, ROUGE-L |
Recall-Oriented Understudy for Gisting Evaluation (ROUGE):
A metric used to evaluate the quality of automatic summaries of text. It works by comparing a generated summary to a set of reference summaries created by humans.
take the candidate and reference to evaluate the performance. In this case, ROUGE will give you:
rouge-1, which measures unigram overlap 单字重叠rouge-2, which measures bigram overlap 二元组重叠rouge-l, which measures the longest common subsequence 最长公共子序列
Recall vs. Precision
Recall: prioritizes how much of the information in the reference summaries is captured in the generated summary.
Precision: how much of the generated summary is relevant to the original text.
Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from google.auth import default
import vertexai
from vertexai.preview.language_models import (
EvaluationTextClassificationSpec,
TextGenerationModel,
)
# Set credentials for the pipeline components used in the evaluation task
credentials, _ = default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
def evaluate_model(project_id: str, location: str) -> object:
"""Evaluate the performance of a generative AI model."""
vertexai.init(project=project_id, location=location, credentials=credentials)
# Create a reference to a generative AI model
model = TextGenerationModel.from_pretrained("text-bison@002")
# Define the evaluation specification for a text classification task
task_spec = EvaluationTextClassificationSpec(
ground_truth_data=[
"gs://cloud-samples-data/ai-platform/generative_ai/llm_classification_bp_input_prompts_with_ground_truth.jsonl"
],
class_names=["nature", "news", "sports", "health", "startups"],
target_column_name="ground_truth",
)
# Evaluate the model
eval_metrics = model.evaluate(task_spec=task_spec)
print(eval_metrics)
return eval_metrics
Sample
LlamaIndex
1
2
3
4
5
6
7
8
from deepeval.integrations.llama_index import (
DeepEvalAnswerRelevancyEvaluator,
DeepEvalFaithfulnessEvaluator,
DeepEvalContextualRelevancyEvaluator,
DeepEvalSummarizationEvaluator,
DeepEvalBiasEvaluator,
DeepEvalToxicityEvaluator,
)
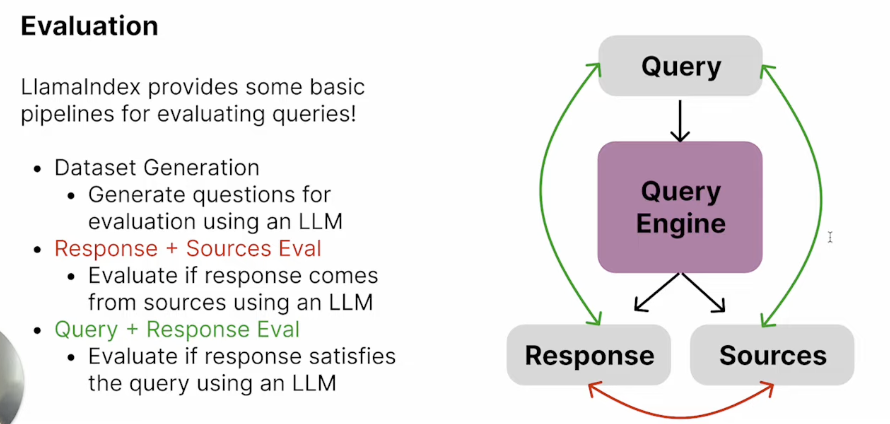
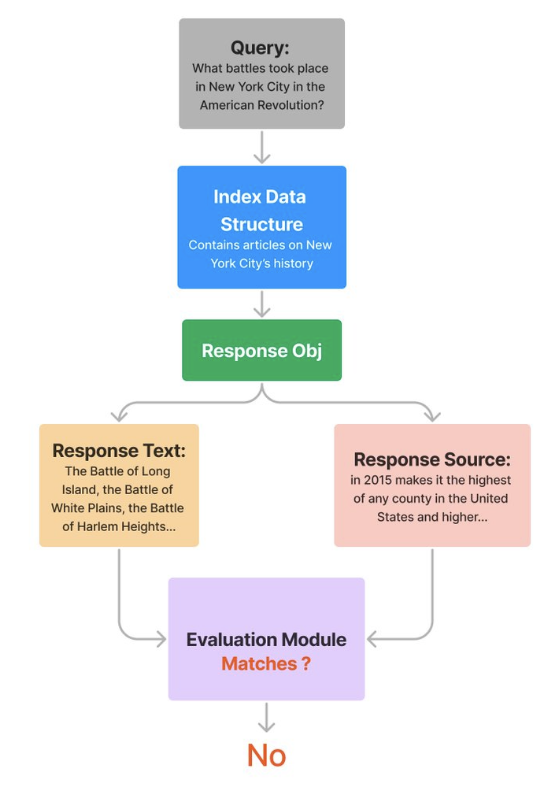
Evaluating Response Faithfulness (i.e. Hallucination)
- The
FaithfulnessEvaluatorevaluates if the answer is faithful to the retrieved contexts (in other words, whether if there’s hallucination).
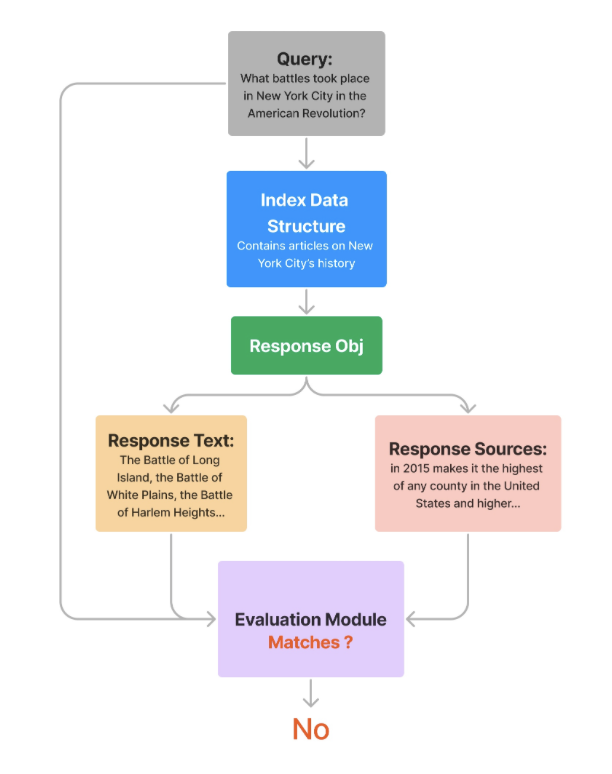
Evaluating Query + Response Relevancy
- The
RelevancyEvaluatorevaluates if the retrieved context and the answer is relevant and consistent for the given query.
Comments powered by Disqus.