LLM - Data Tuning Type
LLM - Data Tuning Type
Table of contents:
- LLM - Data Tuning Type
Fine-T vs Prompt-T vs Instruction-T
Fine-Tuning:
- 先在大规模语料上进行预训练,然后再在某个下游任务上进行微调,
- 如 Bert+Fine-Tuning
Prompt-Tuning:
- 先选择某个通用的大规模预训练模型,然后为具体的任务
生成一个prompt模板以适应大模型进行微调, - 如 GPT-3+Prompt-Tuning;
- 先选择某个通用的大规模预训练模型,然后为具体的任务
Instruction-Tuning:
- 仍然在预训练语言模型的基础上,先在多个已知任务上进行指令微调,然后在某个新任务上进行 zero-shot,
- 如 GPT-3+Instruction-Tuning
要提出一个好的方式那必然是用来「解决另一种方式存在的缺陷或不足」
Prompt-Tuning vs Fine-Tuning
预训练模型 PLM+Fine-Tuning 范式
- 这个范式常用的结构是 Bert+Fine-Tuning,这种范式若想要预训练模型更好的应用在下游任务,需要利用下游数据对模型参数微调;
- 首先,模型在预训练的时候,采用的训练形式: 自回归 自编码,这与下游任务形式存在极大的 gap,不能完全发挥预训练模型本身的能力,必然导致较多的数据来适应新的任务形式(少样本学习能力差 容易过拟合)。
- 其次,现在的预训练模型参数量越来越大,为了一个特定的任务去 Fine-Tuning 一个模型,会占用特别多的训练资源,对一些中小企业或者用户来说并不现实,也会造成资源的一定浪费。
Prompt-Tuning 是在 Fine-Tuning 后发展起来的,可以说是解决 NLP 领域各种下游问题更好的一种方式。
- Prompt-Tuning 则很好的解决了这些问题,它将所有下游任务统一成预训练任务,以特定的模板,将下游任务的数据转成自然语言形式,充分挖掘预训练模型本身的能力。本质上就是设计一个比较契合上游预训练任务的模板,通过模板的设计来挖掘出上游预训练模型的潜力,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务,即只需要少量数据的 Prompt Tuning,就可以实现很好的效果,具有较强的零样本/少样本学习能力。
- Prompt-Tuning VS Fine-Tuning。
Prompt-Tuning vs Instruction-Tuning:

Prompt 和 instruction 都是指导语言模型生成输出的文本片段,但它们有着不同的含义和用途。
Prompt 更多地用于帮助模型理解任务和上下文,而 Instruction 则更多地用于指导模型执行具体操作或完成任务。
- Prompt:
- 通常是一种短文本字符串,用于指导语言模型生成响应。
- Prompt 提供上下文和任务相关信息,以帮助模型更好地理解要求,并生成正确的输出。
- Prompt 通常是人类设计的,以帮助模型更好地理解特定任务或领域;
- 例如,在问答任务中,prompt 可能包含问题或话题的描述,以帮助模型生成正确的答案。
- 通常是一种短文本字符串,用于指导语言模型生成响应。
- Instruction
- 通常是一种更详细的文本,用于指导模型执行特定操作或完成任务。
- Instruction 可以是计算机程序或脚本,也可以是人类编写的指导性文本。
- Instruction 的目的是告诉模型如何处理数据或执行某个操作,而不是简单地提供上下文或任务相关信息。
prompt 在没精调的模型上也能有一定效果(模型不经过 Prompt-Tuning,直接针对下游任务进行推理),而 Instruction-Tuning 则必须对模型精调,让模型知道这种指令模式。
- 但是,prompt 也有精调,经过 Prompt-Tuning 之后,模型也就学习到了这个 prompt 模式,
- 精调之后跟 Instruction-Tuning 有什么区别呢?这就是 Instruction-Tuning 巧妙的地方了,
- Prompt-Tuning 都是针对一个任务的,比如做个情感分析任务的 Prompt-Tuning,精调完的模型只能用于情感分析任务,
- 而经过 Instruction-Tuning 多任务精调后,可以用于其他任务的 zero-shot。
两者的对比主要是基于大模型。
Prompt 是通过对任务进行一定的描述,或者给一些示例(ICL),来完成既定任务目标,但是如果不给模型示例(zero-shot)
prompt 表现的很一般,这怎么办呢?能不能让大模型理解任务是做什么的,这样不用示例也能完成任务目标,instruction 就是来做这个任务的,它为了让模型具备理解任务的能力,采用大量的指令数据,对模型进行微调,即 Instruction-Tuning。
因此,instruction 和 prompt 的不同之处在于: instruction 是在 prompt 的基础上,进一步挖掘模型理解任务的能力
Hard / Soft Prompt
Hard Prompt 和 Soft Prompt 的提出,是为了解决预训练模型过大,难以针对下游任务进行训练的痛点。
目前常见的 Hard Prompt 和 Soft Prompt 方法,分为以下五种:
Hard Prompt:
- 人工构建(Manual Template): 最简单的构建模板方法;
- 启发式法(Heuristic-based Template): 通过规则 启发式搜索等方法构建合适的模板;
- 生成(Generation): 根据给定的任务训练数据(通常是小样本场景),生成出合适的模板;
Soft Prompt:
- 词向量微调(Word Embedding): 显式地定义离散字符的模板,但在训练时这些模板字符的词向量参与梯度下降,初始定义的离散字符用于作为向量的初始化;
- 伪标记(Pseudo Token): 不显式地定义离散的模板,而是将模板作为可训练的参数。
Hard Prompt:
- 前面三种称为离散的模板构建法(记作 Hard Template Hard Prompt Discrete Template Discrete Prompt),其旨在
直接与原始文本拼接显式离散的字符,且在训练中始终保持不变。 - 这里的保持不变是指这些离散字符的词向量(Word Embedding)在训练过程中保持固定。
- 通常情况下,离散法不需要引入任何参数。
- 主要适用场景是 GPT-3 类相对较大的模型,Bert 类相对较小的模型也可以用,只是个人觉得 Bert 等预训练模型,针对下游任务训练的成本并不是很高,完全可以同时微调预训练模型参数。
- 上述三种 Hard Prompt 方法,实际场景中用的比较少
- Hard Prompt 方法,不论是启发式方法,还是通过生成的方法,都需要为每一个任务单独设计对应的模板,因为这些模板都是可读的离散的 token
- 这导致很难寻找到最佳的模板。
- 另外,即便是同一个任务,不同的句子也会有其所谓最佳的模板,而且有时候,即便是人类理解的相似的模板,也会对模型预测结果产生很大差异。
- 例如下图,以 SNLI 推断任务为例,仅仅只是修改了模板,测试结果差异很明显,因此离散的模板存在方差大 不稳定等问题。

- 如何避免这种问题呢,Soft Prompt 方法便是来解决这种问题的,
- 前面三种称为离散的模板构建法(记作 Hard Template Hard Prompt Discrete Template Discrete Prompt),其旨在
Soft Prompt:
- 后面两种则被称为连续的模板构建法(记作 Soft Template Soft Prompt Continuous Template Continuous Prompt),其旨在让模型在训练过程中
根据具体的上下文语义和任务目标对模板参数进行调整。 - 其将模板转换为可以进行优化的连续向量
我们不需要显式地指定这些模板中各个 token 具体是什么,只需要在语义空间中表示一个向量即可,这样,不同的任务 数据可以自适应地在语义空间中寻找若干合适的向量,来代表模板中的每一个词,相较于显式的 token,这类 token 称为伪标记(
Pseudo Token)。基于 Soft Prompt 的模板定义:
假设针对分类任务,给定一个输入句子 $x$ , 连续提示的模板可以定义为: $\mathcal{T} =[x],[v_{1}],[v_{2}],…,[v_{m}][Mask]$ 其中 $[v_{1}]$ 则是伪标记,其仅代表一个抽象的 token,并没有实际的含义,本质上是一个向量。
总结来说:
- Soft Prompt 方法,是将模板变为可训练的参数,不同的样本可以在连续的向量空间中寻找合适的伪标记,同时也增加模型的泛化能力。
- 因此,连续法需要引入少量的参数并在训练时进行参数更新,但预训练模型参数是不变的,变的是 prompt token 对应的词向量(Word Embedding)表征及其他引入的少量参数。
- 主要适用场景同 Hard Prompt 一致。
- 目前具有代表性的三种 Soft Prompt 方法如下:
- 后面两种则被称为连续的模板构建法(记作 Soft Template Soft Prompt Continuous Template Continuous Prompt),其旨在让模型在训练过程中
Parameter-Efficient Prompt Tuning (Soft Prompt)
该方法率先提出了伪标记和连续提示的概念,支持模型能够动态地对模板在语义空间内进行调整。
主要针对的是 NLU 任务,形式化的描述如下:
给定 $n$ 个 token,记作 $x_{1}, …, x_{n}$, 通过一个预训练模型对应的 embedding table,将 $n$ 个 token 表征为向量矩阵 $X_{e} \in R^{n\times e}$, 其中 $e$ 是向量的维度(其与预训练模型的配置有关,例如 Bert-base 是 768)。 连续模板中的每个伪标记 $v_{i}$ 可以视为参数,也可以视为一个 token,因此,可以通过另一个 embedding table 将 $p$ 个伪标记 token 表征为向量矩阵 $P_{e} \in R^{p\times e}$ 。 将文本和 prompt 进行拼接获得新的输入 $[P_{e} :X_{e}] \in R^{(p+n) \times e}$。 这个新的输入将会进入 T5 的 encoder-decoder 结构来训练和推理。 注意,只有 prompt 对应的向量表征参数 $P_{e}$ 会随着训练进行更新。
论文中提到,每个伪标记的初始化可以有下列三种情况,分别是 Random Uniform,Sampled Vocab 和 Class Label。
- Random Uniform: 从均匀分布中随机进行初始化;
- Sampled Vocab: 从 T5 的语料库中选择最常见的 5000 个词汇,并从中选择词汇嵌入作为初始化;
- Class Label: 是将下游任务的标签对应的字符串表示的嵌入作为初始化,如果一个类有多个词,取词嵌入的平均表示作为一个 prompt。假如标签数目不足,则从 Sampled Vocab 方案中继续采样补足。
最后发现,非随机初始化方法要显著好于随机初始化,而 Class Label 效果相对更好,当然,只要模型足够大,这几种初始化方法的差异就比较小了。
具体论文
P-Tuning (Soft Prompt)
- P-Tuning 是另一个具有代表性的连续提示方法
谷歌于 2021 年发表
- 主要针对的是 NLU 任务
- 方法图: 图中的 $P_{i}$ 等价于上文的 $v_{i}$ ,表示伪标记

P-Tuning 方法中的四个技巧点:
- 考虑到这些伪标记的相互依赖关系: 认为 $[P_{1}]$ 与 $[P_{2}]$ 是有先后关系的,而 transformer 无法显式地刻画这层关系,因此引入 Prompt Encoder(BiLSTM+MLP);
- 指定上下文词: 如果模板全部是伪标记,在训练时无法很好地控制这些模板朝着与对应句子相似的语义上优化,因此选定部分具有与当前句子语义代表性的一些词作为一些伪标记的初始化(例如上图中“capital” “Britain”等);
- 重参数(Reparameterization): 具体到代码实现上,P-Tuning 先通过一个 Prompt Encoder 表征这些伪标记后,直接将这些新的表征覆盖到对应的 embedding table 上,换句话说,Prompt Encoder 只在训练时候会使用到,而在推理阶段则不再使用,直接使用构建好的 embedding table;
- 混合提示(Hydride Prompt): 将连续提示与离散 token 进行混合,例如 $[x][it][v1][mask]$。
- 具体可参考:
Pre-trained Prompt Tuning (PPT) (Soft Prompt)
- Prompt-Tuning 通常适用于低资源场景,但是由于连续的模板是随机初始化的,即其存在新的参数,少量样本可能依然很难确保这些模板被很好地优化。
- 因此简单的方法就是对这些连续的模板进行预训练。
- PPT 旨在通过先让这些连续提示在大量无标注的预训练语料进行预训练,然后将其加载到对应下游任务的 PLM 上进行训练。
- 具体来说,作者对 3 种 Prompt-Tuning 的优化策略在 few-shot learning 问题上分别进行了效果对比,包括 hard prompt 和 soft prompt 结合 label 到 text 映射方法选择以及使用真实单词的 embedding 进行 soft prompt 的随机初始化。通过对比实验发现,hard+soft prompt 结合的方法可以提升效果,但是仍然比 finetune 效果差。
- Label 到 text 的映射方法对于效果影响很大,选择能够表达 label 对应含义的常用单词会带来最好效果。
而使用单词 embedding 进行 soft prompt 的初始化在大模型上并没有明显的效果提升。
基于以上实验结果,作者提出了 Pre-trained Pormpt Tuning 解决 few-shot learning 问题,核心思路是对 soft prompt 进行预训练,得到一个更好的 soft prompt 初始化表示。对于每种类型的任务,设计一个和其匹配的预训练任务,得到 soft prompt embedding 的预训练表示。
论文中以 sentence-pair classification multiple-choice classification single sentence classification 三种任务介绍了如何针对每种下游任务设计预训练任务学习 soft prompt embedding。例如对于 sentence-pair classification,作者设计了如下预训练任务。将 2 个句子对拼接在一起,如果两个句子来自同一个文档相邻两句话,则 label 为 yes(完全一致);如果两个句子来自同一个文档但距离较远,则 label 为 maybe;其他句子对 label 为 no,如下图所示(图中的 P P P 即连续的提示模板, < x >
<x\>表示 mask token。最上面的任务是预训练任务,下面三个任务为下游任务)。 - 另外论文中还给出了四种微调方案,如下图所示,
[a]展示了模型的预训练过程,[b]和[c]展示了两种主流的 Fine-Tuning 方法(前文已经介绍过),[d]展示了提示学习( Prompt Tuning, PT )方法,
- 具体参考

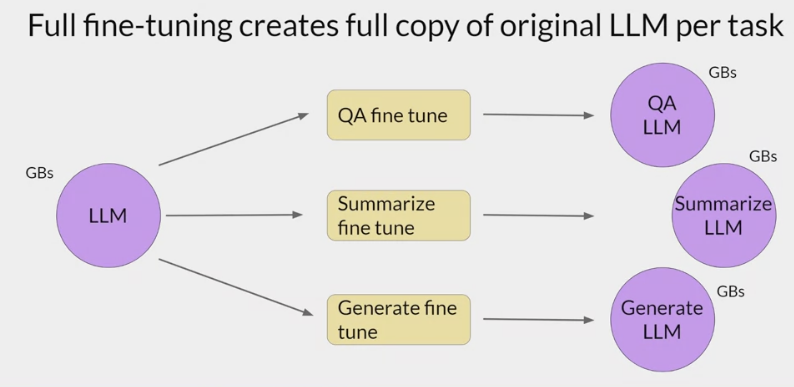
Full / Not Full Fine-Tuning
可以把 Tuning 分为两类:
- 全参数微调:
- 训练过程中更新包括模型在内的所有参数
- 例如
Fine-Tuning,Prompt-Orient Fine-Tuning等;

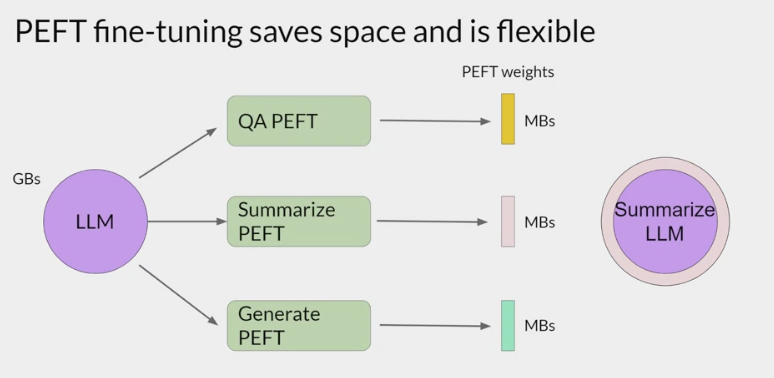
- 部分参数微调:
- 训练过程中只更新
部分模型参数,或者固定模型参数只更新少量额外添加的参数, - 如
Parameter-Efficient Prompt Tuning,P-Tuning,Prompt-Tuning等。
- 训练过程中只更新
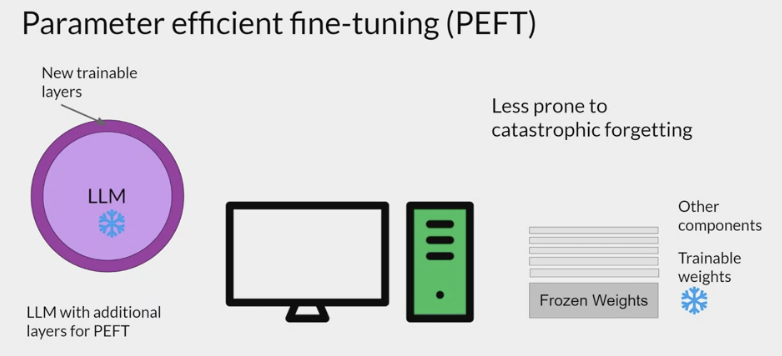
部分参数微调模式的提出:
- 一方面是由于资源限制,无法更新整体大模型参数
另一方面,要保证在资源有限的条件下,能够尽可能的提升大模型在下游任务上的效果。
针对
部分参数微调的研究有个统一的名称: Parameter-Efficient Fine-Tuning (PEFT),即参数有效性微调,PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。
PEFT updates only a small subset of parameters. This helps prevent catastrophic forgetting.
Supervised / UnSupervised learning
监督学习(supervised learning)和非监督学习(unsupervised learning)
监督学习:
- 简单来说就是给定一定的训练样本
- 样本是既有数据,也有数据对应的结果
- 利用这个样本进行训练得到一个模型(可以说是一个函数),然后利用这个模型,将所有的输入映射为相应的输出,之后对输出进行简单的判断从而达到了分类(或者说回归)的问题。
- 分类就是离散的数据,回归就是连续的数据。
非监督学习:
- 同样,给了样本,但是这个样本是只有数据,但是没有其对应的结果,要求直接对数据进行分析建模。
- 比如去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别(比如哪些更朦胧一点,哪些更写实一些,即使我们不知道什么时候叫做朦胧派,什么叫做写实派,但是至少我们能够把它们分为两类)。
- 无监督学习里面典型的例子就是聚类,聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么,因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
比如
- 买房的时候,给了房屋面积以及其对应的价格,进行分析,这个就叫做监督学习;
- 但是给了面积,没有给价格,就叫做非监督学习。
- 监督,意味着给了一个标准作为’监督’ (或者理解为限制)。就是说建模之后是有一个标准用来衡量你的对与错;
- 非监督就是没有这个标准,对数据进行聚类之后,并没有一个标准进行对其的衡量。
Single / Multi task Fine-tuning
Single task Fine-tuning
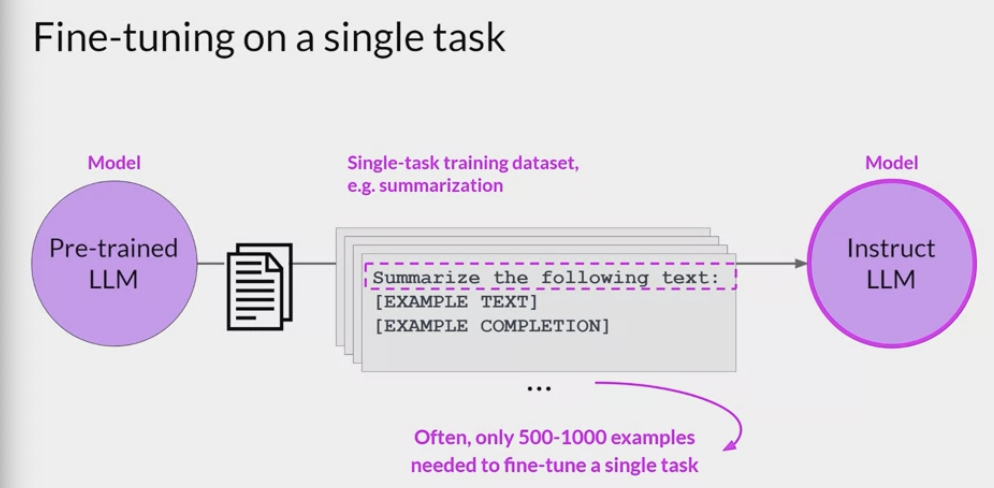
Catastrophic forgetting
Fine-tuning on a single task may lead to a phenomenon called catastrophic forgetting.
Catastrophic forgetting happens because the full fine-tuning process modifies the weights of the original LLM.
- leads to great performance on the single fine-tuning task
- it can degrade performance on other tasks.
Catastrophic forgetting is a problem in both supervised and unsupervised learning tasks.
- In unsupervised learning, it can occur when the model is trained on a new dataset that is different from the one used during pre-training.
For example
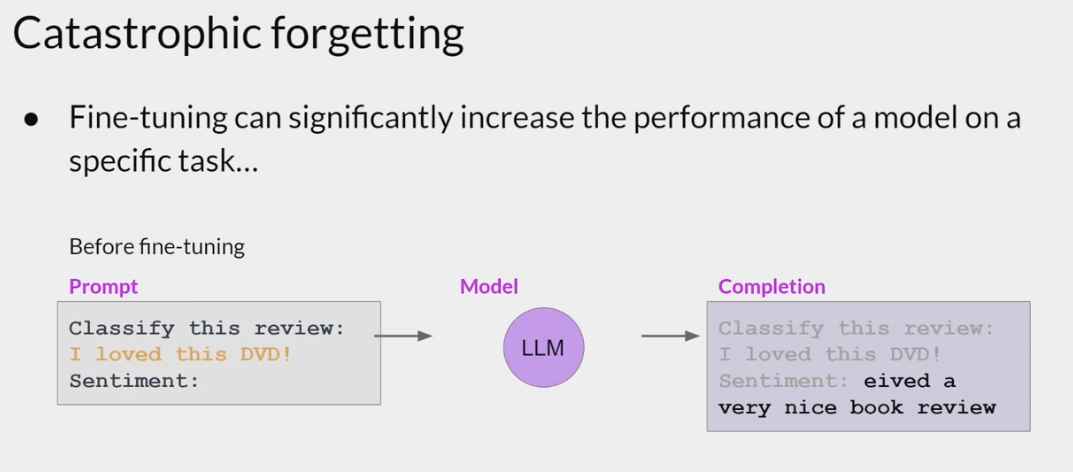
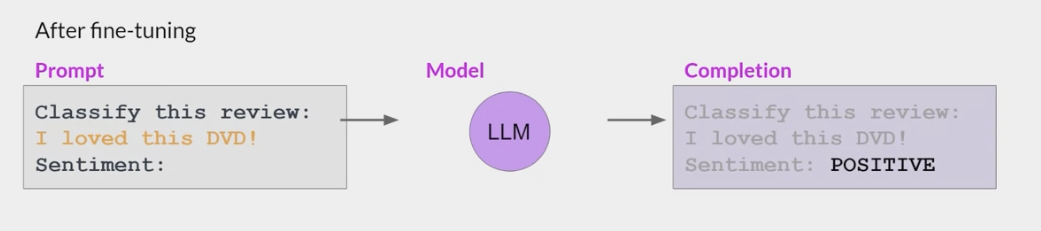
- while fine-tuning can improve the ability of a model to perform sentiment analysis on a review and result in a quality completion, the model may forget how to do other tasks.
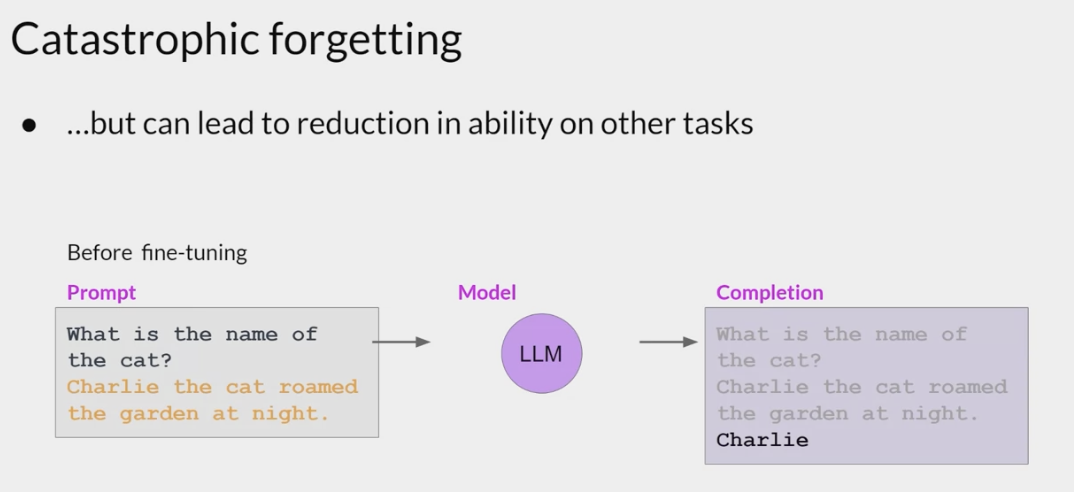
This model knew how to carry out named entity recognition before fine-tuning correctly identifying Charlie as the name of the cat in the sentence.
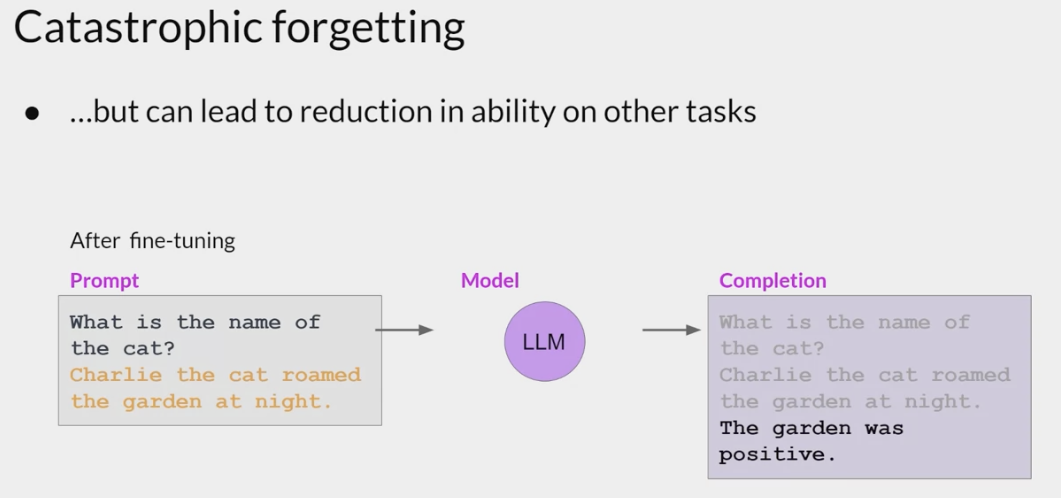
But after fine-tuning, the model can no longer carry out this task, confusing both the entity it is supposed to identify and exhibiting behavior related to the new task.
avoid catastrophic forgetting
decide whether catastrophic forgetting actually impacts the use case.
- If all you need is reliable performance on the single task you fine-tuned on, it may not be an issue that the model can’t generalize to other tasks.
- If you do want or need the model to maintain its
multitask generalized capabilities, you can perform fine-tuning on multiple tasks at one time.
Good multitask fine-tuning may require 50-100,000 examples across many tasks, and so will require more data and compute to train. Will discuss this option in more detail shortly.
perform parameter efficient fine-tuning (PEFT) instead of full fine-tuning.
- PEFT is a set of techniques that preserves the weights of the original LLM and trains only a small number of task-specific adapter layers and parameters.
- PEFT shows greater robustness to catastrophic forgetting since most of the pre-trained weights are left unchanged.
- using regularization techniques to limit the amount of change that can be made to the weights of the model during training. This can help to preserve the information learned during earlier training phases and prevent overfitting to the new data.
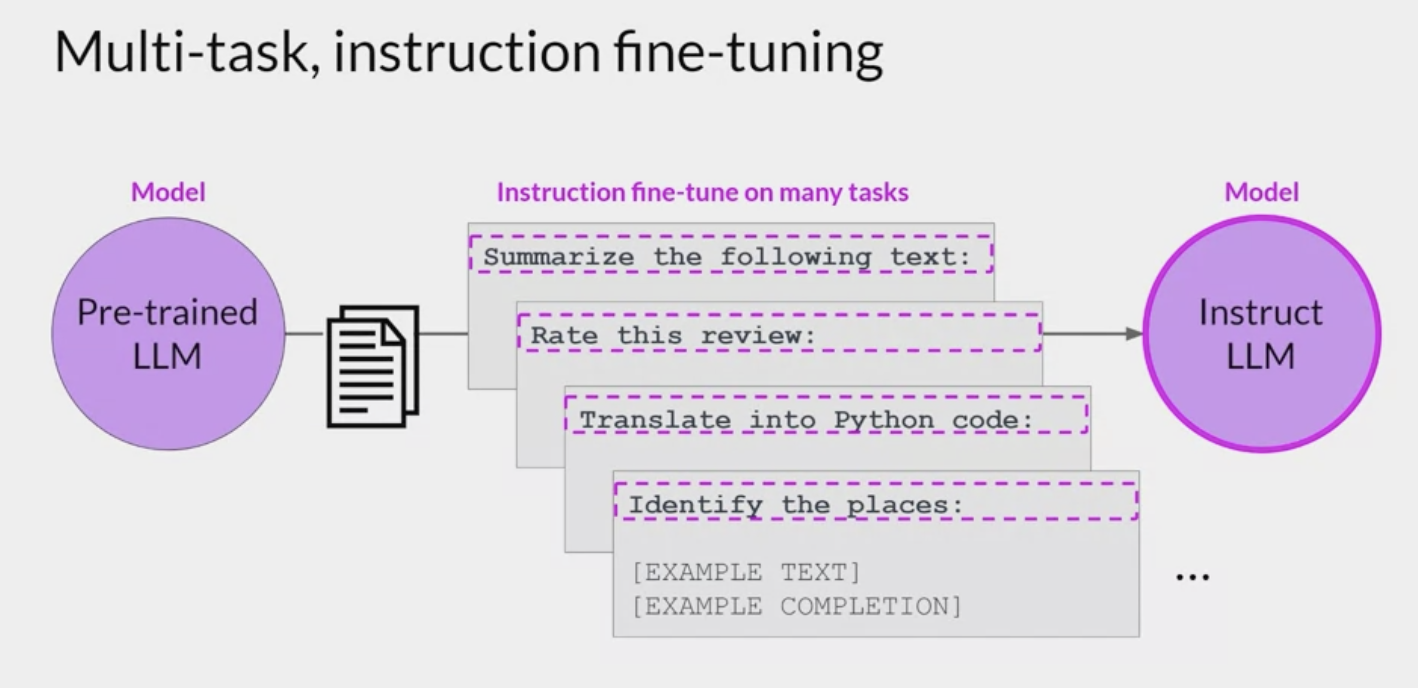
Multi-task fine-tuning
Multitask fine-tuning- an extension of single task fine-tuning
- the training dataset is comprised of example inputs and outputs for multiple tasks.
The dataset used for multitask fine-tuning includes examples for tasks such as summarization, review rating, code translation, and entity recognition.
- You train the model on mixed dataset so that it can improve the performance of the model on all the tasks simultaneously
- avoiding the issue of catastrophic forgetting
Over many epochs of training, the
calculated lossesacross examples are used to update the weights of the model, resulting in an instruction tuned model that is learned how to be good at many different tasks simultaneously.- The resulting models are often very capable and suitable for use in situations where good performance at many tasks is desirable.
- drawback
- requires a lot of data: as many as 50-100,000 examples in the training set.
- a family of models that have been trained using multitask instruction fine-tuning. Instruct model variance differ based on the datasets and tasks used during fine-tuning.
- a specific set of instructions used to fine-tune different models.
- Because they’re FLAN fine-tuning is the last step of the training process the authors of the original paper called it the metaphorical dessert to the main course of pre-training quite a fitting name.
- FLAN-PALM: the flattening struct version of the palm foundation model
- FLAN-T5: the FLAN instruct version of the T5 foundation model
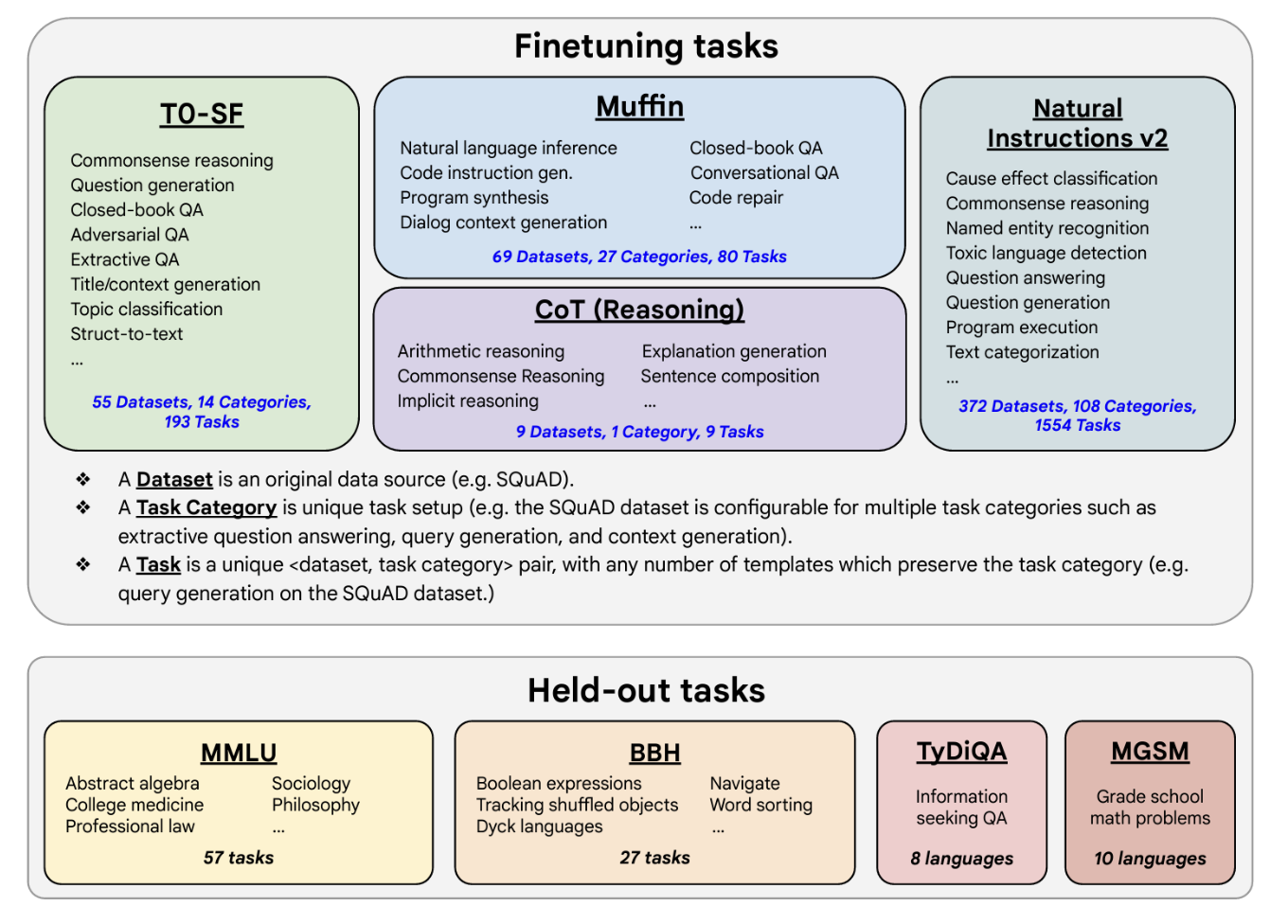
- a great general purpose instruct model.
- been fine tuned on 473 datasets across 146 task categories.
- One example of a prompt dataset used for summarization tasks in FLAN-T5 is
SAMSum. - It’s part of the muffin collection of tasks and datasets and is used to train language models to summarize dialogue.

the fine-tuning tasks and datasets employed in training FLAN. The task selection expands on previous works by incorporating dialogue and program synthesis tasks from Muffin and integrating them with new Chain of Thought Reasoning tasks. It also includes subsets of other task collections, such as T0 and Natural Instructions v2. Some tasks were held-out during training, and they were later used to evaluate the model’s performance on unseen tasks.
SAMSum
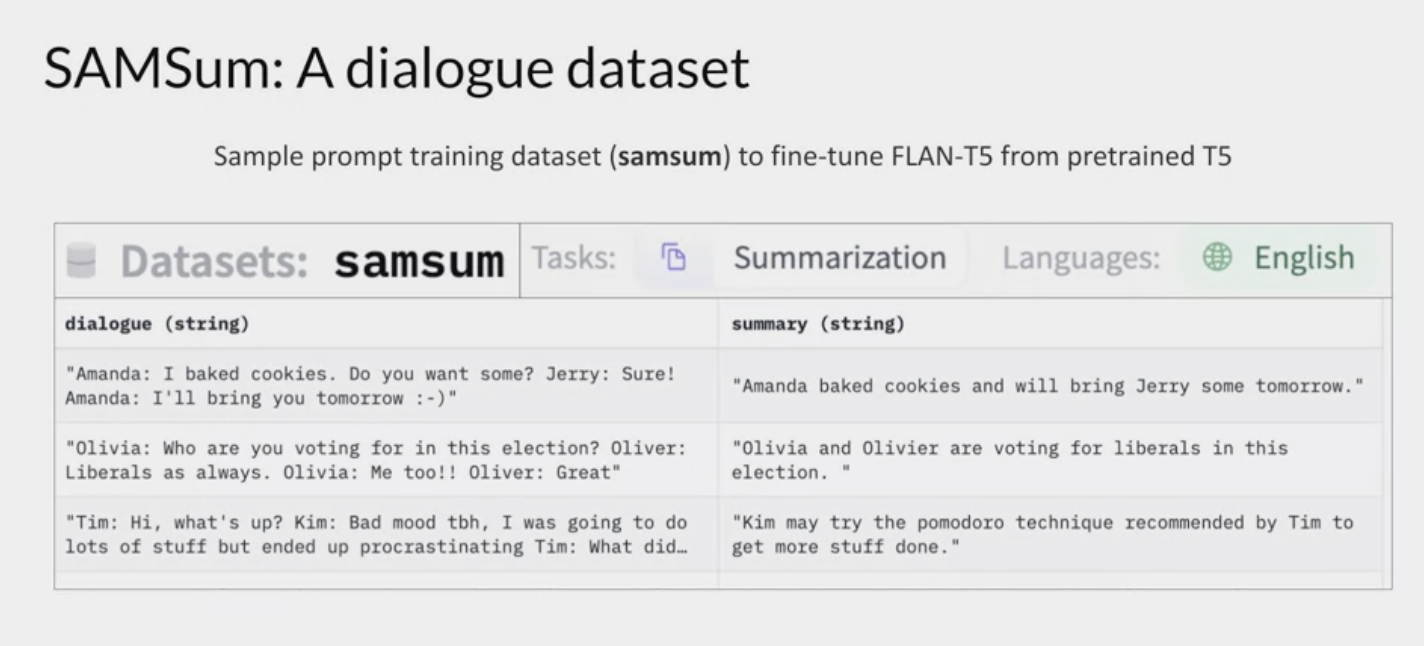
- a dataset with 16,000 messenger like conversations with summaries.
- Three examples are shown here with the
dialogueon the left and thesummarieson the right. - The dialogues and summaries were crafted by linguists for the express purpose of generating a high-quality training dataset for language models.
- The linguists were asked to create conversations similar to those that they would write on a daily basis, reflecting their proportion of topics of their real life messenger conversations.
- language experts then created short summaries of those conversations that included important pieces of information and names of the people in the dialogue.
- Here is a prompt template designed to work with this SAMSum dialogue summary dataset.
- The template is actually comprised of several different instructions that all basically ask the model to do this same thing. Summarize a dialogue.
- For example
- briefly summarize that dialogue.
- What is a summary of this dialogue?
- What was going on in that conversation?
Including different ways of saying the same instructionhelps the model generalize and perform better.- in each case, the
dialoguefrom the SAMSum dataset is inserted into the template wherever the dialogue field appears. - The
summaryis used as the label.
- in each case, the
- After applying this template to each row in the SAMSum dataset, you can use it to fine tune a dialogue summarization task.

While FLAN-T5 is a great general use model that shows good capability in many tasks. You may still find that it has room for improvement on tasks for the specific use case.
- For example: imagine you’re a data scientist building an app to support the customer service team, process requests received through a chat bot
- Your customer service team needs a summary of every dialogue to identify the key actions that the customer is requesting and to determine what actions should be taken in response.
- The SAMSum dataset examples in the dataset are mostly conversations between friends about day-to-day activities and don’t overlap much with the language structure observed in customer service chats.
- perform additional fine-tuning of the FLAN-T5 model
using a dialogue dataset that is much closer to the conversations that happened with the bot.- make use of an additional domain specific summarization dataset
dialogsum- This dataset consists of over 13,000 support chat dialogues and summaries.
- The dialogue some dataset is not part of the FLAN-T5 training data, so the model has not seen these conversations before.
- example from dialogsum and discuss how a further round of fine-tuning can improve the model.
- This is a support chat that is typical of the examples in the dialogsum dataset. The conversation is between a customer and a staff member at a hotel check-in desk.
- The chat
has had a template applied so that the instruction to summarize the conversationis included at the start of the text.
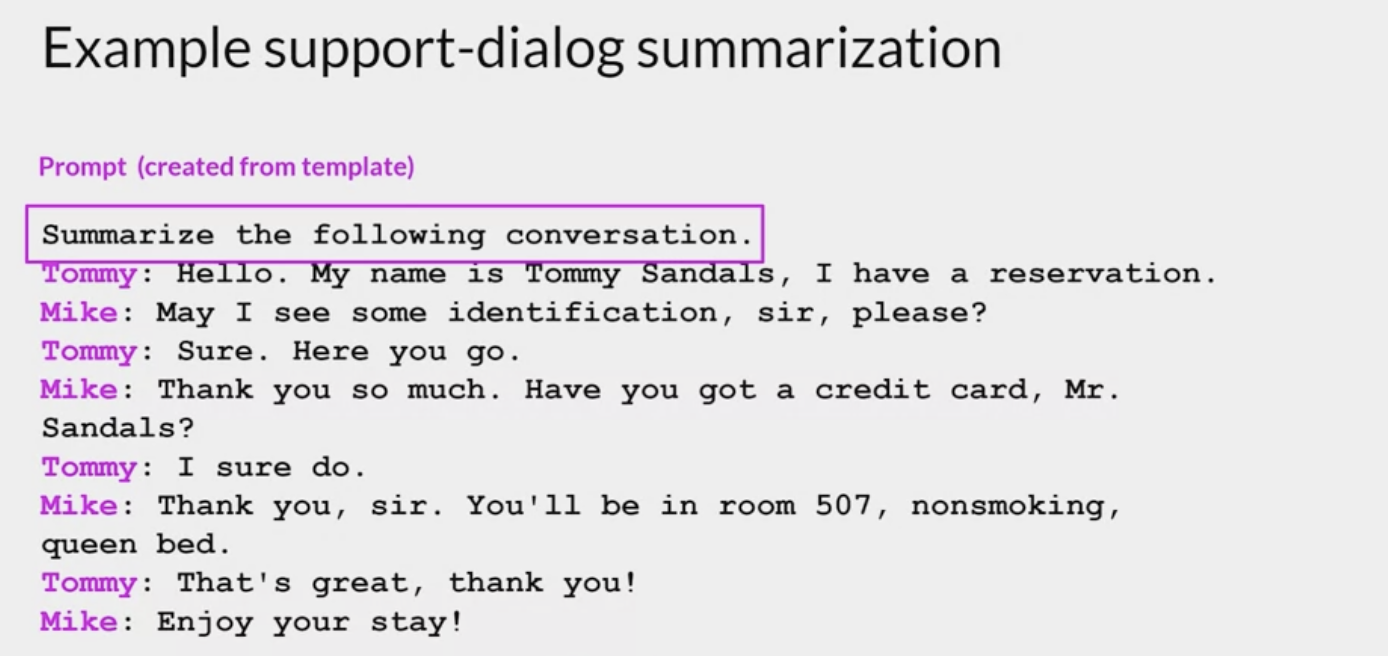
how FLAN-T5 responds to this prompt before doing any additional fine-tuning
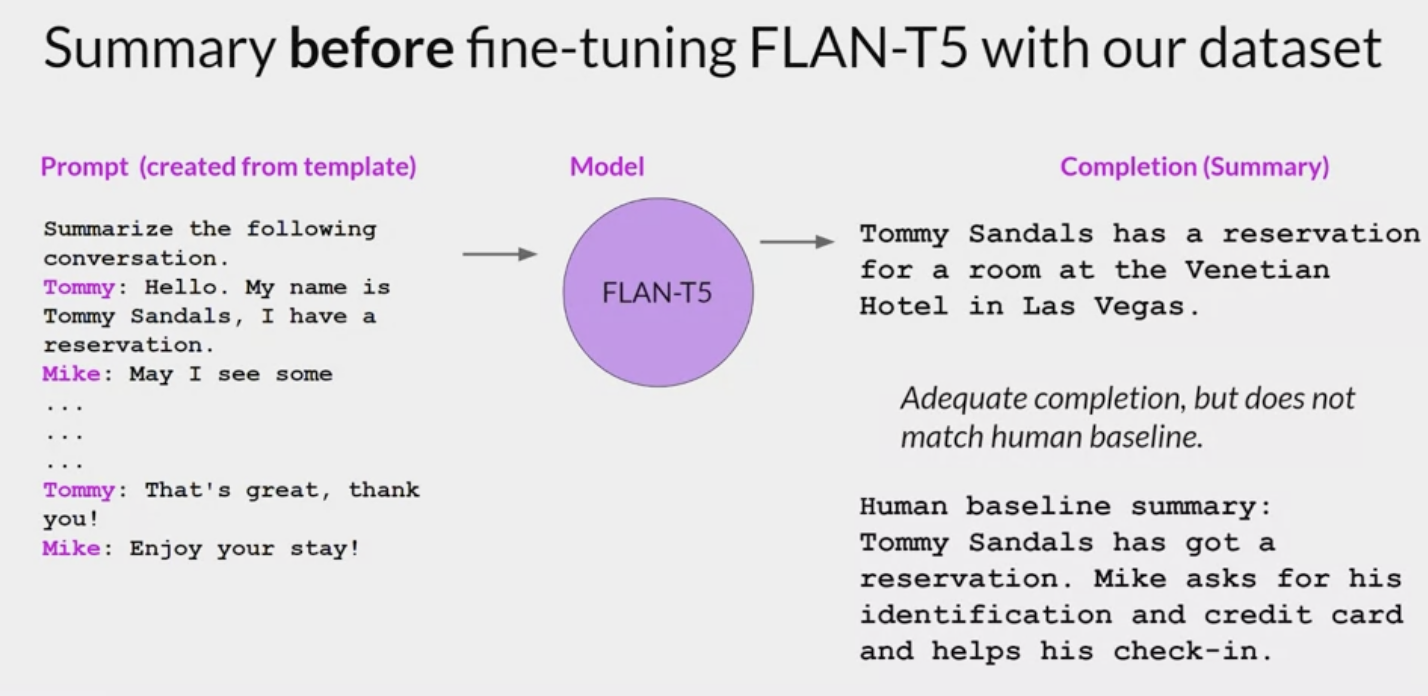
how the model does after fine-tuning on the dialogue some dataset, no fabricated information and the summary includes all of the important details, including the names of both people participating in the conversation.
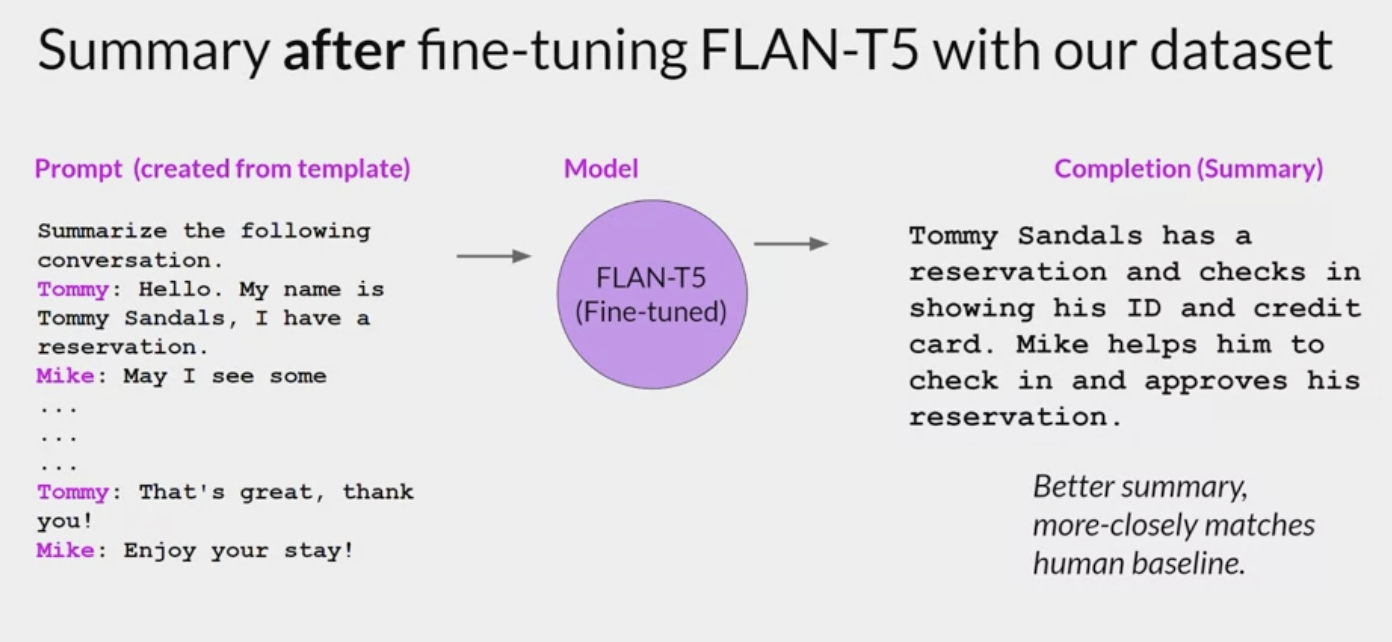
This example, use the public dialogue, some dataset to demonstrate fine-tuning on custom data. In practice, you’ll get the most out of fine-tuning by using the company’s own internal data. This will help the model learn the specifics of how the company likes to summarize conversations and what is most useful to the customer service colleagues.
Comments powered by Disqus.