LLM - LLM Data Training
- LLM - Data Training
- Prompt Learning
- Tuning 微调
- 改進LLM
- LLM Evaluation
LLM - Data Training
Prompt Learning
prompt learning:
Prompt-Tuning和In-context learning是prompt learning的两种模式。
- In-context learning
- 指在大规模预训练模型上进行推理时,不需要提前在下游目标任务上进行微调,即不改变预训练模型参数就可实现推理,
- 其认为超大规模的模型只要配合好合适的模板就可以极大化地发挥其推理和理解能力。
常用的In-context learning方法有
few-shot one-shot zero-shot;- Prompt-Tuning
- 指在下游目标任务上进行推理前,需要对全部或者部分参数进行更新
- 全部/部分的区别就在于预训练模型参数是否改变(其实本质上的Prompt-Tuning是不更新预训练模型参数的,这里有个特例方法称为Prompt-Oriented Fine-Tuning,其实该方法更适合称为升级版的Fine-Tuning,后面会详细介绍这个方法)。
- 无论是In-context learning还是Prompt-Tuning,它们的目标都是将下游任务转换为预训练模型的预训练任务,以此来广泛激发出预训练模型中的知识。
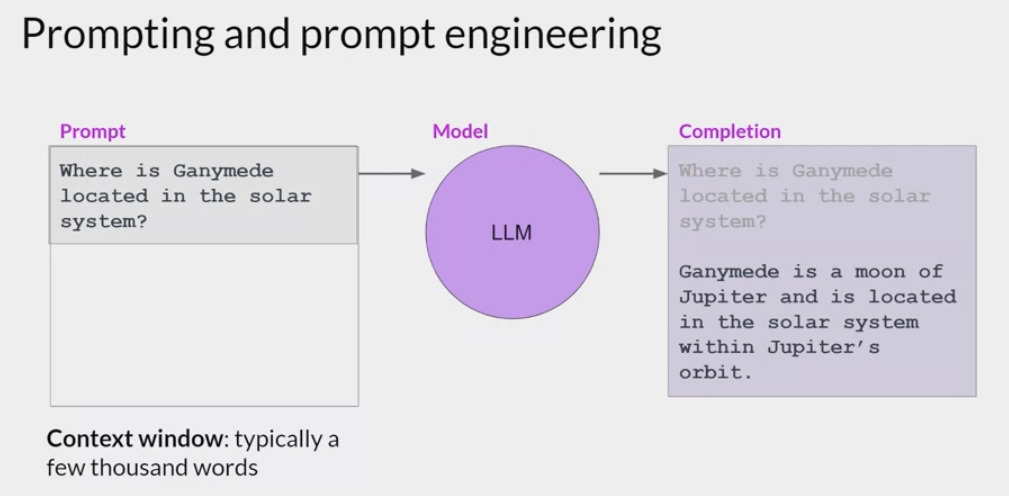
Prompting and prompt engineering:
- 如何设计输入的prompt是很重要的一点
- failed with 5-6 example, fune tune the model
- Typically, above five or six shots, so full prompt and then completions, you really don’t gain much after that. Either the model can do it or it can’t do it
Prompt-Tuning(提示微调)
- 以二分类的情感分析作为例子:
给定一个句子
[CLS]I like the Disney films very much.[SEP],- 传统的Fine-Tuning方法:
- 将其通过Bert获得
[CLS]表征之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative) - 因此需要一定量的训练数据来训练。
- 将其通过Bert获得
而Prompt-Tuning则执行如下步骤:
- 构建模板(Template Construction):
- 通过人工定义 自动搜索 文本生成等方法,生成与给定句子相关的一个含有
[Mask]标记的模板。例如It was[Mask] - 并拼接到原始的文本中,获得Prompt-Tuning的输入:
[CLS]I like the Disney films very much. It was[Mask].[SEP]。 - 将其喂入B模型中,并复用预训练好的MLM分类器(在huggingface中为BertForMaskedLM),即可直接得到
[Mask]预测的各个token的概率分布;
- 通过人工定义 自动搜索 文本生成等方法,生成与给定句子相关的一个含有
- 标签词映射(Label Word Verbalizer):
- 因为
[Mask]部分我们只对部分词感兴趣,因此需要建立一个映射关系。 - 例如如果
[Mask]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类; - 不同的句子应该有不同的template和label word,因为每个句子可能期望预测出来的label word都不同,因此如何最大化的寻找当前任务更加合适的template和label word是Prompt-Tuning非常重要的挑战;
- 因为
- 训练:
- 根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。
- 此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题。
- 构建模板(Template Construction):
ICL - In-context learning 上下文学习
- ICL又称为上下文学习,最早是在GPT-3《Language Models are Few-Shot Learners》中被提出来的。
ICL的关键思想是从类比中学习。
- 下图给出了一个描述语言模型如何使用ICL进行决策的例子。
- 首先,ICL需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。
- 然后ICL将查询的问题(即你需要预测标签的input)和一个上下文演示(一些相关的cases)连接在一起,形成带有提示的输入(可称之为prompt),并将其输入到语言模型中进行预测。
- 值得注意的是,与需要使用反向梯度更新模型参数的训练阶段的监督学习不同,ICL不需要参数更新,并直接对预先训练好的语言模型进行预测(这是与Prompt-Tuning不同的地方,ICL不需要在下游任务中Prompt-Tuning或Fine-Tuning)。
- 它希望模型能自动学习隐藏在演示中的模式,并据此做出正确的预测。

use LLMs off the shelf (i.e., without any fine-tuning), then control their behavior through clever prompting and conditioning on private “contextual” data.
it’s usually easier than the alternative: training or fine-tuning the LLM itself.
It also tends to outperform fine-tuning for relatively small datasets—since a specific piece of information needs to occur at least ~10 times in the training set before an LLM will remember it through fine-tuning—and can incorporate new data in near real time.
- Example:
- building a chatbot to answer questions about a set of legal documents.
naive approach: paste all the documents into a ChatGPT or GPT-4 prompt, then ask a question about them at the end. This may work for very small datasets, but it doesn’t scale. The biggest GPT-4 model can only process ~50 pages of input text, and performance (measured by inference time and accuracy) degrades badly when approach the limitcontext window.In-context learning: instead of sending all the documents with each LLM prompt, it sends only a handful of the most relevant documents. And the most relevant documents are determined with the help of . . . you guessed it . . . LLMs.
- building a chatbot to answer questions about a set of legal documents.
in-context learning method
One shot: creating an initial prompt that states the task to be completed and includes a single example question with answer followed by a second question to be answered by the LLM
- In-context learning的优势:
- 若干示例组成的演示是用自然语言撰写的,这提供了一个跟LLM交流的可解释性手段,通过这些示例跟模版让语言模型更容易利用到人类的知识;
- 类似于人类类比学习的决策过程,举一反三;
- 相比于监督学习,它不需要模型训练,减小了计算模型适配新任务的计算成本,更容易应用到更多真实场景。
- In-context learning的流程:
In-context learning可以分为两部分,分为作用于training跟inference阶段:
Training:
在推理前,通过持续学习让语言模型的ICL能力得到进一步提升,这个过程称之为model warmup(模型预热),model warmup会优化语言模型对应参数或者新增参数,区别于传统的Fine-Tuning,Fine-Tuning旨在提升LLM在特定任务上的表现,而model warmup则是提升模型整体的ICL性能。
Supervised in-context training: 为了增强ICL的能力,研究人员提出了
通过构建in-context训练数据,进而进行一系列有监督in-context微调以及多任务训练。由于预训练目标对于In-context learning并不是最优的,Sewon Min等人提出了一种方法
MetaICL《MetaICL: Learning to Learn In Context》,以消除预训练和下游ICL使用之间的差距。预训练LLM在具有演示样例的广泛的任务上进行训练,这提高了其few-shot能力,例如,MetaICL获得的性能与在52个独力数据集上进行有监督微调相当。此外,还有一个研究方向,即有监督指令微调,也就是后面要讲到的Instruction-Tuning。指令微调通过对任务指令进行训练增强了LLM的ICL能力。例如Google提出的
FLAN方法《FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS》: 通过在由自然语言指令模板构建的60多个NLP数据集上调整137B参数量的LaMDA-PT模型,FLAN方法可以改善zero-shot和few-shot ICL性能(具体可参考Finetuned Language Models are Zero-shot Learners 笔记 - Instruction Tuning 时代的模型)。与MetaICL为每个任务构建若干演示样例相比,指令微调主要考虑对任务的解释,并且易于扩展。
Self-supervised in-context training:
Supervised Learning指的是有一个model,输入是 $x$ ,输出是 $y$ ,要有label(标签)才可以训练Supervised Learning,
比如让机器看一篇文章,决定文章是正面的还是负面的,得先找一大堆文章,标注文章是正面的还是负面的,正面负面就是label。
- Self-Supervised Learning就是机器自己在没有label的情况下,想办法做Supervised Learning。
- 比如把没有标注的语料分成两部分,一部分作为模型的输入,一部分作为模型的输出,模型的输出和label越接近越好,具体参见2022李宏毅机器学习深度学习学习笔记第四周–Self-Supervised Learning。
- 引申到self-supervised in-context training,是根据ICL的格式将原始数据转换成input-output的pair对数据后利用四个自监督目标进行训练,包括掩
[Mask]预测,分类任务等。
Supervised ICT跟self-supervised ICT旨在通过引入更加接近于ICT的训练目标从而缩小预训练跟ICL之间的差距。- 比起需要示例的In-context learning,只涉及任务描述的Instruction-Tuning更加简单且受欢迎。
- 另外,在model warmup这个阶段,语言模型只需要从少量数据训练就能明显提升ICL能力,不断增加相关数据并不能带来ICL能力的持续提升。
- 从某种角度上看,这些方法通过更新模型参数可以提升ICL能力也表明了原始的LLM具备这种潜力。
- 虽然ICL不要求model warmup,但是一般推荐在推理前增加一个model warmup过程
- ICL最初的含义指的是大规模语言模型涌现出一种能力: 不需要更新模型参数,仅仅修改输入prompt即添加一些例子就可以提升模型的学习能力。ICL相比之前需要对模型在某个特定下游任务进行Fine-Tuning大大节省了成本。之后ICL问题演变成研究怎么提升模型以具备更好更通用的ICL能力,这里就可以用上之前Fine-Tuning的方式,即指model warmup阶段对模型更新参数
Inference:
很多研究表明LLM的ICL性能严重依赖于演示示例的格式,以及示例顺序等等,在使用目前很多LLM模型时我们也会发现,在推理时,同一个问题如果加上不同的示例,可能会得到不同的模型生成结果。
Demonstration Selection: 对于ICL而言,哪些样本是好的?语言模型的输入长度是有限制的,如何从众多的样本中挑选其中合适的部分作为示例这个过程非常重要。按照选择的方法主要可以分为无监督跟有监督两种。
无监督方法: 首先就是根据句向量距离或者互信息等方式选择跟当前输入x最相似的样本作为演示示例,另外还有利用自适应方法去选择最佳的示例排列,有的方法还会考虑到演示示例的泛化能力,尽可能去提高示例的多样性。除了上述这些从人工撰写的样本中选择示例的方式外,还可以利用语言模型自身去生成合适的演示示例。
监督方法: 第一种是先利用无监督检索器召回若干相似的样本,再通过监督学习训练的Efficient Prompt Retriever进行打分,从而筛选出最合适的样本。此外还有基于Prompt Tuning跟强化学习的方式去选择样本。
Demonstration Ordering: 挑选完演示示例后,如何对其进行排序也非常重要。排序的方法既有不需要训练的,也有根据示例跟当前输入距离远近进行排序的,也可以根据自定义的熵指标进行重排。
Demonstration Formatting:
- 如何设计演示示例的格式?最简单的方式就是将示例们的 $(x,y)$ 对按照顺序直接拼接到一起。
- 但是对于复杂的推理问题,语言模型很难直接根据 $x$ 推理出 $y$ ,这种格式就不适用了。
- 另外,有的研究旨在设计更好的任务指令instruction作为演示内容(即Instruction-Tuning)。
- 对于这两类场景,除了人工撰写的方式外,还可以利用语言模型自身去生成对应的演示内容。
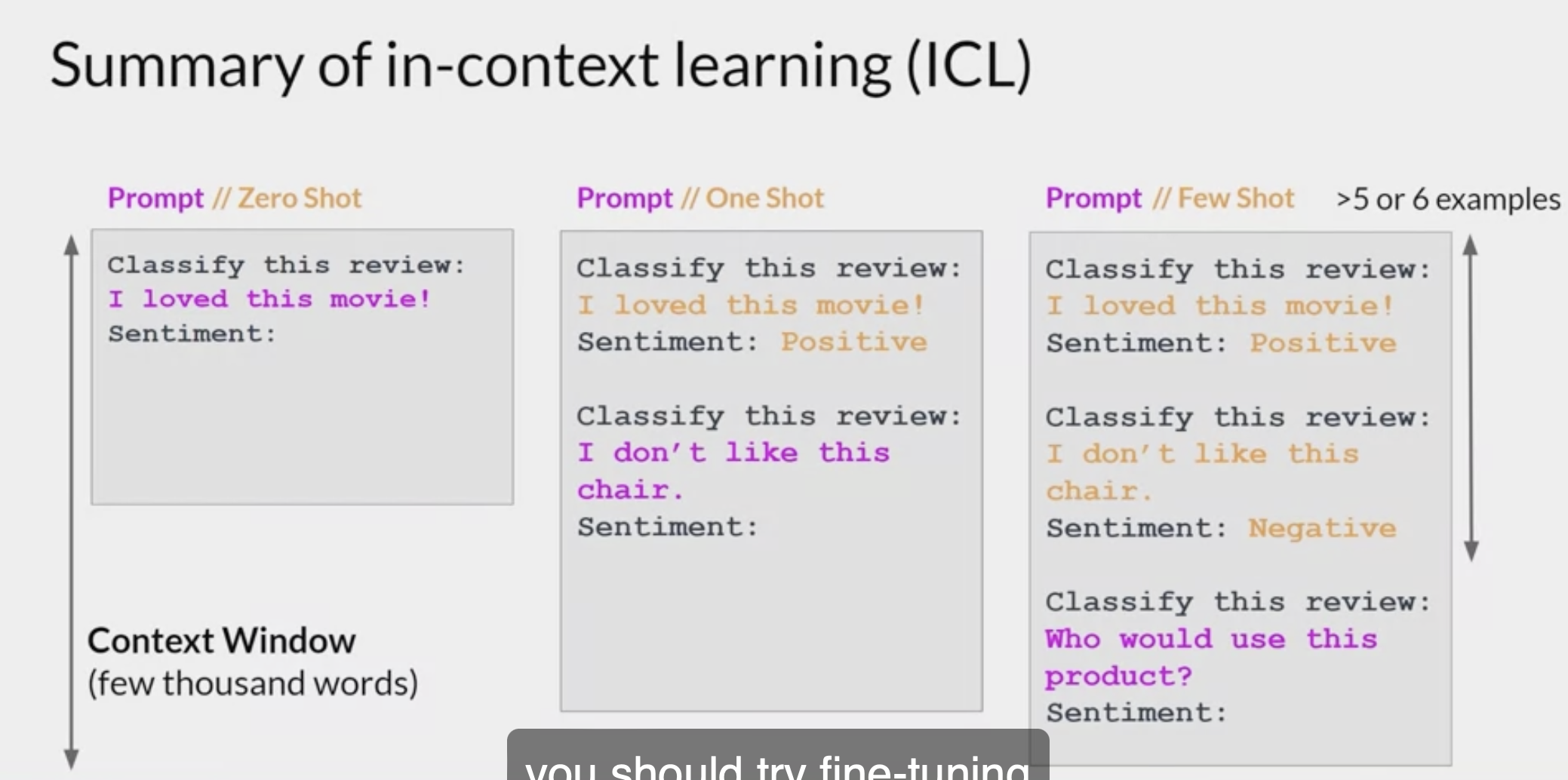
- In-context learning的模式:
- In-context learning包括三种模式,分别称作few-shot one-shot以及zero-shot,
- 三者的主要区别是prompt中包含的样本示例数量
- Few-Shot: 对下游任务,提供多条数据样例,论文中指出一般是10-100条;
- One-Shot: few-shot的一种特殊情况,对下游任务,只提供一条数据样例;
- Zero-Shot: 是一种极端情况,对下游任务,不提供数据样例,只提供任务描述。
参考论文:
Tuning 微调
目前学术界一般将NLP任务的发展分为四个阶段,即NLP四范式: [^通俗易懂的LLM(上篇)]
- 第一范式: 基于「
传统机器学习模型」的范式,如TF-IDF特征+朴素贝叶斯等机器算法; 第二范式: 基于「
深度学习模型」的范式,如word2vec特征+LSTM等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;第三范式: 基于「
预训练模型+fine-tuning」的范式,如Bert+fine-tuning的NLP任务,相比于第二范式,模型准确度显著提高,模型也随之变得更大,但小数据集就可训练出好模型;- 第四范式: 基于「
预训练模型+Prompt+预测」的范式,如Bert+Prompt的范式相比于第三范式,模型训练所需的训练数据显著减少。
在整个NLP领域,你会发现整个发展是朝着精度更高 少监督,甚至无监督的方向发展的。下面我们对第三范式 第四范式进行详细介绍。
- 总的来说
- 基于Fine-Tuning的方法是让预训练模型去迁就下游任务。
- 基于Prompt-Tuning的方法可以让下游任务去迁就预训练模型。
LLM模型训练过程中的三个核心步骤
- 预训练语言模型 $LLM^{SSL}$ (self-supervised-learning)
- (指令)监督微调预训练模型 $LLM^{SFT}$ (supervised-fine-tuning)
- 基于人类反馈的强化学习微调 $LLM^{RL}$ (reinforcement-learning)
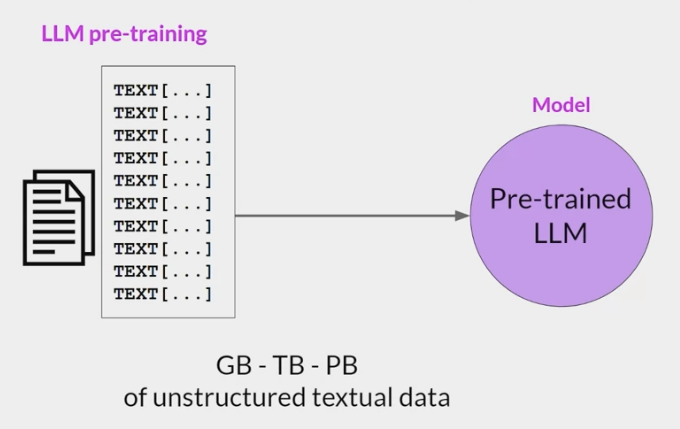
self-supervised-learning 预训练阶段
- 从互联网上收集海量的文本数据,通过自监督的方式训练语言模型,根据上下文来预测下个词。
- token的规模大概在trillion级别,这个阶段要消耗很多资源,海量的数据采集 清洗和计算,
- 该阶段的目的是:通过海量的数据,让模型接触不同的语言模式,让模型拥有理解和生成上下文连贯的自然语言的能力。

训练过程大致如下:
Training data: 来自互联网的开放文本数据,整体质量偏低
Data scale: 词汇表中的token数量在trillion级别
$LLM^{SSL}_ϕ$: 预训练模型
$[T_1,T_2,…,T_V]$ : vocabulary 词汇表,训练数据中词汇的集合
$V$: 词汇表的大小
- $f(x)$: 映射函数把词映射为词汇表中的索引即:token.
- if $x$ is $T_k$ in vocab, $f(x) = k$
- $(x_1,x_2,…,x_n)$, 根据文本序列生成训练样本数据:
- Input: $x=(x_1,x_2,…,x_{i−1})$
- Output(label) : $x_i$
- $(x,xi)$,训练样本:
- Let $k = f(x_i), word→token$
- Model’s output: $LLM^{SSL}(x)=[\bar{y_1},\bar{y2},…,\bar{yV}]$
- 模型预测下一个词的概率分布,Note : $∑_j \bar{y_j} = 1$
- The loss value:$CE(x,x_i;ϕ)= −log(\overline{y}_k)$
Goal : find ϕ, Minimize $CE(\phi) = -E_x log(\overline{y}_k)$
- 预先训练阶段 $LLM^{SSL}$ LLMSSL还不能正确的响应用户的提示
- 例如,如果提示“法国的首都是什么?”这样的问题,模型可能会回答另一个问题的答案,
- 例如,模型响应的可能是“意大利的首都是什么?”,因为模型可能没有“理解”/“对齐aligned”用户的“意图”,只是复制了从训练数据中观察到的结果。
- 为了解决这个问题,出现了一种称为监督微调或者也叫做指令微调的方法。
- 通过在少量的示例数据集上采用监督学习的方式对 $LLM^{SSL}$ 进行微调,经过微调后的模型,可以更好地理解和响应自然语言给出的指令。
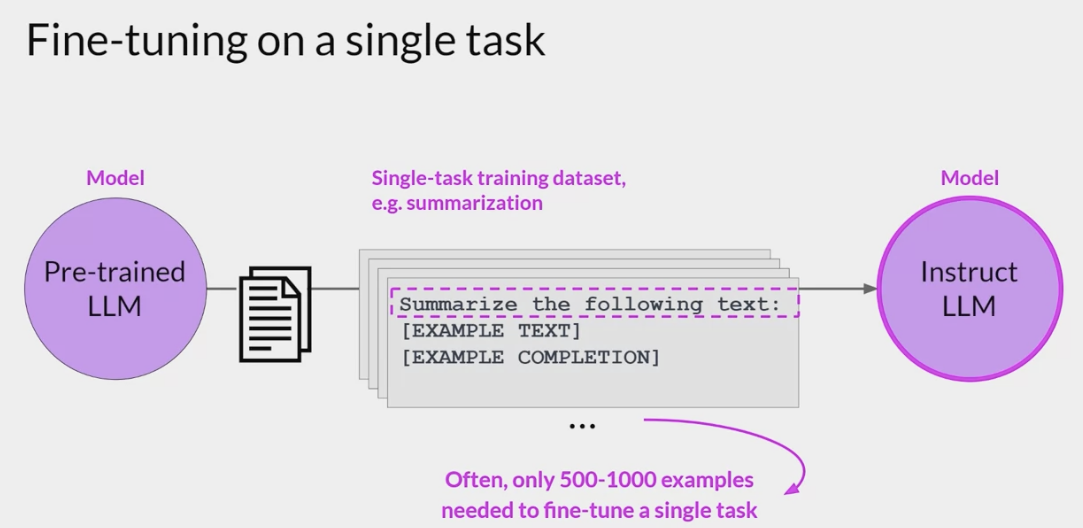
Fine-Tuning(微调)
Fine-Tuning是一种迁移学习,在自然语言处理(NLP)中,Fine-Tuning是用于将预训练的语言模型适应于特定任务或领域。
基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
- Fine-Tuning的概念已经存在很多年,并在各种背景下被使用。
- Fine-Tuning在NLP中最早的已知应用是在神经机器翻译(NMT)的背景下,其中研究人员使用预训练的神经网络来初始化一个更小的网络的权重,然后对其进行了特定的翻译任务的微调。
- 经典的Fine-Tuning方法包括将预训练模型与少量特定任务数据一起继续训练。
- 在这个过程中,预训练模型的权重被更新,以更好地适应任务。
- 所需的Fine-Tuning量取决于预训练语料库和任务特定语料库之间的相似性。
- 如果两者相似,可能只需要少量的Fine-Tuning,如果两者不相似,则可能需要更多的Fine-Tuning。
- Bert模型2018年横空出世之后,将Fine-Tuning推向了新的高度。不过目前来看,Fine-Tuning逐渐退出了tuning研究的舞台中心: LLM蓬勃发展,Fine-Tuning这种大规模更新参数的范式属实无法站稳脚跟。而更适应于LLM的tuning范式,便是接下来我们要介绍的Prompt-Tuning Instruction-Tuning等。

Supervised Fine-Tuning (SFT 监督微调阶段)
good option when you have a well-defined task with available labeled data.
particularly effective for domain-specific applications where the language or content significantly differs from the data the large model was originally trained on.
Supervised fine-tuning adapts model behavior with a labeled dataset.
- This process adjusts the model’s weights to
minimize the difference between its predictions and the actual labels.
For example, it can improve model performance for the following types of tasks:
- Classification
- Summarization
- Extractive question answering
- Chat
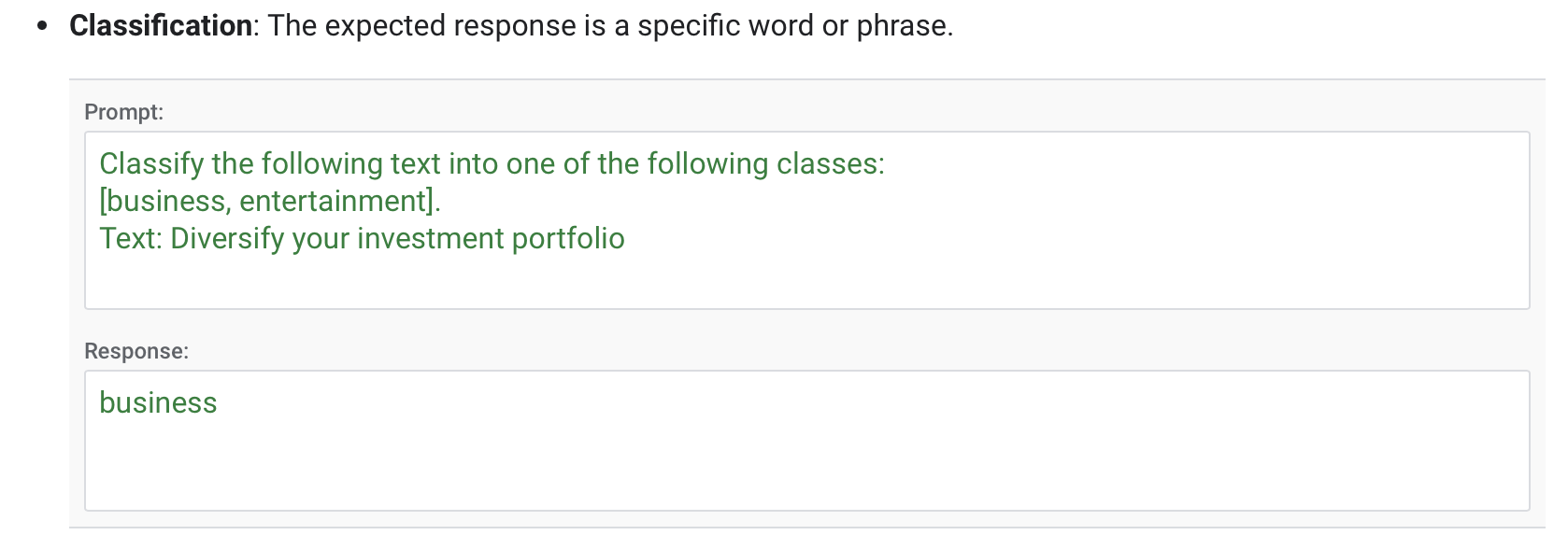

- SFT(Supervised Fine-Tuning)阶段的目标是
优化预训练模型,使模型生成用户想要的结果。- 在该阶段,给模型展示
如何适当地响应不同的提示 (指令) (例如问答,摘要,翻译等)的示例。 - 这些示例遵循 (prompt response)的格式,称为演示数据。
- 通过基于示例数据的监督微调后,模型会模仿示例数据中的响应行为,学会问答 翻译 摘要等能力,
- OpenAI 称为:监督微调行为克隆 。
- 在该阶段,给模型展示
基于LLM指令微调的突出优势在于,对于任何特定任务的专用模型,只需要在通用大模型的基础上通过特定任务的指令数据进行微调,就可以解锁LLM在特定任务上的能力,不在需要从头去构建专用的小模型。
- 事实也证明,经过微调后的小模型可以生成比没有经过微调的大模型更好的结果:
指令微调过程如下:
1
2
3
4
5
6
7
8
9
10
11
- Training Data : 高质量的微调数据,由人工产生。
- Data Scale : 10000~100000
- InstructGPT : ~14500个人工示例数据集。
- Alpaca : 52K ChatGPT指令数据集。
- Model input and output
- Input : 提示 (指令)。
- Output : 提示对应的答案(响应)
- Goal : 最小化交叉熵损失,只计算出现在响应中的token的损失。
RLHF 人类反馈强化学习阶段
大语言模型(LLM)和基于人类反馈的强化学习(RLHF) [^LLM和RLHF]
在经过监督 (指令)微调后,LLM模型已经可以根据指令生成正确的响应了,为什么还要进行强化学习微调?
- 因为随着像ChatGPT这样的通用聊天机器人的日益普及,全球数亿的用户可以访问非常强大的LLM,确保这些模型不被用于恶意目的,同时拒绝可能导致造成实际伤害的请求至关重要。
- 恶意目的的例子如下:
- 具有编码能力的LLM可能会被用于以创建恶意软件。
- 在社交媒体平台上大规模的使用聊天机器人扭曲公共话语。
- 当LLM无意中从训练数据中复制个人身份信息造成的隐私风险。
- 用户向聊天机器人寻求社交互动和情感支持时可能会造成心理伤害。
- 为了应对以上的风险,需要采取一些策略来防止LLM的能力不被滥用,构建一个可以与人类价值观保持一致的LLM,RLHF (从人类反馈中进行强化学习)可以解决这些问题,让AI更加的Helpfulness Truthfulness和Harmlessness。
奖励模型
在强化学习中一般都有个奖励函数,对当前的 $\tfrac{Action}{(State,Action)}$ 进行评价打分,从而使使Policy模型产生更好的
action。在RLHF微调的过程,也需要一个
Reward Model来充当奖励函数,它代表着人类的价值观,RM 的输入是(prompt, response),返回一个分数。response可以看作LLM的
action,LLM看作Policy模型,通过RL框架把人类的价值观引入LLM。

对比数据集
- 在训练RM之前,需要构建对比数据
- 通过人工区分出好的回答和差的回答
- 数据通过经过监督微调 (SFT) 后的 $LLM^{SFT}$ 生成,随机采样一些prompt,通过模型生成多个response,
- 通过人工对结果进行两两排序,区分出好的和差的。
- 数据格式如下:
$(prompt, good_response,bad_response)$
奖励模型的训练过程如下:
Training Data : 高质量的人工标记数据集$(prompt, winning_response, losing_response)$
Data Scale : 100k ~ 1M
$R_{\theta}$ : 奖励模型
Training data format:
- $$x$ $ : prompt
- $y^w, y_w, yw$ : good response
- $y^l, y_l, yl$ : bad response
For each training sample:
- $s_w = R_{\theta}(x, y_w)$,奖励模型的评价
- $s_l = R_{\theta}(x,y_l)$
- $Loss: Minimize -log(\sigma(s_w - s_l)$
Goal : find θ to minimize the expected loss for all training samples.
- $-E_xlog(\sigma(s_w - s_l)$
PPO微调

- 从数据中随机采样prompt。
- Policy( $LLM^{RL}$ 即: $LLM^{SFT}$ ),根据prompt生成response。
- Reward模型根据 $(prompt, response)$,计算分数score。
- 根据score更新Policy模型 (Policy是在 $LLM^{SFT}$ 基础上微调得到的)。
- 在这个过程中,policy( $LLM^{RL}$ )会不断更新,为了不让它偏离SFT阶段的模型太远,OpenAI在训练过程中增加了KL离散度约束,保证模型在得到更好的结果同时不会跑偏,这是因为Comparison Data不是一个很大的数据集,不会包含全部的回答,对于任何给定的提示,都有许多可能的回答,其中绝大多数是 RM 以前从未见过的。
- 对于许多未知 (提示 响应)对,RM 可能会错误地给出极高或极低的分数。如果没有这个约束,模型可能会偏向那些得分极高的回答,它们可能不是好的回答。
RLHF微调过程如下:
ML task : RL(PPO)
- Action Space : the vocabulary of tokens the LLM uses. Taking action means choosing a token to generate.
- Observation Space : the distribution over all possible prompts.
- Policy: the probability distribution over all actions to take (aka all tokens to generate) given an observation (aka a prompt). An LLM constitutes a policy because it dictates how likely a token is to be generated next.
- Reward function: the reward model.
Training data: randomly selected prompts
Data scale: 10,000 - 100,000 prompts
- InstructGPT: 40,000 prompts
$R_{\phi}$ : the reward model.
$LLM^{SFT}$ : the supervised finetuned model(instruction finetuning).
$LLM^{RL}_{\phi}$ : the model being trained with PPO, parameterized by $\phi$ .
- $x$: prompt.
- $D_{RL}$ : the distribution of prompts used explicitly for the RL model.
$D_{pretrain}$ : the distribution of the training data for the pretrain model.
For each training step, sample a batch of $x_{RL}$ from $D_{RL}$ and a batch of $x_{pretrain}$ from $D_{pretrain}$.
For each $x_{RL}$ , use $LLM_{\phi}^{RL}$ to generate a response : $y \sim LLM_{\phi}^{RL}(x_{RL})$
\[\text{objective}_1(x_{RL}, y; \phi) = R_{\theta}(x_{RL}, y) - \beta \log (\frac{LLM^{RL}_\phi(y \vert x)}{LLM^{SFT}(y \vert x)})\]For each x p r e t r a i n x_{pretrain} xpretrain, the objective is computed as follows. Intuitively, this objective is to make sure that the RL model doesn’t perform worse on text completion - the task the pretrained model was optimized for.
\[\text{objective}_2(x_{pretrain}; \phi) = \gamma \log (LLM^{RL}_\phi(x_{pretrain})\]The final objective is the sum of the expectation of two objectives above.
\[\text{objective}(\phi) = E_{x \sim D_{RL}}E_{y \sim LLM^{RL}_\phi(x)}\]\
[R_{\theta}(x, y) - \beta \log \frac{LLM^{RL}_\phi(y \vert x)}{LLM^{SFT}(y \vert x)}] +
\[\gamma E_{x \sim D_{pretrain}}\log LLM^{RL}_\phi(x)\]
Goal: Maximize $objective(\phi)$
PVP - Pattern-Verbalizer-Pair
ICL方法是在GPT-3中被提出的,这类方法有一个明显的缺陷是, 其建立在超大规模的预训练语言模型上,此时的模型参数数量通常超过100亿,在真实场景中很难应用,因此众多研究者开始探索GPT-3的这套思路在小规模的语言模型(如Bert)上还是否适用?事实上,这套方法在小规模的语言模型上是可行的,但是需要注意:
- 模型参数规模小了,prompt直接用在zero-shot上效果会下降(虽然GPT-3在zero-shot上效果也没有很惊艳,这也是后来Instruction-Tuning出现的原因),因此需要考虑将In-context learning应用在Fine-Tuning阶段,也就是后面要讲到的Prompt-Tuning。
Pattern-Verbalizer-Pair(PVP)
- 实现Prompt-Tuning的重要组件
- Pattern-Verbalizer-Pair 模式来源于大名鼎鼎的PET模型,PET(Pattern-Exploiting Training)《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》。
- 由于在实际任务中,模型往往只会接触到少量的labeled examples(few-shot learning),而直接将监督学习运用到小样本学习会使得模型表现不佳,针对这个问题,论文中提出了Pattern-Exploiting Training (PET)
- 使用natural language patterns将input examples规范为完型填空形式的半监督训练机制。
通过这种方法,成功地在few-shot settings上将task descriptions与标准监督学习结合。
- 具体的步骤是:
- 构建一组pattern,对于每一个pattern, 会使用一个PLM在小样本训练集上进行Fine-Tuning;
- 训练后的所有模型的集合会被用来在大规模unlabeled dataset标注soft labels;
- 在soft labels数据集上训练一个标准分类器。
- 另外在该论文中,作者提出,在每一个PLM上只进行一次微调+soft labels生成,通常得到的新的数据集(即用soft labels标记的unlabeled dataset)会有很多错误的数据,因此扩展提出iPET模型(Iterative PET),即添加了迭代过程:
- 首先随机从集成的预训练模型集合中抽取部分预训练模型,在未标注数据集(unlabeled dataset)D 上标注数据,并扩增到初始有标签数据集 T 上,其次再根据扩增后的 T 分别微调预训练模型。上述过程一直迭代多次[^迭代多次]
- 论文解读: Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
- 论文阅读: PET系列。
PET最核心的部分Pattern-Verbalizer-Pair(PVP),PET设计了两个很重要的组件:
- Pattern(Template):
- 记作 T ,即上文提到的Template,其为额外添加的带有
[mask]标记的短文本,通常一个样本只有一个Pattern(因为我们希望只有1个让模型预测的[mask]标记)。 - 由于不同的任务 不同的样本可能会有其更加合适的pattern,因此如何构建合适的pattern是Prompt-Tuning的研究点之一;
- 记作 T ,即上文提到的Template,其为额外添加的带有
- Verbalizer:
- 记作 V,即标签词的映射,对于具体的分类任务,需要选择指定的标签词(label word)。
- 例如情感分析中,我们期望Verbalizer可能是: V ( positive ) = great, V ( negative ) = terrible(positive和negative是类标签)。
- 同样,不同的任务有其相应的label word,但需要注意的是,Verbalizer的构建需要取决于对应的Pattern。因此如何构建Verbalizer是另一个研究挑战。
- 上述两个组件即为Pattern-Verbalizer-Pair(PVP),一般记作 P = ( T , V ) 在后续的大多数研究中均采用这种PVP组件。学到这里,我们面临的最大疑问: 对于下游任务,如何挑选合适的Pattern和Verbalizer?自2020年底至今,学术界已经涌现出各种方案试图探索如何自动构建PVP。其实也许在大多数人们的印象中,合适的Pattern才是影响下游任务效果的关键,Verbalizer对下游任务的影响并不大,而下面这个实验便很好的证明了Verbalizer的作用: 如下图所示,以SST-2为例,相同的模板条件下,不同的label word对应的指标差异很大。

- 构建Verbalizer的方法也有很多 Prompt-Tuning——深度解读一种新的微调范式,里面说明的比较详细。
Prompt-Tuning方法
Prompt-Tuning是用来自动构建pattern的方法
根据使用场景的不同,分别介绍几种成熟的Prompt-Tuning方法。
Prompt-Oriented Fine-Tuning
需要更新全部参数(包括预训练模型参数)的Prompt-Tuning方法。
- 训练方法的本质是
将目标任务转换为适应预训练模型的预训练任务,以适应预训练模型的学习体系。
例如我们在Bert模型上做情感分类任务,
- 正常的Fine-Tuning流程,是将
训练文本经过Bert编码后,生成向量表征,再利用该向量表征,连接全连接层,实现最终的情感类别识别。- 这种方式存在一个显式的弊端:
预训练任务与下游任务存在gap
- 这种方式存在一个显式的弊端:
- Bert的预训练任务包括两个:
MLM与NSP(具体可参考Bert预训练的任务MLM和NSP)
MLM任务是通过分类模型识别被MASK掉的词,类别大小即为整个词表大小;NSP任务是预测两个句子之间的关系;
- Prompt-Oriented Fine-Tuning训练方法,是将情感分类任务转换为类似于
MLM任务的[Mask]预测任务:- 构建如下的prompt文本:
prompt = It was [MASK]. - 将prompt文本与输入text文本
text = The film is attractive.进行拼接生成It was [MASK].The film is attractive. - 输入至预训练模型中,训练任务目标和
MLM任务的目标一致,即识别被[Mask]掉的词。
- 构建如下的prompt文本:
通过这种方式,可以将下游任务转换为和预训练任务较为一致的任务,已有实验证明,Prompt-Oriented Fine-Tuning相对于常规的Fine-Tuning,效果确实会得到提升(Prompt进行情感分类)。
- 通过以上描述我们可以知道,Prompt-Oriented Fine-Tuning方法中,预训练模型参数是可变的。
- 其实将Prompt-Oriented Fine-Tuning方法放在Prompt-Tuning这个部分合理也不合理,因为它其实是
Prompt-Tuning+Fine-Tuning的结合体,将它视为Fine-Tuning的升级版是最合适的。 Prompt-Oriented Fine-Tuning方法在Bert类相对较小的模型上表现较好,但是随着模型越来越大,如果每次针对下游任务,都需要更新预训练模型的参数,资源成本及时间成本都会很高,因此后续陆续提出了不更新预训练模型参数,单纯只针对prompt进行调优的方法,例如Hard Prompt和Soft Prompt。
- 这里再给出一些常见下游任务的prompt设计:

Hard Prompt & Soft Prompt
Hard Prompt和Soft Prompt的提出,是为了解决预训练模型过大,难以针对下游任务进行训练的痛点。
目前常见的Hard Prompt和Soft Prompt方法,分为以下五种:
- Hard Prompt:
- 人工构建(Manual Template): 最简单的构建模板方法;
- 启发式法(Heuristic-based Template): 通过规则 启发式搜索等方法构建合适的模板;
- 生成(Generation): 根据给定的任务训练数据(通常是小样本场景),生成出合适的模板;
- Soft Prompt:
- 词向量微调(Word Embedding): 显式地定义离散字符的模板,但在训练时这些模板字符的词向量参与梯度下降,初始定义的离散字符用于作为向量的初始化;
- 伪标记(Pseudo Token): 不显式地定义离散的模板,而是将模板作为可训练的参数。
- Hard Prompt:
- Hard Prompt:
- 前面三种称为离散的模板构建法(记作Hard Template Hard Prompt Discrete Template Discrete Prompt),其旨在
直接与原始文本拼接显式离散的字符,且在训练中始终保持不变。 - 这里的保持不变是指这些离散字符的词向量(Word Embedding)在训练过程中保持固定。
- 通常情况下,离散法不需要引入任何参数。
- 主要适用场景是GPT-3类相对较大的模型,Bert类相对较小的模型也可以用,只是个人觉得Bert等预训练模型,针对下游任务训练的成本并不是很高,完全可以同时微调预训练模型参数。
- 上述三种Hard Prompt方法,实际场景中用的比较少
- Hard Prompt方法,不论是启发式方法,还是通过生成的方法,都需要为每一个任务单独设计对应的模板,因为这些模板都是可读的离散的token
- 这导致很难寻找到最佳的模板。
- 另外,即便是同一个任务,不同的句子也会有其所谓最佳的模板,而且有时候,即便是人类理解的相似的模板,也会对模型预测结果产生很大差异。
- 例如下图,以SNLI推断任务为例,仅仅只是修改了模板,测试结果差异很明显,因此离散的模板存在方差大 不稳定等问题。

- 如何避免这种问题呢,Soft Prompt方法便是来解决这种问题的,
- 前面三种称为离散的模板构建法(记作Hard Template Hard Prompt Discrete Template Discrete Prompt),其旨在
- Soft Prompt:
- 后面两种则被称为连续的模板构建法(记作Soft Template Soft Prompt Continuous Template Continuous Prompt),其旨在让模型在训练过程中
根据具体的上下文语义和任务目标对模板参数进行调整。 - 其将模板转换为可以进行优化的连续向量
我们不需要显式地指定这些模板中各个token具体是什么,只需要在语义空间中表示一个向量即可,这样,不同的任务 数据可以自适应地在语义空间中寻找若干合适的向量,来代表模板中的每一个词,相较于显式的token,这类token称为伪标记(
Pseudo Token)。基于Soft Prompt的模板定义:
假设针对分类任务,给定一个输入句子 $x$ , 连续提示的模板可以定义为: $\mathcal{T} =[x],[v_{1}],[v_{2}],…,[v_{m}][Mask]$ 其中 $[v_{1}]$ 则是伪标记,其仅代表一个抽象的token,并没有实际的含义,本质上是一个向量。
- 总结来说:
- Soft Prompt方法,是将模板变为可训练的参数,不同的样本可以在连续的向量空间中寻找合适的伪标记,同时也增加模型的泛化能力。
- 因此,连续法需要引入少量的参数并在训练时进行参数更新,但预训练模型参数是不变的,变的是prompt token对应的词向量(Word Embedding)表征及其他引入的少量参数。
- 主要适用场景同Hard Prompt一致。
- 目前具有代表性的三种Soft Prompt方法如下:
- 后面两种则被称为连续的模板构建法(记作Soft Template Soft Prompt Continuous Template Continuous Prompt),其旨在让模型在训练过程中
Parameter-Efficient Prompt Tuning
该方法率先提出了伪标记和连续提示的概念,支持模型能够动态地对模板在语义空间内进行调整。
主要针对的是NLU任务,形式化的描述如下:
给定 $n$ 个token,记作 $x_{1}, …, x_{n}$, 通过一个预训练模型对应的embedding table,将 $n$ 个token表征为向量矩阵 $X_{e} \in R^{n\times e}$, 其中 $e$ 是向量的维度(其与预训练模型的配置有关,例如Bert-base是768)。 连续模板中的每个伪标记 $v_{i}$ 可以视为参数,也可以视为一个token,因此,可以通过另一个embedding table将 $p$ 个伪标记token表征为向量矩阵 $P_{e} \in R^{p\times e}$ 。 将文本和prompt进行拼接获得新的输入 $[P_{e} :X_{e}] \in R^{(p+n) \times e}$。 这个新的输入将会进入T5的encoder-decoder结构来训练和推理。 注意,只有prompt对应的向量表征参数 $P_{e}$ 会随着训练进行更新。
论文中提到,每个伪标记的初始化可以有下列三种情况,分别是Random Uniform,Sampled Vocab和Class Label。
- Random Uniform: 从均匀分布中随机进行初始化;
- Sampled Vocab: 从T5的语料库中选择最常见的5000个词汇,并从中选择词汇嵌入作为初始化;
- Class Label: 是将下游任务的标签对应的字符串表示的嵌入作为初始化,如果一个类有多个词,取词嵌入的平均表示作为一个prompt。假如标签数目不足,则从Sampled Vocab方案中继续采样补足。
最后发现,非随机初始化方法要显著好于随机初始化,而Class Label效果相对更好,当然,只要模型足够大,这几种初始化方法的差异就比较小了。
具体论文
P-Tuning
P-Tuning是另一个具有代表性的连续提示方法
- 主要针对的是NLU任务
- 方法图如下所示(图中的 $P_{i}$ 等价于上文的 $v_{i}$ ,表示伪标记),
- 谷歌于2021年发表:

P-Tuning方法中的四个技巧点:
- 考虑到这些伪标记的相互依赖关系: 认为 $[P_{1}]$ 与 $[P_{2}]$ 是有先后关系的,而transformer无法显式地刻画这层关系,因此引入Prompt Encoder(BiLSTM+MLP);
- 指定上下文词: 如果模板全部是伪标记,在训练时无法很好地控制这些模板朝着与对应句子相似的语义上优化,因此选定部分具有与当前句子语义代表性的一些词作为一些伪标记的初始化(例如上图中“capital” “Britain”等);
- 重参数(Reparameterization): 具体到代码实现上,P-Tuning先通过一个Prompt Encoder表征这些伪标记后,直接将这些新的表征覆盖到对应的embedding table上,换句话说,Prompt Encoder只在训练时候会使用到,而在推理阶段则不再使用,直接使用构建好的embedding table;
- 混合提示(Hydride Prompt): 将连续提示与离散token进行混合,例如 $[x][it][v1][mask]$。
- 具体可参考:
PPT (Pre-trained Prompt Tuning)
- Prompt-Tuning通常适用于低资源场景,但是由于连续的模板是随机初始化的,即其存在新的参数,少量样本可能依然很难确保这些模板被很好地优化。
- 因此简单的方法就是对这些连续的模板进行预训练。
- PPT旨在通过先让这些连续提示在大量无标注的预训练语料进行预训练,然后将其加载到对应下游任务的PLM上进行训练。
- 具体来说,作者对3种Prompt-Tuning的优化策略在few-shot learning问题上分别进行了效果对比,包括hard prompt和soft prompt结合 label到text映射方法选择以及使用真实单词的embedding进行soft prompt的随机初始化。通过对比实验发现,hard+soft prompt结合的方法可以提升效果,但是仍然比finetune效果差。
- Label到text的映射方法对于效果影响很大,选择能够表达label对应含义的常用单词会带来最好效果。
而使用单词embedding进行soft prompt的初始化在大模型上并没有明显的效果提升。
基于以上实验结果,作者提出了Pre-trained Pormpt Tuning解决few-shot learning问题,核心思路是对soft prompt进行预训练,得到一个更好的soft prompt初始化表示。对于每种类型的任务,设计一个和其匹配的预训练任务,得到soft prompt embedding的预训练表示。
论文中以sentence-pair classification multiple-choice classification single sentence classification三种任务介绍了如何针对每种下游任务设计预训练任务学习soft prompt embedding。例如对于sentence-pair classification,作者设计了如下预训练任务。将2个句子对拼接在一起,如果两个句子来自同一个文档相邻两句话,则label为yes(完全一致);如果两个句子来自同一个文档但距离较远,则label为maybe;其他句子对label为no,如下图所示(图中的 P P P即连续的提示模板, < x >
<x\>表示mask token。最上面的任务是预训练任务,下面三个任务为下游任务)。 - 另外论文中还给出了四种微调方案,如下图所示,
[a]展示了模型的预训练过程,[b]和[c]展示了两种主流的Fine-Tuning方法(前文已经介绍过),[d]展示了提示学习( Prompt Tuning, PT )方法,
- 具体参考

Prompt-Tuning Issue
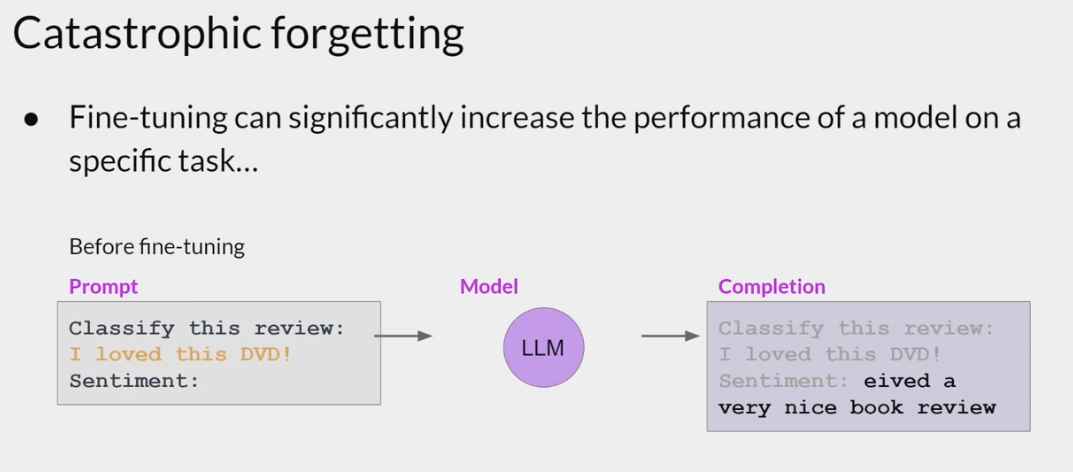
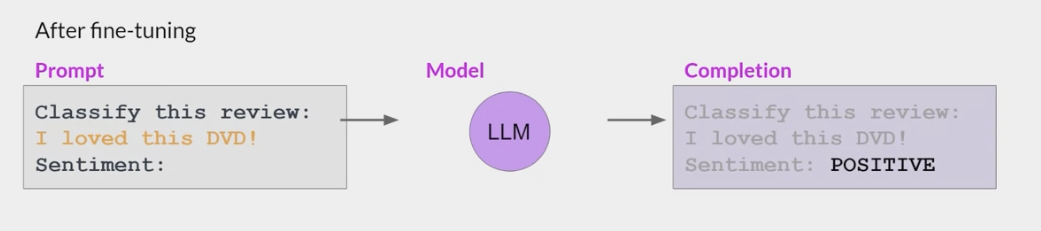
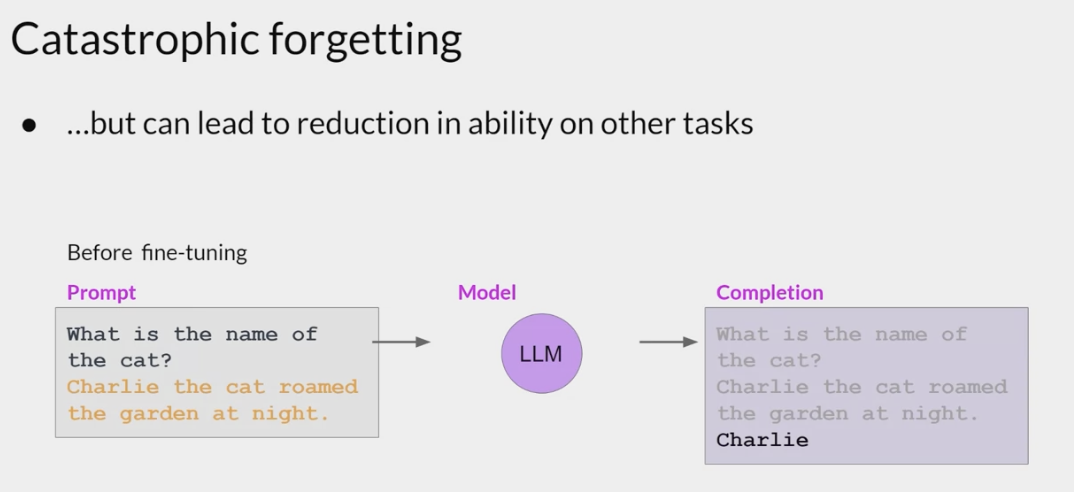
Catastrophic forgetting
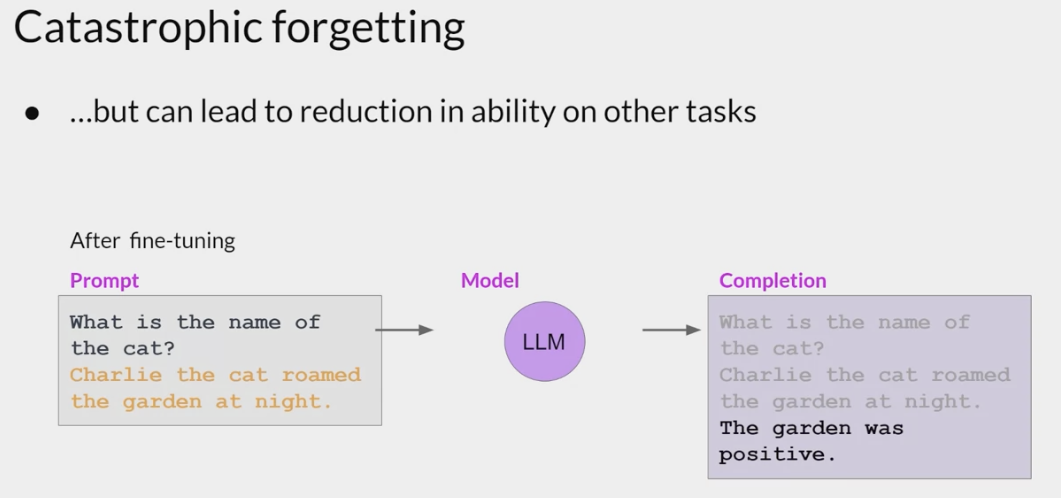
Instruction-Tuning(指示微调)
目前最火的研究范式,性能超过包括ICL在内的prompt learning
一种特别适合改进模型在多种任务上表现的策略
Instruction-Tuning的提出
提出的动机: 大规模的语言模型 如GPT-3 在zero-shot上不那么成功, 但却可以非常好地学习few-shot
- 一些模型能够识别提示中包含的指令并正确进行zero-shot推理,而较小的LLM可能在执行任务时失败,
包含一个或多个你希望模型执行的示例(称为一次或几次推理)足以帮助模型识别任务并生成良好的完成结果。
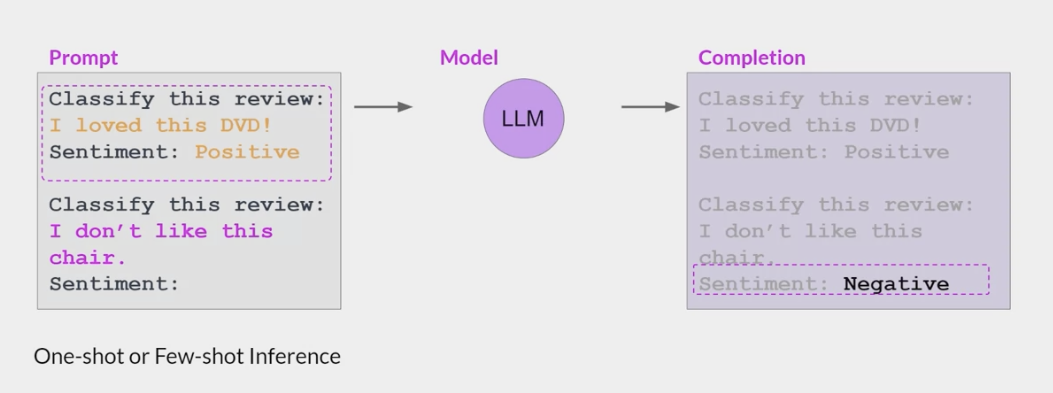
- 然而,这种策略有几个缺点。
- 对于较小的模型,即使包含五六个示例,也不总是有效。
- 提示中包含的任何示例都会占据上下文窗口中宝贵的空间,从而减少包含其他有用信息的空间。
- 例如, GPT-3在阅读理解 问题回答和自然语言推理等任务上的表现很一般,
- 然而,这种策略有几个缺点。
- Google2021年的FLAN模型《FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS》,这篇文章明确提出Instruction-Tuning(指令微调)的技术,它的本质目的是想将 NLP 任务转换为自然语言指令,再将其投入模型进行训练,通过给模型提供指令和选项的方式,使其能够提升Zero-Shot任务的性能表现。
- 作者认为一个潜在的原因是,如果在没有少量示例的zero-shot条件下,模型很难在prompts上表现很好,因为prompts可能和预训练数据的格式相差很大。
既然如此,那么为什么不直接用自然语言指令做输入呢?
- 通过设计instruction,让大规模语言模型理解指令,进而完成任务目标,而不是直接依据演示实例做文本生成。
如下图所示,不管是commonsense reasoning任务还是machine translation任务,都可以变为instruction的形式,然后利用大模型进行学习。
在这种方式下,当一个unseen task进入时,通过理解其自然语言语义可以轻松实现zero-shot的扩展,如natural language inference任务。
Instruction-Tuning 也是 ICL 的一种,只是Instruction-Tuning是将大模型在多种任务上进行微调,提升大模型的自然语言理解能力,最终实现在新任务上的zero-shot。
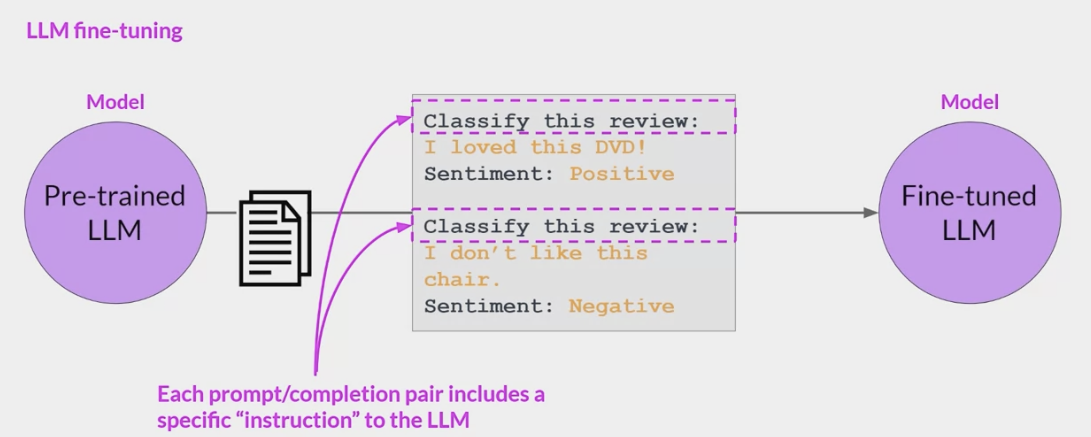
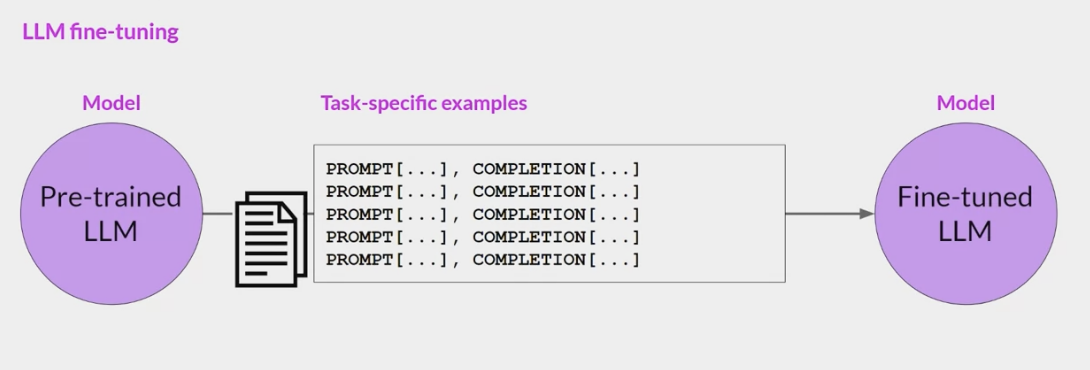
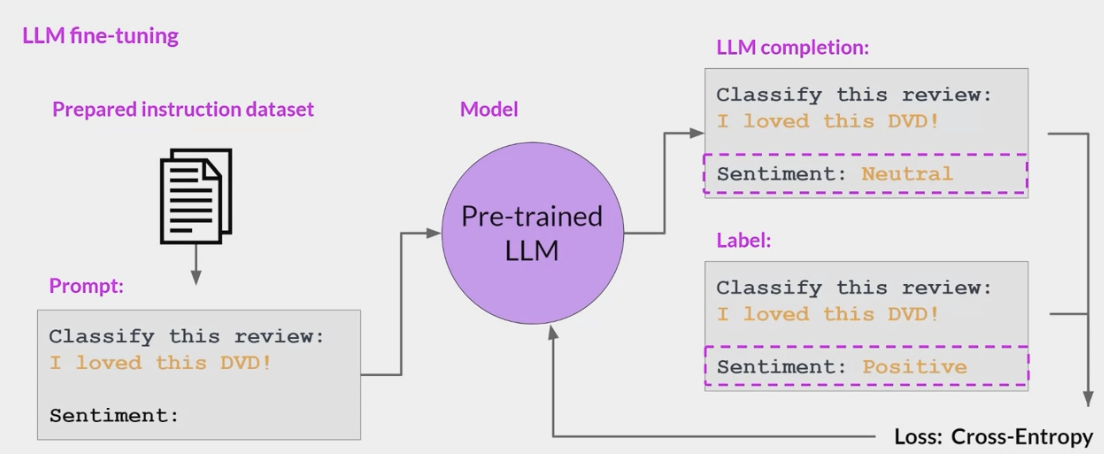
- 这些提示完成示例允许模型学习生成遵循给定指令的响应。所有模型权重都会更新的指令微调过程称为全微调。
- 该过程生成了一个具有更新权重的模型的新版本。
- 需要注意的是,与预训练一样,全微调需要足够的内存和计算预算来存储和处理所有梯度、优化器和其他在训练过程中被更新的组件。


采用了Instruction-Tuning技术的大规模语言模型
- instructGPT
- Finetuned Language Net(FLAN)
Finetuned Language Net(FLAN) 的具体训练流程:
- FLAN模型将62个NLP任务分为12个簇,同一个簇内是相同的任务类型

- 对于每个task,将为其手动构建10个独特template,作为以自然语言描述该任务的instructions。
- 为了增加多样性,对于每个数据集,还包括最多三个“turned the task around/变更任务”的模板(例如,对于情感分类,要求其生成电影评论的模板)。
- 所有数据集的混合将用于后续预训练语言模型做Instruction-Tuning,其中每个数据集的template都是随机选取的。
- 如下图所示,Premise Hypothesis Options会被填充到不同的template中作为训练数据。

- 最后基于LaMDA-PT模型进行微调。
- LaMDA-PT是一个包含137B参数的自回归语言模型,这个模型在web文档(包括代码) 对话数据和维基百科上进行了预训练,同时有大约10%的数据是非英语数据。然后FLAN混合了所有构造的数据集在128核的TPUv3芯片上微调了60个小时。
Fine-Tuning vs Prompt-Tuning vs Instruction-Tuning
- Fine-Tuning:
- 先在大规模语料上进行预训练,然后再在某个下游任务上进行微调,
- 如Bert+Fine-Tuning
- Prompt-Tuning:
- 先选择某个通用的大规模预训练模型,然后为具体的任务
生成一个prompt模板以适应大模型进行微调, - 如GPT-3+Prompt-Tuning;
- 先选择某个通用的大规模预训练模型,然后为具体的任务
- Instruction-Tuning:
- 仍然在预训练语言模型的基础上,先在多个已知任务上进行指令微调,然后在某个新任务上进行zero-shot,
- 如GPT-3+Instruction-Tuning
要提出一个好的方式那必然是用来「解决另一种方式存在的缺陷或不足」
Prompt-Tuning vs Fine-Tuning
- 预训练模型PLM+Fine-Tuning范式
- 这个范式常用的结构是Bert+Fine-Tuning,这种范式若想要预训练模型更好的应用在下游任务,需要利用下游数据对模型参数微调;
- 首先,模型在预训练的时候,采用的训练形式: 自回归 自编码,这与下游任务形式存在极大的 gap,不能完全发挥预训练模型本身的能力,必然导致较多的数据来适应新的任务形式(少样本学习能力差 容易过拟合)。
- 其次,现在的预训练模型参数量越来越大,为了一个特定的任务去Fine-Tuning一个模型,会占用特别多的训练资源,对一些中小企业或者用户来说并不现实,也会造成资源的一定浪费。
- Prompt-Tuning是在Fine-Tuning后发展起来的,可以说是解决NLP领域各种下游问题更好的一种方式。
- Prompt-Tuning则很好的解决了这些问题,它将所有下游任务统一成预训练任务,以特定的模板,将下游任务的数据转成自然语言形式,充分挖掘预训练模型本身的能力。本质上就是设计一个比较契合上游预训练任务的模板,通过模板的设计来挖掘出上游预训练模型的潜力,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务,即只需要少量数据的 Prompt Tuning,就可以实现很好的效果,具有较强的零样本/少样本学习能力。
- Prompt-Tuning VS Fine-Tuning。
Prompt-Tuning vs Instruction-Tuning:

Prompt和instruction都是指导语言模型生成输出的文本片段,但它们有着不同的含义和用途。
Prompt更多地用于帮助模型理解任务和上下文,而Instruction则更多地用于指导模型执行具体操作或完成任务。
- Prompt:
- 通常是一种短文本字符串,用于指导语言模型生成响应。
- Prompt提供上下文和任务相关信息,以帮助模型更好地理解要求,并生成正确的输出。
- Prompt通常是人类设计的,以帮助模型更好地理解特定任务或领域;
- 例如,在问答任务中,prompt可能包含问题或话题的描述,以帮助模型生成正确的答案。
- 通常是一种短文本字符串,用于指导语言模型生成响应。
- Instruction
- 通常是一种更详细的文本,用于指导模型执行特定操作或完成任务。
- Instruction可以是计算机程序或脚本,也可以是人类编写的指导性文本。
- Instruction的目的是告诉模型如何处理数据或执行某个操作,而不是简单地提供上下文或任务相关信息。
prompt在没精调的模型上也能有一定效果(模型不经过Prompt-Tuning,直接针对下游任务进行推理),而Instruction-Tuning则必须对模型精调,让模型知道这种指令模式。
- 但是,prompt也有精调,经过Prompt-Tuning之后,模型也就学习到了这个prompt模式,
- 精调之后跟Instruction-Tuning有什么区别呢?这就是Instruction-Tuning巧妙的地方了,
- Prompt-Tuning都是针对一个任务的,比如做个情感分析任务的Prompt-Tuning,精调完的模型只能用于情感分析任务,
- 而经过Instruction-Tuning多任务精调后,可以用于其他任务的zero-shot。
两者的对比主要是基于大模型。
Prompt是通过对任务进行一定的描述,或者给一些示例(ICL),来完成既定任务目标,但是如果不给模型示例(zero-shot)
prompt表现的很一般,这怎么办呢?能不能让大模型理解任务是做什么的,这样不用示例也能完成任务目标,instruction就是来做这个任务的,它为了让模型具备理解任务的能力,采用大量的指令数据,对模型进行微调,即Instruction-Tuning。
因此,instruction和prompt的不同之处在于: instruction是在prompt的基础上,进一步挖掘模型理解任务的能力
Chain-of-Thought(思维链)
随着LLM的越来越大,以及tuning技术的快速发展,LLM在包括情感分析在内的传统自然语言任务上表现越来越好,但是单纯的扩大LLM模型的参数量无法让模型在算术推理/常识推理/符号推理等推理任务上取得理想的效果。 如何提升LLM在这些推理任务上性能呢?在此前关于LLM的推理任务中,有两种方法:
- 针对下游任务对模型进行微调;
- 为模型提供少量的输入输出样例进行学习。
但是这两种方法都有着局限性,前者微调计算成本太高,后者采用传统的输入输出样例在推理任务上效果很差,而且不会随着语言模型规模的增加而有实质性的改善。此时,Chain-of-Thought应运而生。下面我们根据三篇比较有代表性的论文,详细介绍CoT的发展历程。
Manual-CoT(人工思维链)
Manual-CoT是Chain-of-Thought技术的开山之作,由Google在2022年初提出《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》。其旨在进一步提高超大规模模型在一些复杂任务上的推理能力。其认为现有的超大规模语言模型可能存在下面潜在的问题:
- 增大模型参数规模对于一些具有挑战的任务(例如算术 常识推理和符号推理)的效果并未证明有效;
- 期望探索如何对大模型进行推理的简单方法。
针对这些问题,作者提出了chain of thought (CoT)这种方法来利用大语言模型求解推理任务。
下面这个例子可以很好的说明思维链到底在做什么。左图是传统的one-shot prompting,就是拼接一个例子在query的前面。右图则是CoT的改进,就是将example中的Answer部分的一系列的推理步骤(人工构建)写出来后,再给出最终答案。逻辑就是希望模型学会一步一步的输出推理步骤,然后给出结果。 
论文中首先在算数推理(arithmetic reasoning)领域做了实验,使用了5个数学算术推理数据集: GSM8K / SVAMP / ASDiv / AQuA / MAWPS,具体的实验过程这里不再赘述,感兴趣的同学可以直接参考论文,这里直接给出实验结论(如下图): 
- CoT对小模型作用不大: 模型参数至少达到10B才有效果,达到100B效果才明显。并且作者发现,在较小规模的模型中产生了流畅但不符合逻辑的 CoT,导致了比Standard prompt更低的表现;
- CoT对复杂的问题的性能增益更大: 例如,对于GSM8K(baseline 性能最低的数据集),最大的GPT (175B GPT)和PaLM (540B PaLM)模型的性能提高了一倍以上。而对于SingleOp(MAWPS中最简单的子集,只需要一个步骤就可以解决),性能的提高要么是负数,要么是非常小;
- CoT超越SOTA: 在175B的GPT和540B的PaLM模型下,CoT在部分数据集上超越了之前的SOTA(之前的SOTA 采用的是在特定任务下对模型进行微调的模式)。
除此之外,论文中为了证明CoT的有效性,相继做了消融实验(Ablation Study) 鲁棒性实验( Robustness of Chain of Thought) 常识推理(Commonsense Reasoning)实验 符号推理(Symbolic Reasoning)实验,下面分别做以简单介绍:
消融实验: 我们知道,消融实验是通过研究移除某个组件之后的性能,证明该组件的有效性。论文中通过引入CoT的三个变种,证明CoT的有效性,结果如下图所示:

- Equation only: 把CoT中的文字去掉,只保留公式部分。结论: 效果对于原始prompt略有提升,对简单任务提升较多,但和CoT没法比,特别是对于复杂任务,几乎没有提升。
- Variable compute only: 把CoT中的token全换成点(…)。 这是为了验证额外的计算量是否是影响模型性能的因素。结论: 全换成点(…)后效果和原始prompt没什么区别,这说明计算量用的多了对结果影响很小(几乎没有影响),也说明了人工构建的CoT(token sequence)对结果影响很大。
- Chain of thought after answer: 把思维链放到生成结果之后。 这样做的原因是: 猜测CoT奏效的原因可能仅仅是这些CoT简单的让模型更好的访问了预训练期间获得的相关知识,而与推理没啥太大关系。结论: CoT放到生成的答案之后的效果和benchmark没太大区别,说明CoT的顺序逻辑推理还是起到了很大作用的(不仅仅是激活知识),换句话说,模型确实是依赖于生成的思维链一步一步得到的最终结果。
鲁棒性实验: 论文中通过annotators(标注者),exemplars(样例选择)和models(模型)三个方面对CoT进行了鲁棒性分析。如下图所示,总体结论是思维链普遍有效,但是不同的CoT构建方式/exemplars的选择/exemplars的数量/exemplars的顺序,在一定程度上影响着CoT的效果。

- 不同人构建CoT: 尽管每个人构建的CoT都不相同,但都对模型性能产生了正面的影响,说明CoT确实有效。但是另一方面,不同人给出的不同的CoT对最终结果的影响程度还是有很大不同的,说明如何更好的构建CoT是一个研究方向;
- Exemplars样本的选择: 不同的选择都会有提升,但是差异明显。特别是,在一个数据集上选择的exemplars可以用在其他数据集上,比如论文中的实验设置,对于同一种类型的问题,如算术推理,尽管在多个不同的数据集进行实验,但使用的是8个相同的exemplars,结果没有特别大的差异,说明exemplars不需要满足和test set有相同的分布;
- Exemplars样本的顺序: 整体影响不大,除了coin flip task,可能的原因是: 同一个类别的多个exemplars连续输入模型使其输出产生了偏差(bias),例如把4个负样本放到4个正样本的后面输入到模型中,可能导致模型更加倾向于输出负label;
- Exemplars样本的数量: 对于标准prompt,增加exemplars的数量对最终结果的影响不大。对于CoT,增加exemplars对模型有影响(在某些数据集上),同时也不是越大越好;
- 不同LLM上的效果: 对于一个LLM效果好的CoT exemplars set换到其他LLM上效果不一定好,也就是说CoT对模型的提升是无法在不同的LLM上传递的,这是一个局限。
关于鲁棒性实验,论文中最后指出: Prompt Engineering仍然很重要,不同的prompt(CoT)的设计/数量/顺序都会对模型产生不同的影响,且方差还是很大的。 因此未来的一个方向可能是探索一种能够获取稳健CoT(Prompts)的范式。 或许可以用一个LLM自动生成CoT用于Prompting,后面我们将介绍这种技术: Auto-CoT。
常识推理实验 & 符号推理实验: 此处我们不做过多介绍,这里给出三种推理模式的exemplars示例(绿色: 算数推理,橙色: 常识推理,蓝色: 符号推理),供大家参考:

这篇CoT开山之作首次提出思维链(CoT)的概念,思维链简单的说就是一系列中间推理步骤。这篇论文最大的贡献就是发现了在LLM生成推理任务的结果之前,先生成思维链,会使模型的推理性能有大幅度的提升,特别是在复杂的推理任务上,但是有个前提就是LLM的规模要大于10B,否则CoT没用甚至起副作用。CoT的一大好处是无需微调模型参数,仅仅是改变输入就可以改进模型的性能。随着LLM越来越大,高校和小企业可能无法承担训练LLM的成本,因此无法参与其中进行科研与实践,但CoT这个研究方向仍然可以做。对于CoT的更多细节,大家可参考《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》和思维链(Chain-of-Thought, CoT)的开山之作
4.2 Zero-shot-CoT(零示例思维链)
2022年6月东京大学和谷歌共同发表了一篇论文《Large Language Models are Zero-Shot Reasoners》,这是一篇关于预训练大型语言模型(Pretrained Large Language Models, LLMs)推理能力的探究论文。目前,LLMs被广泛运用在很多NLP任务上。同时,在提供了特定任务的示例之后,LLMs是一个非常优秀的学习者。随着思考链的提示方式(chain of thought prompting, CoT)被提出,对LLMs推理能力的探究上升到一个新的高度,这种提示方式可以引导模型通过示例中一步一步的推理方式,去解决复杂的多步推理,在数学推理(arithmetic reasoning)和符号推理(symbolic reasoning)中取得了SOTA的成果。作者在研究中发现,对拥有175B参数的GPT-3,通过简单的添加”Let’s think step by step“,可以提升模型的zero-shot能力。Zero-shot-CoT的具体格式如下图所示,论文中的具体细节这里不做过多赘述,感兴趣的同学可详读论文内容。需要注意一点的是,同等条件下,Zero-shot-CoT的性能是不及Manual-CoT的。 
4.3 Auto-CoT(自动思维链)
前文已经提到过,传统CoT的一个未来研究方向: 可以用一个LLM自动生成CoT用于Prompting,李沐老师团队在2022年10月发表的论文《AUTOMATIC CHAIN OF THOUGHT PROMPTING IN LARGE LANGUAGE MODELS》证明了这一技术方向的有效性,称为Auto-CoT。
目前较为流行的CoT方法有两种,一种是Manual-CoT,一种是Zero-shot-CoT,两种方式的输入格式如下图所示。前文我们提到过,Manual-CoT的性能是要优于Zero-shot-CoT的,关键原因在于Manual-CoT包含一些人工设计的问题 推理步骤及答案,但是这部分要花费一定的人工成本,而Auto-CoT则解决了这一痛点,具体做法是: 
- 通过多样性选取有代表性的问题;
- 对于每一个采样的问题拼接上“Let’s think step by step”(类似于 Zero-shot-CoT )输入到语言模型,让语言模型生成中间推理步骤和答案,然后把这些所有采样的问题以及语言模型生成的中间推理步骤和答案全部拼接在一起,构成少样本学习的样例,最后再拼接上需要求解的问题一起输入到语言模型中进行续写,最终模型续写出了中间的推理步骤以及答案。
总体来说,Auto-CoT是Manual-CoT和Zero-shot-CoT的结合体,如下图所示。实验证明,在十个数据集上Auto-CoT是可以匹配甚至超越Manual-CoT的性能,也就说明自动构造的CoT的问题 中间推理步骤和答案样例比人工设计的还要好,而且还节省了人工成本。
至此,我们详细介绍了三种CoT技术: Manual-CoT Zero-shot-CoT以及Auto-CoT,有关CoT的技术还有很多,需要我们慢慢学习,后续持续更新。
Tree-of-Thought (ToT)
Parameter-Efficient Fine-Tuning (PEFT 参数有效性微调)
通过前文的介绍,我们可以把Tuning分为两类:
- 全参数微调: 训练过程中更新包括模型在内的所有参数,例如Fine-Tuning Prompt-Orient Fine-Tuning等;
- 部分参数微调: 训练过程中只更新部分模型参数,或者固定模型参数,只更新少量额外添加的参数,如Parameter-Efficient Prompt Tuning P-Tuning等。
我们知道,部分参数微调模式的提出,一方面是由于资源限制,无法更新整体大模型参数,另一方面,要保证在资源有限的条件下,能够尽可能的提升大模型在下游任务上的效果。目前,针对部分参数微调的研究,正处于蓬勃发展阶段,这个研究领域有个统一的名称: Parameter-Efficient Fine-Tuning (PEFT),即参数有效性微调,PEFT方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。前文提到的Prompt-Tuning,包括P-Tuning等,都可以视为PEFT的一种。总体来说,参数有效性微调可分为三个类别:
- Prompt-Tuning: 在模型的输入或隐层添加个额外可训练的前缀 tokens(这些前缀是连续的伪tokens,不对应真实的tokens),只训练这些前缀参数,包括prefix-tuning parameter-efficient Prompt Tuning P-Tuning等;
- Adapter-Tuning: 将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为adapter(适配器),下游任务微调时也只训练这些适配器参数;
- LoRA: 通过学习小参数的低秩矩阵来近似模型权重矩阵的参数更新,训练时只优化低秩矩阵参数。
接下来,我们对其中流行的PEFT算法进行详细介绍。
5.1 PEFT介绍
Prefix-Tuning: Prefix-Tuning也是一种Prompt-Tuning,是最早提出soft-prompt的论文之一《Prefix-Tuning: Optimizing Continuous Prompts for Generation》,斯坦福大学于2021年发表。Prefix-Tuning在模型输入前添加一个连续的且任务特定的向量序列(continuous task-specific vectors),称之为前缀(prefix)。前缀同样是一系列“虚拟 tokens”,即没有真实语义。与更新所有 PLM 参数的全量微调不同,Prefix-Tuning固定PLM的所有参数,只更新优化特定任务的prefix。Prefix-Tuning与传统Fine-Tuning的对比图如下所示:
 如下图所示,Prefix-Tuning有两种模式,一种是自回归模型(例如GPT-2),在输入前添加一个前缀得到 [ P R E F I X ; x ; y ] [PREFIX;x;y] [PREFIX;x;y];另一种是encoder-decoder模型(例如Bart),在编码器和解码器前加前缀得到 [ P R E F I X ; x ; P R E F I X ′ ; y ] [PREFIX;x;PREFIX^{‘};y] [PREFIX;x;PREFIX′;y]。接下来我们以GPT-2的自回归语言模型为例,介绍下Prefix-Tuning的流程。 首先,对于传统的GPT-2模型来说,将输入 $x$ 和输出 $y$ 拼接为 z = [ x ; y ] z=[x;y] z=[x;y],其中 X i d x X_{idx} Xidx和 Y i d x Y_{idx} Yidx分别为输入和输出序列的索引, h i ∈ R d h_{i} \in R^{d} hi∈Rd是每个时间步 i i i下的激活向量(隐藏层向量), h i = [ h i ( 1 ) ; … … ; h i ( n ) ] h_{i}=[h_{i}^{(1)}; ……;h_{i}^{(n)}] hi=[hi(1);……;hi(n)]表示在当前时间步的所有激活层的拼接, h i ( j ) h_{i}^{(j)} hi(j)是时间步 i i i的第 j j j层激活层。自回归模型通过如下公式计算 $h_{i}$ ,其中 ϕ \phi ϕ是模型参数: h i = L M ϕ ( z i , h < i ) h_{i} =LM_{\phi}(z_{i},h_{<i})\ hi=LMϕ(zi,h<i) $h_{i}$ 的最后一层,用来计算下一个token的概率分布: p ϕ ( z i + 1 ∣ h ≤ i ) = s o f t m a x ( W ϕ h i ( n ) ) p_{\phi}(z_{i+1}|h_{≤i}) =softmax(W_{\phi}h_{i}^{(n)})\ pϕ(zi+1∣h≤i)=softmax(Wϕhi(n)) 其中 W ϕ W_{\phi} Wϕ是将 h i ( n ) h_{i}^{(n)} hi(n)根据词表大小进行映射。 在采用Prefix-Tuning技术后,则在输入前添加前缀,即将prefix和输入以及输出进行拼接得到 z = [ P R E F I X ; x ; y ] z=[PREFIX;x;y] z=[PREFIX;x;y], P i d x P_{idx} Pidx为前缀序列的索引, ∣ P i d x ∣ |P_{idx}| ∣Pidx∣为前缀序列的长度,这里需要注意的是,Prefix-Tuning是在模型的每一层都添加prefix(注意不是只有输入层,中间层也会添加prefix,目的增加可训练参数)。前缀序列索引对应着由 θ \theta θ参数化的向量矩阵 $P_{\theta}$ ,维度为 ∣ P i d x ∣ × d i m ( h i ) |P_{idx}|\times dim(h_{i}) ∣Pidx∣×dim(hi)。隐层表示的计算如下式所示,若索引为前缀索引 P i d x P_{idx} Pidx,直接从 $P_{\theta}$ 复制对应的向量作为 $h_{i}$ (在模型每一层都添加前缀向量);否则直接通过LM计算得到,同时,经过LM计算的 $h_{i}$ 也依赖于其左侧的前缀参数 $P_{\theta}$ ,即通过前缀来影响后续的序列激活向量值(隐层向量值)。 h i = { P θ [ i , : ] if i ∈ P i d x L M ϕ ( z i , h < i ) otherwise h_{i}= \begin{cases} P_{\theta}[i,:]& \text{if} \ \ \ i\in P_{idx}\ LM_{\phi}(z_{i},h_{<i})& \text{otherwise} \end{cases} hi={Pθ[i,:]LMϕ(zi,h<i)if i∈Pidxotherwise 在训练时,Prefix-Tuning的优化目标与正常微调相同,但只需要更新前缀向量的参数。在论文中,作者发现直接更新前缀向量的参数会导致训练的不稳定与结果的略微下降,因此采用了重参数化的方法,通过一个更小的矩阵 $P_{\theta}^{‘}$ 和一个大型前馈神经网络 $\text{MLP}{\theta}$ 对 $P{\theta}$ 进行重参数化: P θ [ i , : ] = MLP θ ( P θ ′ [ i , : ] ) P_{\theta}[i,:]=\text{MLP}{\theta}(P{\theta}^{‘}[i,:]) Pθ[i,:]=MLPθ(Pθ′[i,:]),可训练参数包括 $P_{\theta}^{‘}$ 和 $\text{MLP}{\theta}$ 的参数,其中, $P{\theta}$ 和 $P_{\theta}^{‘}$ 有相同的行维度(也就是相同的prefix length), 但不同的列维度。在训练时,LM 的参数 ϕ \phi ϕ被固定,只有前缀参数 $P_{\theta}^{‘}$ 和 $\text{MLP}{\theta}$ 的参数为可训练的参数。训练完成后, $P{\theta}^{‘}$ 和 $\text{MLP}{\theta}$ 的参数被丢掉,只有前缀参数 $P{\theta}$ 被保存。
如下图所示,Prefix-Tuning有两种模式,一种是自回归模型(例如GPT-2),在输入前添加一个前缀得到 [ P R E F I X ; x ; y ] [PREFIX;x;y] [PREFIX;x;y];另一种是encoder-decoder模型(例如Bart),在编码器和解码器前加前缀得到 [ P R E F I X ; x ; P R E F I X ′ ; y ] [PREFIX;x;PREFIX^{‘};y] [PREFIX;x;PREFIX′;y]。接下来我们以GPT-2的自回归语言模型为例,介绍下Prefix-Tuning的流程。 首先,对于传统的GPT-2模型来说,将输入 $x$ 和输出 $y$ 拼接为 z = [ x ; y ] z=[x;y] z=[x;y],其中 X i d x X_{idx} Xidx和 Y i d x Y_{idx} Yidx分别为输入和输出序列的索引, h i ∈ R d h_{i} \in R^{d} hi∈Rd是每个时间步 i i i下的激活向量(隐藏层向量), h i = [ h i ( 1 ) ; … … ; h i ( n ) ] h_{i}=[h_{i}^{(1)}; ……;h_{i}^{(n)}] hi=[hi(1);……;hi(n)]表示在当前时间步的所有激活层的拼接, h i ( j ) h_{i}^{(j)} hi(j)是时间步 i i i的第 j j j层激活层。自回归模型通过如下公式计算 $h_{i}$ ,其中 ϕ \phi ϕ是模型参数: h i = L M ϕ ( z i , h < i ) h_{i} =LM_{\phi}(z_{i},h_{<i})\ hi=LMϕ(zi,h<i) $h_{i}$ 的最后一层,用来计算下一个token的概率分布: p ϕ ( z i + 1 ∣ h ≤ i ) = s o f t m a x ( W ϕ h i ( n ) ) p_{\phi}(z_{i+1}|h_{≤i}) =softmax(W_{\phi}h_{i}^{(n)})\ pϕ(zi+1∣h≤i)=softmax(Wϕhi(n)) 其中 W ϕ W_{\phi} Wϕ是将 h i ( n ) h_{i}^{(n)} hi(n)根据词表大小进行映射。 在采用Prefix-Tuning技术后,则在输入前添加前缀,即将prefix和输入以及输出进行拼接得到 z = [ P R E F I X ; x ; y ] z=[PREFIX;x;y] z=[PREFIX;x;y], P i d x P_{idx} Pidx为前缀序列的索引, ∣ P i d x ∣ |P_{idx}| ∣Pidx∣为前缀序列的长度,这里需要注意的是,Prefix-Tuning是在模型的每一层都添加prefix(注意不是只有输入层,中间层也会添加prefix,目的增加可训练参数)。前缀序列索引对应着由 θ \theta θ参数化的向量矩阵 $P_{\theta}$ ,维度为 ∣ P i d x ∣ × d i m ( h i ) |P_{idx}|\times dim(h_{i}) ∣Pidx∣×dim(hi)。隐层表示的计算如下式所示,若索引为前缀索引 P i d x P_{idx} Pidx,直接从 $P_{\theta}$ 复制对应的向量作为 $h_{i}$ (在模型每一层都添加前缀向量);否则直接通过LM计算得到,同时,经过LM计算的 $h_{i}$ 也依赖于其左侧的前缀参数 $P_{\theta}$ ,即通过前缀来影响后续的序列激活向量值(隐层向量值)。 h i = { P θ [ i , : ] if i ∈ P i d x L M ϕ ( z i , h < i ) otherwise h_{i}= \begin{cases} P_{\theta}[i,:]& \text{if} \ \ \ i\in P_{idx}\ LM_{\phi}(z_{i},h_{<i})& \text{otherwise} \end{cases} hi={Pθ[i,:]LMϕ(zi,h<i)if i∈Pidxotherwise 在训练时,Prefix-Tuning的优化目标与正常微调相同,但只需要更新前缀向量的参数。在论文中,作者发现直接更新前缀向量的参数会导致训练的不稳定与结果的略微下降,因此采用了重参数化的方法,通过一个更小的矩阵 $P_{\theta}^{‘}$ 和一个大型前馈神经网络 $\text{MLP}{\theta}$ 对 $P{\theta}$ 进行重参数化: P θ [ i , : ] = MLP θ ( P θ ′ [ i , : ] ) P_{\theta}[i,:]=\text{MLP}{\theta}(P{\theta}^{‘}[i,:]) Pθ[i,:]=MLPθ(Pθ′[i,:]),可训练参数包括 $P_{\theta}^{‘}$ 和 $\text{MLP}{\theta}$ 的参数,其中, $P{\theta}$ 和 $P_{\theta}^{‘}$ 有相同的行维度(也就是相同的prefix length), 但不同的列维度。在训练时,LM 的参数 ϕ \phi ϕ被固定,只有前缀参数 $P_{\theta}^{‘}$ 和 $\text{MLP}{\theta}$ 的参数为可训练的参数。训练完成后, $P{\theta}^{‘}$ 和 $\text{MLP}{\theta}$ 的参数被丢掉,只有前缀参数 $P{\theta}$ 被保存。  上述内容详细介绍了Prefix-Tuning的主要训练流程,下面我们给出论文中通过实验得出的三个主要结论:
上述内容详细介绍了Prefix-Tuning的主要训练流程,下面我们给出论文中通过实验得出的三个主要结论:- 方法有效性: 作者采用了Table-To-Text与Summarization作为实验任务,在Table-To-Text任务上,Prefix-Tuning在优化相同参数的情况下结果大幅优于Adapter,并与全参数微调几乎相同。而在Summarization任务上,Prefix-Tuning方法在使用2%参数与0.1%参数时略微差于全参数微调,但仍优于Adapter微调;
- Full vs Embedding-only: Embedding-only方法只在embedding层添加前缀向量并优化,而Full代表的Prefix-Tuning不仅在embedding层添加前缀参数,还在模型所有层添加前缀并优化。实验得到一个不同方法的表达能力增强链条: discrete prompting < embedding-only < Prefix-Tuning。同时,Prefix-Tuning可以直接修改模型更深层的表示,避免了跨越网络深度的长计算路径问题;
- Prefix-Tuning vs Infix-Tuning: 通过将可训练的参数放置在 $x$ 和 $y$ 的中间来研究可训练参数位置对性能的影响,即 $[x;Infix;y]$ ,这种方式成为infix-tuning。实验表明Prefix-Tuning性能好于 infix-tuning,因为prefix能够同时影响 $x$ 和 $y$ 的隐层向量,而infix只能够影响 $y$ 的隐层向量。
我们回顾下前文提到的parameter-efficient prompt tuning(下面简称为Prompt Tuning),其论文中有提到,它可以看作是Prefix-Tuning的简化版。总结下两者的不同点:
- 参数更新策略不同: Prompt Tuning只对输入层(Embedding)进行微调,而Prefix-Tuning是对每一层全部进行微调。因此parameter-efficient prompt tuning的微调参数量级要更小(如下图),且不需要修改原始模型结构;
- 参数生成方式不同: Prompt Tuning与Prefix-Tuning及P-Tuning不同的是,没有采用任何的prompt映射层(即Prefix-Tuning中的重参数化层与P-Tuning中的prompt encoder),而是直接对prompt token对应的embedding进行了训练;
- 面向任务不同: Pompt Tuning P-Tuning以及后面要介绍的P-Tuning v2都是面向的NLU任务进行效果优化及评测的,而Prefix-Tuning针对的则是NLG任务。

- P-Tuning v2: P-Tuning v2是2022年发表的一篇论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》,总结来说是在Prefix-Tuning和P-Tuning的基础上进行的优化。下面我们简单介绍下P-Tuning v2方法。
P-Tuning v2针对Prefix-Tuning P-Tuning解决的问题:
- Prefix-Tuning是针对于生成任务而言的,不能处理困难的序列标注任务 抽取式问答等,缺乏普遍性;
- 当模型规模较小,特别是小于100亿个参数时,它们仍然不如Fine-Tuning。
P-Tuning v2的优点:
- P-Tuning v2在不同的模型规模(从300M到100B的参数)和各种困难的NLU任务(如问答和序列标注)上的表现与Fine-Tuning相匹配;
- 与Fine-Tuning相比,P-Tuning v2每个任务的可训练参数为0.1%到3%,这大大降低了训练时间的内存消耗和每个任务的存储成本。
P-Tuning v2的核心点:
- NLU任务优化: 主要针对NLU任务进行微调,提升P-Tuning v2在NLU任务上的效果;
- 深度提示优化: 参考Prefix-Tuning,不同层分别将prompt作为前缀token加入到输入序列中,彼此相互独立(注意,这部分token的向量表征是互不相同的,即同Prefix-Tuning一致,不是参数共享模式),如下图所示。通过这种方式,一方面,P-Tuning v2有更多的可优化的特定任务参数(从0.01%到0.1%-3%),以保证对特定任务有更多的参数容量,但仍然比进行完整的Fine-Tuning任务参数量小得多;另一方面,添加到更深层的提示,可以对输出预测产生更直接的影响。

P-Tuning v2的其他优化及实施点:
- 重参数化: 以前的方法利用重参数化功能来提高训练速度 鲁棒性和性能(例如,MLP的Prefix-Tuning和LSTM的P-Tuning)。然而,对于NLU任务,论文中表明这种技术的好处取决于任务和数据集。对于一些数据集(如RTE和CoNLL04),MLP的重新参数化带来了比嵌入更稳定的改善;对于其他的数据集,重参数化可能没有显示出任何效果(如BoolQ),有时甚至更糟(如CoNLL12)。需根据不同情况去决定是否使用;
- 提示长度: 提示长度在提示优化方法的超参数搜索中起着核心作用。论文中表明不同的理解任务通常用不同的提示长度来实现其最佳性能,比如一些简单的task倾向比较短的prompt(less than 20),而一些比较难的序列标注任务,长度需求比较大;
- 多任务学习: 多任务学习对P-Tuning v2方法来说是可选的,但可能是有帮助的。在对特定任务进行微调之前,用共享的prompts去进行多任务预训练,可以让prompts有比较好的初始化;
- 分类方式选择: 对标签分类任务,用原始的CLS+linear head模式替换Prompt-Tuning范式中使用的Verbalizer+LM head模式,不过效果并不明显,如下图。

- Adapter-Tuning: 《Parameter-Efficient Transfer Learning for NLP》这项2019年的工作第一次提出了Adapter方法。与Prefix-Tuning和Prompt Tuning这类在输入前添加可训练prompt embedding参数来以少量参数适配下游任务的方式不通,Adapter-Tuning 则是在预训练模型内部的网络层之间添加新的网络层或模块来适配下游任务。假设预训练模型函数表示为 $\phi_{w}(x)$ ,对于Adapter-Tuning,添加适配器之后模型函数更新为: ϕ w , w 0 ( x ) \phi_{w,w_{0}}(x) ϕw,w0(x), w w w是预训练模型的参数, $w_{0}$ 是新添加的适配器的参数,在训练过程中, w w w被固定,只有 $w_{0}$ 被更新。 ∣ w 0 ∣ ≪ ∣ w ∣ |w_{0}|\ll|w| ∣w0∣≪∣w∣,这使得不同下游任务只需要添加少量可训练的参数即可,节省计算和存储开销,同时共享大规模预训练模型。在对预训练模型进行微调时,我们可以冻结在保留原模型参数的情况下对已有结构添加一些额外参数,对该部分参数进行训练从而达到微调的效果。 论文中采用Bert作为实验模型,Adapter模块被添加到每个transformer层两次。适配器是一个 bottleneck(瓶颈)结构的模块,由一个两层的前馈神经网络(由向下投影矩阵 非线性函数和向上投影矩阵构成)和一个输入输出之间的残差连接组成。其总体结构如下(跟论文中的结构有些出入,目前没有理解论文中的结构是怎么构建出来的,个人觉得下图更准确的刻画了adapter的结构,有不同见解可在评论区沟通):
 Adapter结构有两个特点: 较少的参数 在初始化时与原结构相似的输出。在实际微调时,由于采用了down-project与up-project的架构,在进行微调时,Adapter会先将特征输入通过down-project映射到较低维度,再通过up-project映射回高维度,从而减少参数量。Adapter-Tuning只需要训练原模型0.5%-8%的参数量,若对于不同的下游任务进行微调,只需要对不同的任务保留少量Adapter结构的参数即可。由于Adapter中存在残差连接结构,采用合适的小参数去初始化Adapter就可以使其几乎保持原有的输出,使得模型在添加额外结构的情况下仍然能在训练的初始阶段表现良好。在GLUE测试集上,Adapter用了更少量的参数达到了与传统Fine-Tuning方法接近的效果。
Adapter结构有两个特点: 较少的参数 在初始化时与原结构相似的输出。在实际微调时,由于采用了down-project与up-project的架构,在进行微调时,Adapter会先将特征输入通过down-project映射到较低维度,再通过up-project映射回高维度,从而减少参数量。Adapter-Tuning只需要训练原模型0.5%-8%的参数量,若对于不同的下游任务进行微调,只需要对不同的任务保留少量Adapter结构的参数即可。由于Adapter中存在残差连接结构,采用合适的小参数去初始化Adapter就可以使其几乎保持原有的输出,使得模型在添加额外结构的情况下仍然能在训练的初始阶段表现良好。在GLUE测试集上,Adapter用了更少量的参数达到了与传统Fine-Tuning方法接近的效果。 - LoRA: LoRA是又一种PEFT方法,微软于2022年发表《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》。我们依照下图以及论文,简单介绍下LoRA的实现原理。
 LoRA原理其实并不复杂。简单理解一下,就是在模型的Linear层的旁边,增加一个“旁支”,这个“旁支”的作用,就是代替原有的参数矩阵 $W$ 进行训练。结合上图,我们来直观地理解一下这个过程,输入 x ∈ R d x\in R^{d} x∈Rd,举个例子,在普通的transformer模型中,这个 $x$ 可能是embedding的输出,也有可能是上一层transformer layer的输出,而 $d$ 一般就是768或者1024。按照原本的路线,它应该只走左边的部分,也就是原有的模型部分。 而在LoRA的策略下,增加了右侧的“旁支”,也就是先用一个Linear层 $A$ ,将数据从 $d$ 维降到 $r$ ,这个 $r$ 也就是LoRA的秩,是LoRA中最重要的一个超参数。一般会远远小于 $d$ ,尤其是对于现在的大模型, $d$ 已经不止是768或者1024,例如LLaMA-7B,每一层transformer有32个head,这样一来 $d$ 就达到了4096。接着再用第二个Linear层 $B$,将数据从 $r$ 变回 $d$ 维。最后再将左右两部分的结果相加融合,就得到了输出的hidden_state。 对于左右两个部分,右侧看起来像是左侧原有矩阵 $W$ 的分解,将参数量从 d × d d\times d d×d变成了 d × r + d × r d\times r +d\times r d×r+d×r,在 r ≪ d r\ll d r≪d的情况下,参数量就大大地降低了。熟悉各类预训练模型的同学可能会发现,这个思想其实与Albert的思想有异曲同工之处,在Albert中,作者通过两个策略降低了训练的参数量,其一是Embedding矩阵分解,其二是跨层参数共享。在Albert中,作者考虑到词表的维度很大,所以将Embedding矩阵分解成两个相对较小的矩阵,用来模拟Embedding矩阵的效果,这样一来需要训练的参数量就减少了很多。 LoRA也是类似的思想,并且它不再局限于Embedding层,而是所有出现大矩阵的地方,理论上都可以用到这样的分解。但是与Albert不同的是,Albert直接用两个小矩阵替换了原来的大矩阵,而LoRA保留了原来的矩阵 $W$ ,但是不让 $W$ 参与训练(Fine-Tuning是更新权重矩阵 $W$ ,LoRA中的 W = W 0 + B A W=W_{0}+BA W=W0+BA,但是 $W_{0}$ 不参与更新,只更新 $A$ 和 $B$),所以需要计算梯度的部分就只剩下旁支的 $A$ 和 $B$两个小矩阵。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵是0矩阵,使得模型保留原有知识,在训练的初始阶段仍然表现良好。A矩阵不采用0初始化主要是因为如果矩阵A也用0初始化,那么矩阵B梯度就始终为0(对B求梯度,结果带有A矩阵,A矩阵全0,B的梯度结果必然是0),无法更新参数。 从论文中的公式来看,在加入LoRA之前,模型训练的优化表示为: m a x Φ ∑ ( x , y ∈ Z ) ∑ t = 1 ∣ y ∣ l o g ( P Φ ( y t ∣ x , y < t ) ) max_{\Phi} \sum_{(x,y \in Z)}\sum_{t=1}^{|y|}log(P_{\Phi}(y_{t}|x,y_{<t})) maxΦ(x,y∈Z)∑t=1∑∣y∣log(PΦ(yt∣x,y<t)) 其中,模型的参数用 $\Phi$ 表示。 而加入了LoRA之后,模型的优化表示为: m a x Θ ∑ ( x , y ∈ Z ) ∑ t = 1 ∣ y ∣ l o g ( P Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) max_{\Theta} \sum_{(x,y \in Z)}\sum_{t=1}^{|y|}log(P_{\Phi_{0}+\Delta\Phi(\Theta)}(y_{t}|x,y_{<t})) maxΘ(x,y∈Z)∑t=1∑∣y∣log(PΦ0+ΔΦ(Θ)(yt∣x,y<t)) 其中,模型原有的参数是 Φ 0 \Phi_{0} Φ0,LoRA新增的参数是 Δ Φ ( Θ ) \Delta\Phi(\Theta) ΔΦ(Θ)。 从第二个式子可以看到,尽管参数看起来增加了 Δ Φ ( Θ ) \Delta\Phi(\Theta) ΔΦ(Θ),但是从前面的max的目标来看,需要优化的参数只有 Θ \Theta Θ,而根 ∣ Θ ∣ ≪ ∣ Φ 0 ∣ |\Theta|\ll |\Phi_{0}| ∣Θ∣≪∣Φ0∣,这就使得训练过程中,梯度计算量少了很多,所以就在低资源的情况下,我们可以只消耗 Θ \Theta Θ这部分的资源,这样一来就可以在单卡低显存的情况下训练大模型了。这里再多说一点,通常在实际使用中,一般LoRA作用的矩阵是注意力机制部分的 W Q W_{Q} WQ W K W_{K} WK W V W_{V} WV矩阵(即与输入相乘获取 Q Q Q K K K V V V的权重矩阵。这三个权重矩阵的数量正常来说,分别和heads的数量相等,但在实际计算过程中,是将多个头的这三个权重矩阵分别进行了合并,因此每一个transformer层都只有一个 W Q W_{Q} WQ W K W_{K} WK W V W_{V} WV矩阵)。下面介绍下LoRA架构的优点:
LoRA原理其实并不复杂。简单理解一下,就是在模型的Linear层的旁边,增加一个“旁支”,这个“旁支”的作用,就是代替原有的参数矩阵 $W$ 进行训练。结合上图,我们来直观地理解一下这个过程,输入 x ∈ R d x\in R^{d} x∈Rd,举个例子,在普通的transformer模型中,这个 $x$ 可能是embedding的输出,也有可能是上一层transformer layer的输出,而 $d$ 一般就是768或者1024。按照原本的路线,它应该只走左边的部分,也就是原有的模型部分。 而在LoRA的策略下,增加了右侧的“旁支”,也就是先用一个Linear层 $A$ ,将数据从 $d$ 维降到 $r$ ,这个 $r$ 也就是LoRA的秩,是LoRA中最重要的一个超参数。一般会远远小于 $d$ ,尤其是对于现在的大模型, $d$ 已经不止是768或者1024,例如LLaMA-7B,每一层transformer有32个head,这样一来 $d$ 就达到了4096。接着再用第二个Linear层 $B$,将数据从 $r$ 变回 $d$ 维。最后再将左右两部分的结果相加融合,就得到了输出的hidden_state。 对于左右两个部分,右侧看起来像是左侧原有矩阵 $W$ 的分解,将参数量从 d × d d\times d d×d变成了 d × r + d × r d\times r +d\times r d×r+d×r,在 r ≪ d r\ll d r≪d的情况下,参数量就大大地降低了。熟悉各类预训练模型的同学可能会发现,这个思想其实与Albert的思想有异曲同工之处,在Albert中,作者通过两个策略降低了训练的参数量,其一是Embedding矩阵分解,其二是跨层参数共享。在Albert中,作者考虑到词表的维度很大,所以将Embedding矩阵分解成两个相对较小的矩阵,用来模拟Embedding矩阵的效果,这样一来需要训练的参数量就减少了很多。 LoRA也是类似的思想,并且它不再局限于Embedding层,而是所有出现大矩阵的地方,理论上都可以用到这样的分解。但是与Albert不同的是,Albert直接用两个小矩阵替换了原来的大矩阵,而LoRA保留了原来的矩阵 $W$ ,但是不让 $W$ 参与训练(Fine-Tuning是更新权重矩阵 $W$ ,LoRA中的 W = W 0 + B A W=W_{0}+BA W=W0+BA,但是 $W_{0}$ 不参与更新,只更新 $A$ 和 $B$),所以需要计算梯度的部分就只剩下旁支的 $A$ 和 $B$两个小矩阵。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵是0矩阵,使得模型保留原有知识,在训练的初始阶段仍然表现良好。A矩阵不采用0初始化主要是因为如果矩阵A也用0初始化,那么矩阵B梯度就始终为0(对B求梯度,结果带有A矩阵,A矩阵全0,B的梯度结果必然是0),无法更新参数。 从论文中的公式来看,在加入LoRA之前,模型训练的优化表示为: m a x Φ ∑ ( x , y ∈ Z ) ∑ t = 1 ∣ y ∣ l o g ( P Φ ( y t ∣ x , y < t ) ) max_{\Phi} \sum_{(x,y \in Z)}\sum_{t=1}^{|y|}log(P_{\Phi}(y_{t}|x,y_{<t})) maxΦ(x,y∈Z)∑t=1∑∣y∣log(PΦ(yt∣x,y<t)) 其中,模型的参数用 $\Phi$ 表示。 而加入了LoRA之后,模型的优化表示为: m a x Θ ∑ ( x , y ∈ Z ) ∑ t = 1 ∣ y ∣ l o g ( P Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) max_{\Theta} \sum_{(x,y \in Z)}\sum_{t=1}^{|y|}log(P_{\Phi_{0}+\Delta\Phi(\Theta)}(y_{t}|x,y_{<t})) maxΘ(x,y∈Z)∑t=1∑∣y∣log(PΦ0+ΔΦ(Θ)(yt∣x,y<t)) 其中,模型原有的参数是 Φ 0 \Phi_{0} Φ0,LoRA新增的参数是 Δ Φ ( Θ ) \Delta\Phi(\Theta) ΔΦ(Θ)。 从第二个式子可以看到,尽管参数看起来增加了 Δ Φ ( Θ ) \Delta\Phi(\Theta) ΔΦ(Θ),但是从前面的max的目标来看,需要优化的参数只有 Θ \Theta Θ,而根 ∣ Θ ∣ ≪ ∣ Φ 0 ∣ |\Theta|\ll |\Phi_{0}| ∣Θ∣≪∣Φ0∣,这就使得训练过程中,梯度计算量少了很多,所以就在低资源的情况下,我们可以只消耗 Θ \Theta Θ这部分的资源,这样一来就可以在单卡低显存的情况下训练大模型了。这里再多说一点,通常在实际使用中,一般LoRA作用的矩阵是注意力机制部分的 W Q W_{Q} WQ W K W_{K} WK W V W_{V} WV矩阵(即与输入相乘获取 Q Q Q K K K V V V的权重矩阵。这三个权重矩阵的数量正常来说,分别和heads的数量相等,但在实际计算过程中,是将多个头的这三个权重矩阵分别进行了合并,因此每一个transformer层都只有一个 W Q W_{Q} WQ W K W_{K} WK W V W_{V} WV矩阵)。下面介绍下LoRA架构的优点:- 全量微调的一般化: LoRA 不要求权重矩阵的累积梯度更新在适配过程中具有满秩。当对所有权重矩阵应用 LoRA 并训练所有偏差时,将 LoRA 的秩 $r$ 设置为预训练权重矩阵的秩,就能大致恢复了全量微调的表现力。也就是说,随着增加可训练参数的数量,训练 LoRA 大致收敛于训练原始模型;
- 没有额外的推理延时: 在生产部署时,可以明确地计算和存储 W = W 0 + B A W=W_{0}+BA W=W0+BA,并正常执行推理。当需要切换到另一个下游任务时,可以通过减去 B A BA BA来恢复 $W_{0}$ ,然后增加一个不同的 B ′ A ′ B^{‘}A^{‘} B′A′,这是一个只需要很少内存开销的快速运算。最重要的是,与Fine-Tuning的模型相比,LoRA 推理过程中没有引入任何额外的延迟(将 B A BA BA加到原参数 $W_{0}$ 上后,计算量是一致的);
- 减少内存和存储资源消耗: 对于用Adam训练的大型Transformer,若 r ≪ d m o d e l r\ll d_{model} r≪dmodel,LoRA 减少2/3的显存用量(训练模型时,模型参数往往都会存储在显存中),因为不需要存储已固定的预训练参数的优化器状态,可以用更少的GPU进行大模型训练。在175B的GPT-3上,训练期间的显存消耗从1.2TB减少到350GB。在有且只有query和value矩阵被调整的情况下,checkpoint的大小大约减少了10000倍(从350GB到35MB)。另一个好处是,可以在部署时以更低的成本切换任务,只需更换 LoRA 的权重,而不是所有的参数。可以创建许多定制的模型,这些模型可以在将预训练模型的权重存储在显存中的机器上进行实时切换。在175B的GPT-3上训练时,与完全微调相比,速度提高了25%,因为我们不需要为绝大多数的参数计算梯度;
- 更长的输入: 相较P-Tuning等soft-prompt方法,LoRA最明显的优势,就是不会占用输入token的长度。
- AdaLoRA: AdaLoRA是发表于2023年3月《ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING》,论文并未仔细阅读,简单来说,论文中发现对不同类型权重矩阵或者不同层的权重矩阵应用LoRA方法,产生的效果是不同的,如下图所示。
 在参数预算有限的情况下(例如限定模型可微调参数的数量),如何智能的选取更重要的参数进行更新,显得尤为重要。论文中提出的解决办法,是先对LoRA对应的权重矩阵进行SVD分解,即: W = W 0 + Δ = W 0 + B A = W 0 + P Λ Q W=W_{0}+\Delta=W_{0}+BA=W_{0}+P\Lambda Q\ W=W0+Δ=W0+BA=W0+PΛQ 其中: Δ \Delta Δ称为增量矩阵, W ∈ R d 1 × d 2 W\in R^{d1 \times d2} W∈Rd1×d2, P ∈ R d 1 × r P\in R^{d1 \times r} P∈Rd1×r, Q ∈ R r × d 2 Q\in R^{r \times d2} Q∈Rr×d2, Λ ∈ R r × r \Lambda\in R^{r \times r} Λ∈Rr×r, r ≪ m i n ( d 1 , d 2 ) r\ll min(d1,d2) r≪min(d1,d2)。再根据重要性指标动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。具体可参考论文简介ADAPTIVE BUDGET ALLOCATION FOR PARAMETER- EFFICIENT FINE-TUNING 。
在参数预算有限的情况下(例如限定模型可微调参数的数量),如何智能的选取更重要的参数进行更新,显得尤为重要。论文中提出的解决办法,是先对LoRA对应的权重矩阵进行SVD分解,即: W = W 0 + Δ = W 0 + B A = W 0 + P Λ Q W=W_{0}+\Delta=W_{0}+BA=W_{0}+P\Lambda Q\ W=W0+Δ=W0+BA=W0+PΛQ 其中: Δ \Delta Δ称为增量矩阵, W ∈ R d 1 × d 2 W\in R^{d1 \times d2} W∈Rd1×d2, P ∈ R d 1 × r P\in R^{d1 \times r} P∈Rd1×r, Q ∈ R r × d 2 Q\in R^{r \times d2} Q∈Rr×d2, Λ ∈ R r × r \Lambda\in R^{r \times r} Λ∈Rr×r, r ≪ m i n ( d 1 , d 2 ) r\ll min(d1,d2) r≪min(d1,d2)。再根据重要性指标动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。具体可参考论文简介ADAPTIVE BUDGET ALLOCATION FOR PARAMETER- EFFICIENT FINE-TUNING 。 - BitFit: BitFit(Bias-term Fine-tuning)发表于2022年BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models的思想更简单,其不需要对预训练模型做任何改动,只需要指定神经网络中的偏置(Bias)为可训练参数即可,BitFit的参数量只有不到2%,但是实验效果可以接近全量参数。
5.2 PEFT实践
实验环境: 2张A30卡(单卡显存24G),CentOS7。
显存占用: 如下表。
模型方案
训练方案
显存占用
ChatGLM-6B+P-Tuning v2
单卡训练
8G左右
ChatGLM2-6B+P-Tuning v2
单卡训练
8G左右
ChatGLM-6B+LoRA
两卡DDP
单卡13G左右
ChatGLM2-6B+LoRA
两卡DDP
单卡13G左右
ChatGLM-6B+LoRA+int8量化
两卡流水线并行
两卡13G左右
ChatGLM2-6B+LoRA+int8量化
两卡流水线并行
两卡27G左右
ChatGLM-6B+LoRA
两卡Deepspeed
单卡11G左右
ChatGLM-6B微调实践:
ChatGLM-6B + P-Tuning v2 ⇒ \Rightarrow ⇒官方任务实践: 【官方教程】ChatGLM-6B 微调。
- 模型下载: 下载ChatGLM-6B模型的方法很多,这里介绍官方给出的最快下载方式。
下载模型实现: 由于下载整体模型较慢,所以我们先下载模型实现,再手动下载模型参数文件。下载模型实现前,需先安装Git LFS,安装好之后再下载模型实现。
1
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b
手动下载模型参数文件:
脚本方式(推荐):
1 2 3 4 5 6 7
git clone git@github.com:chenyifanthu/THU-Cloud-Downloader.git cd THU-Cloud-Downloader pip install argparse requests tqdm python main.py --link https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/ --save ../chatglm-6b
直接下载: 从ChatGLM-6B中将所有文件下载下来,替换模型实现步骤下载的文件夹
./chatglm-6b中的文件。百度网盘下载: 为了防止官方微调模型,导致模型与训练代码不适配,在百度网盘保存了一份模型参数文件,优先级较低,大家按需提取。链接: ChatGLM-6B,提取码: 0314。
下载训练代码: ChatGLM-6B。
1
git clone git@github.com:THUDM/ChatGLM-6B.git
同上文模型下载一致,官网代码存在更新的可能,若想顺利运行本项目,可从百度网盘下载代码。链接: ChatGLM-6B, 提取码: 0314。
试用原始模型:
安装包:
1 2 3 4 5 6 7 8 9 10 11
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 具体安装包 protobuf transformers==4.27.1 cpm_kernels torch>=1.10 gradio mdtex2html sentencepiece accelerate
模型试用: 进行简单试用的启动命令,不使用量化,单卡显存13G左右,使用8bit量化,单卡显存8G左右。
1
CUDA_VISIBLE_DEVICES=1 python cli_demo.py
注意:
- 模型路径: 因为前文中,我们已经下载了chatglm-6B模型,因此使用原始模型进行试用时,需要修改模型下载路径,即将
cli_demo.py和web_demo.py中的tokenizer和model加载路径,THUDM/chatglm-6b修改为本地路径。后面包括训练在内的所有过程,都要注意这一点,就不重复赘述。
- 模型路径: 因为前文中,我们已经下载了chatglm-6B模型,因此使用原始模型进行试用时,需要修改模型下载路径,即将
量化细节: 如上图所示,量化的处理方式也进行了标记。量化操作一般用于推理,加快推理速度,训练过程一般不采用此操作。同时,量化操作是作用于部分参数,将这部分参数转换为8位整数表示,同时将
requires_grad属性置为False。训练前安装包:
1
pip install rouge_chinese nltk jieba datasets
数据集下载: Tsinghua Cloud。下载至目录
./ptuning,ADGEN数据集任务为根据输入(content)生成一段广告词(summary)。1 2 3 4
{ "content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳", "summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。" }启动训练:
1 2
cd ./ptuning sh train.sh
- 注意: 训练过程中可能会出现错误init_process_group error,可按照fix pturning init_process_group error进行解决。
模型推理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89
#!/usr/bin/env python3 # -*- coding: UTF-8 -*- ################################################################################ # # Copyright (c) 2023 Baidu.com, Inc. All Rights Reserved # ################################################################################ """ File : predict.py brief : brief Date : 2023/07/03 08:00:52 Author : zhangce06 Contact : zhangce06@baidu.com """ from transformers import AutoConfig, AutoModel, AutoTokenizer import torch import os import platform import signal import readline # pre_seq_len = 128 # 载入Tokenizer tokenizer = AutoTokenizer.from_pretrained("../../chatglm-6b-model", trust_remote_code=True) config = AutoConfig.from_pretrained("../../chatglm-6b-model", trust_remote_code=True, pre_seq_len=128) # config.pre_seq_len = pre_seq_len model = AutoModel.from_pretrained("../../chatglm-6b-model", config=config, trust_remote_code=True) CHECKPOINT_PATH = "output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-3000" prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin")) new_prefix_state_dict = {} for k, v in prefix_state_dict.items(): if k.startswith("transformer.prefix_encoder."): new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict) # 之后根据需求可以进行量化 # Comment out the following line if you don't use quantization model = model.quantize(4) model = model.half().cuda() model.transformer.prefix_encoder.float() model = model.eval() os_name = platform.system() clear_command = 'cls' if os_name == 'Windows' else 'clear' stop_stream = False def build_prompt(history): prompt = "欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序" for query, response in history: prompt += f"\n\n用户: {query}" prompt += f"\n\nChatGLM-6B: {response}" return prompt def signal_handler(signal, frame): global stop_stream stop_stream = True def main(): history = [] global stop_stream print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序") while True: query = input("\n用户: ") if query.strip() == "stop": break if query.strip() == "clear": history = [] os.system(clear_command) print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序") continue count = 0 for response, history in model.stream_chat(tokenizer, query, history=history): if stop_stream: stop_stream = False break else: count += 1 if count % 8 == 0: os.system(clear_command) print(build_prompt(history), flush=True) signal.signal(signal.SIGINT, signal_handler) os.system(clear_command) print(build_prompt(history), flush=True) if __name__ == "__main__": main()灾难性遗忘问题: 在该数据集上进行微调后,会出现灾难性遗忘的情况,在数据集有限的情况下,目前通过实践总结出下面三种做法,可在一定程度上缓解灾难性遗忘
- 学习率调整: 通过调整学习率进行解决的灾难性遗忘问题;
- 采用LoRA方法: 参见「ChatGLM-6B + LoRA ⇒ \Rightarrow ⇒真实任务实践」;
- 采用ChatGLM2-6B: ChatGLM2-6B确实比ChatGLM-6B强。使用相同的超参数进行微调训练,ChatGLM2-6B在上述的广告数据集上微调后,确实没有出现灾难性遗忘的问题。不过仍然存在其他问题,大家自行体验。下面简单介绍下,使用ChatGLM2-6B复用ChatGLM-6B进行P-Tuning v2流程需要注意的点。
- 模型下载: 模型下载方式同ChatGLM-6B相同,先下载模型实现ChatGLM2-6B,再下载模型参数文件ChatGLM2-6B,注意这里博主是直接手动下载的,脚本下载方式没有尝试成功,大家可以试一试。
- 百度网盘下载: 同样在百度网盘保存了一份模型参数文件,优先级较低,大家按需提取。链接: ChatGLM2-6B,提取码: 0625。
- 下载训练代码: ChatGLM2-6B官方没有微调代码,因此微调代码博主还是采用的ChatGLM-6B的代码ChatGLM-6B,下载方式不变。如果只是试用ChatGLM2-6B,则可以下载ChatGLM2-6B的官方代码ChatGLM2-6B(百度网盘下载方式,链接: ChatGLM2-6B,提取码: 0625),试用方式也同ChatGLM-6B一致。不论是微调还是试用,记得更换模型文件路径。
试用细节: ChatGLM-6B试用时,可以使用半精度FP16加载模型,命令是
model.half(),ChatGLM2-6B则不用,因为其本身就是半精度状态。可通过如下命令查看模型参数的精度构成,可以发现,未使用FP16加载模型前,ChatGLM-6B的模型参数精度是FP16和FP32混合的,ChatGLM2-6B则只有FP16精度的参数。1 2 3 4
model = AutoModel.from_pretrained("../../chatglm-6b-model", trust_remote_code=True) for name, param in model.named_parameters(): if param.requires_grad == True: print(f"{name},------------,{param.dtype}")
安装包: ChatGLM2-6B需要适配更高版本的transformers和pytorch,才能发挥推理性能的优势。因此,试用ChatGLM2-6B时,安装包如下:
1 2 3 4 5 6 7 8 9
# 具体安装包 protobuf transformers==4.30.2 cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate
如果需要微调ChatGLM2-6B,则同ChatGLM-6B一致,安装如下python包:
1
pip install rouge_chinese nltk jieba datasets
- 数据集下载: 无变化,同ChatGLM-6B一致。
启动训练: 基本无变化,大体流程同ChatGLM-6B一致。有两个地方需要注意,一个是脚本
./ptuning/train.sh中的各种文件路径按需调整;另一个是./ptuning/main.py文件line 220左右进行如下修改:1 2 3 4 5 6 7 8 9
# 适配ChatGLM1 # context_length = input_ids.index(tokenizer.bos_token_id) # mask_position = context_length - 1 # labels = [-100] * context_length + input_ids[mask_position+1:] # 适配ChatGLM2 context_length = len(input_ids) - len(b_ids) mask_position = context_length labels = [-100] * context_length + input_ids[mask_position:]```
- 模型推理: 基本无变化,同样注意修改模型文件路径。
- 模型下载: 模型下载方式同ChatGLM-6B相同,先下载模型实现ChatGLM2-6B,再下载模型参数文件ChatGLM2-6B,注意这里博主是直接手动下载的,脚本下载方式没有尝试成功,大家可以试一试。
- 模型下载: 下载ChatGLM-6B模型的方法很多,这里介绍官方给出的最快下载方式。
ChatGLM-6B + LoRA ⇒ \Rightarrow ⇒官方任务实践: 参考代码ChatGLM_Tuning,实现了ChatGLM-6B基于LoRA的微调流程。具体代码见LLM微调实践。模型文件同样可根据前文的方法进行获取,其中官方的模型可能存在更新,如果想顺利复现训练过程,建议从网盘进行下载。
LoRA配置参数:
1 2 3 4 5 6 7 8 9 10 11
r: lora矩阵的秩,矩阵A和矩阵B相连接的宽度,r<<d,以 int 表示。较低的秩会导致较小的更新矩阵和较少的可训练参数 target_modules: 模型中使用LoRA更新矩阵的模块,模型中常见的是,更新注意力模块 lora_alpha : LoRA缩放因子 bias : 指定是否应训练bias 参数。"none": 均不可;"all": 均可;"lora_only": 只有lora部分的bias可训练 lora_dropout: lora层的dropout比率 task_type: 模型任务类型,例如CAUSAL_LM任务
- 注意:
- 参数更新: 模型经过LoRA配置加载后,可更新模型参数只有LoRA部分,且参数精度被重置为FP32;
- 量化方式:
load_in_8bit=True和quantize(8)区别,LoRA微调时只能用前者,由bitsandbytes库提供;P-Tuning v2可以采用后者,参考量化方式区别。
- 注意:
训练启动方式:
数据并行:
1 2 3 4 5
# 切换路径 cd chatglm-ft-lora/ # 启动训练 CUDA_VISIBLE_DEVICES=1,2 torchrun --nproc_per_node=2 train.py --train_args_file ./conf/chatglm2_6b_lora.json --model_name_or_path ../../chatglm2-6b-model/ --data_path ./data/AdvertiseGen/train.jsonl --max_input_length 128 --max_output_length 256
模型(流水线)并行:
1 2 3 4 5
# 切换路径 cd ./chatglm-ft-lora/ # 启动训练 CUDA_VISIBLE_DEVICES=1,2 python train.py --train_args_file ./conf/chatglm_6b_lora.json --model_name_or_path ../../chatglm-6b-model/ --data_path ./data/AdvertiseGen/train.jsonl --max_input_length 128 --max_output_length 256 --int8
- 注意: 进行模型并行训练时,需要注意一个问题,即安装包问题。
- 安装包问题: 采用模型并行时,还需安装
acceleratebitsandbytesscipytensorboardX四个安装包。
- 安装包问题: 采用模型并行时,还需安装
- 注意: 进行模型并行训练时,需要注意一个问题,即安装包问题。
ChatGLM2-6B + LoRA ⇒ \Rightarrow ⇒官方任务实践: 实现了ChatGLM2-6B基于LoRA的微调流程。具体代码见LLM微调实践。模型文件同样可根据前文的方法进行获取,其中官方的模型可能存在更新,如果想顺利复现训练过程,建议从网盘进行下载。
- LoRA配置参数: 同ChatGLM-6B;
- 训练启动方式:
数据并行:
1 2 3 4 5
# 切换路径 cd ./chatglm2-ft-lora/ # 启动训练 CUDA_VISIBLE_DEVICES=1,2 torchrun --nproc_per_node=2 train.py --train_args_file ./conf/chatglm2_6b_lora.json --model_name_or_path ../../chatglm2-6b-model/ --data_path ./data/AdvertiseGen/train.jsonl --max_input_length 128 --max_output_length 256
- 注意: 使用ChatGLM2-6B进行数据并行训练时,需要注意一个问题,即并行问题。
并行问题: 实际运行时,如果报错如下,说明显存不够了,我当时因为另一张卡并非完全空余,就修改了并行策略,只采用了单卡训练。
1 2 3 4 5
# 错误内容 RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)` # 单卡训练 CUDA_VISIBLE_DEVICES=1 torchrun --nproc_per_node=1 train.py --train_args_file ./conf/chatglm2_6b_lora.json --model_name_or_path ../../chatglm2-6b-model/ --data_path ./data/AdvertiseGen/train.jsonl --max_input_length 128 --max_output_length 256 ```
- 注意: 使用ChatGLM2-6B进行数据并行训练时,需要注意一个问题,即并行问题。
模型(流水线)并行:
1 2 3 4 5
# 切换路径 cd chatglm2-ft-lora/ # 启动训练 CUDA_VISIBLE_DEVICES=1,2 python train.py --train_args_file ./conf/chatglm2_6b_lora.json --model_name_or_path ../../chatglm2-6b-model/ --data_path ./data/AdvertiseGen/train.jsonl --max_input_length 128 --max_output_length 256 --int8
- 注意: 进行模型并行训练时,需要注意两个问题,即安装包问题 模型源码修改问题。
- 安装包问题: 采用模型并行时,还需安装
acceleratebitsandbytesscipytensorboardX四个安装包; 模型源码修改问题: 采用模型并行训练时,如果报错如下
found at least two devices, cuda:1 and cuda:0!,是模型源码问题。如果采用官方模型,可能这个bug已经被修复,但是如果采用的是百度网盘下载的模型,这个问题可能会出现,因此需要解决掉。解决办法可参考bug修复。具体来说,对modeling_chatglm.py文件的955行代码附近做如下修改(只修改一行,其余不变):1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
# 原代码 loss = None if labels is not None: lm_logits = lm_logits.to(torch.float32) # Shift so that tokens < n predict n shift_logits = lm_logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() #<<<------------------看这里 # Flatten the tokens loss_fct = CrossEntropyLoss(ignore_index=-100) loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) lm_logits = lm_logits.to(hidden_states.dtype) loss = loss.to(hidden_states.dtype) if not return_dict: output = (lm_logits,) + transformer_outputs[1:] return ((loss,) + output) if loss is not None else output return CausalLMOutputWithPast( loss=loss, logits=lm_logits, past_key_values=transformer_outputs.past_key_values, hidden_states=transformer_outputs.hidden_states, attentions=transformer_outputs.attentions, ) # 修改为 loss = None if labels is not None: lm_logits = lm_logits.to(torch.float32) # Shift so that tokens < n predict n shift_logits = lm_logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous().to(shift_logits.device) #<<<--------------------看这里 # Flatten the tokens loss_fct = CrossEntropyLoss(ignore_index=-100) loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) lm_logits = lm_logits.to(hidden_states.dtype) loss = loss.to(hidden_states.dtype) if not return_dict: output = (lm_logits,) + transformer_outputs[1:] return ((loss,) + output) if loss is not None else output return CausalLMOutputWithPast( loss=loss, logits=lm_logits, past_key_values=transformer_outputs.past_key_values, hidden_states=transformer_outputs.hidden_states, attentions=transformer_outputs.attentions, )
- 安装包问题: 采用模型并行时,还需安装
- 注意: 进行模型并行训练时,需要注意两个问题,即安装包问题 模型源码修改问题。
ChatGLM-6B + LoRA + Accelerate + Deepspeed ⇒ \Rightarrow ⇒官方任务实践: 参考了代码LLM-tuning,实现了该流程,具体代码见LLM微调实践。ChatGLM2-6B可参考前文代码,对tokensize改写,进行适配训练即可。由于Deepspeed框架对环境依赖性很高,因此我们采用docker技术,构建cuda11.7+torch2.0.0+python3.10虚拟环境。Docker构建的具体方法参考Docker基础知识,此处简要介绍整体流程。
Docker容器构建:
1 2 3 4 5 6 7 8
# 运行容器 docker run -itd -v 宿主机路径:容器路径 --shm-size=8gb --rm --runtime=nvidia --gpus all --network host --name GPU-Docker nvidia/cuda:11.7.1-devel-ubi8 /bin/bash # 进入容器 docker exec -it GPU-Docker /bin/bash # 注 --shm-size=8gb必须加上,不然运行代码会报存储错误
Python环境构建:
- Python安装: 自行下载Python3.10版本的Miniconda ;
注: 记得在容器内设定Python环境变量
1 2 3
vi ~/.bashrc export PATH=/home/LLM/ChatGLM-FT/miniconda3/bin:$PATH source ~/.bashrc
- 虚拟环境构建: 参考Python基础知识;
依赖包安装: 以下所有安装包的版本都是推荐,可按实际情况自行调整。
1 2 3 4 5 6 7 8 9 10
# torch安装 pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu117 # 其他模块安装 pip install transformers==4.31.0 pip install datasets==2.14.0 pip install peft==0.4.0 pip install accelerate==0.21.0 pip install deepspeed==0.10.0 pip install sentencepiece==0.1.99
训练启动方式:
1 2 3 4 5
# 切换路径 cd ./chatglm-ft-lora-dp/ # 启动训练 accelerate launch --config_file ./conf/accelerate_config.yaml
- 模型加载说明:
empty_init=False: 目前如果使用Deepspeed进行训练,在加载ChatGLM模型时,参数empty_init必须置为False(参考empty_init问题),后续官方可能会更新源码,修复该问题;trust_remote_code=True: 加载模型代码时,加上此参数,防止报错;torch_dtype=torch.float16,FP16加载模型;args.base_model: 模型文件路径,最后一定是以/结尾,如./chatglm-6b-model/,./chatglm-6b-model会报错。1 2 3 4 5 6
model = AutoModel.from_pretrained( args.base_model, empty_init=False, torch_dtype=torch.float16, trust_remote_code=True )
注意: 模型训练过程中,如果出现如下错误:
ValueError: max() arg is an empty sequence,需要对deepspeed源码进行修改。1 2 3 4 5 6 7 8 9 10 11 12 13 14
# 源码路径 ./miniconda3/envs/zhangce-dp/lib/python3.10/site-packages/deepspeed/runtime/zero/stage3.py # 原代码 largest_partitioned_param_numel = max([ max([max(tensor.numel(), tensor.ds_numel) for tensor in fp16_partitioned_group]) for fp16_partitioned_group in self.fp16_partitioned_groups ]) # 修改后代码 largest_partitioned_param_numel = max([ max([max(tensor.numel(), tensor.ds_numel) for tensor in fp16_partitioned_group]) for fp16_partitioned_group in self.fp16_partitioned_groups if len (fp16_partitioned_group) > 0 ])
- 模型加载说明:
- Python安装: 自行下载Python3.10版本的Miniconda ;
相关学习资源:
类别
简介
链接
PEFT工具
PEFT的官方介绍
PEFT工具
PEFT的简单使用
LLM-Tuning
LLM原理及实战经验分享
LLM-Tuning
ChatGLM-6B在真实任务上的应用
LLM-Tuning
ChatGLM-6B/ChatGLM2-6B结合QLoRA实现LLM-Tuning
LLM-Tuning
关于LLM微调的一些知识点
LLM-Tuning
作者对使用的ChatGLM+LoRA方案进行了代码解析
LLM-Tuning
微调工具transformers.Trainer的参数解析
LLM-基础
作者针对LLM原理进行了知识总结
LLM-基础
介绍了LLM多种性能优化方案的原理
LLM-Pretrain
介绍千亿参数开源大模型BLOOM背后的技术
系统知识
对算法基础 算法应用进行全面总结
5.3 大模型Fine-Tuning之分布式训练
按照并行方式,分布式训练一般分为数据并行和模型并行两种,当然也有数据并行和模型并行的混合模式。
- 模型并行: 分布式系统中的不同GPU负责网络模型的不同部分。例如,神经网络模型的不同网络层被分配到不同的GPU(称作pipeline并行/流水线并行),或者同一层内部的不同参数被分配到不同GPU(称作tensor并行/张量并行);
- 数据并行: 不同的GPU有同一个模型的多个副本,每个GPU分配到不同的数据,然后将所有GPU的计算结果按照某种方式合并。
以PyTorch框架为例,介绍几种分布式训练框架。
- DataParallel(DP):
简介: 单机多卡的分布式训练工具;数据并行模式。
原理: 网络在前向传播的时候会将model从主卡(默认是逻辑0卡)复制一份到所有的device上,input_data会在batch这个维度被分组后加载到不同的device上计算。在反向传播时,每个卡上的梯度会汇总到主卡上,求得梯度的均值后,再用反向传播更新单个GPU上的模型参数,最后将更新后的模型参数复制到剩余指定的GPU中进行下一轮的前向传播,以此来实现并行。
参数简介:
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)- module: 是要放到多卡训练的模型;
- device_ids: 数据类型是一个列表, 表示可用的gpu卡号;
- output_devices: 数据类型也是列表,表示模型输出结果存放的卡号(如果不指定的话,默认放在0卡,即device_ids首位,这也是为什么多gpu训练并不是负载均衡的,一般0卡会占用的多,这里还涉及到一个小知识点: 如果代码开始设定
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3",那么0卡(逻辑卡号)指的是2卡(物理卡号)。
模型参数更新方式:
- DataLoader把数据通过多个worker读到主进程的内存中;
- 通过tensor的split语义,将一个batch的数据切分成多个更小的batch,然后分别送往不同的cuda设备;
- 在不同的cuda设备上完成前向计算,网络的输出被gather到主cuda设备上(初始化时使用的设备),loss而后在这里被计算出来;
- loss然后被scatter到每个cuda设备上,每个cuda设备通过BP计算得到梯度;
- 然后每个cuda设备上的梯度被reduce到主cuda设备上,然后模型权重在主cuda设备上获得更新;
- 在下一次迭代之前,主cuda设备将模型参数broadcast到其它cuda设备上,完成权重参数值的同步。
术语介绍:
- broadcast: 是主进程将相同的数据分发给组里的每一个其它进程;
- scatter: 是主进程将数据的每一小部分给组里的其它进程;
- gather: 是将其它进程的数据收集过来;
- reduce: 是将其它进程的数据收集过来并应用某种操作(比如SUM);
- 补充: 在gather和reduce概念前面还可以加上all,如all_gather,all_reduce,那就是多对多的关系了。

使用示例: 参考一文搞定分布式训练: dataparallel distributed deepspeed accelerate transformers horovod
- DistributedDataParallel(DDP):
简介: 既可单机多卡又可多机多卡的分布式训练工具;数据并行模式。
原理: DDP在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由rank=0的进程,将其broadcast到所有进程后,各进程用该梯度来独立的更新参数,而DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个optimizer,对各个GPU上梯度进行求平均,在主卡进行参数更新,之后再将模型参数broadcast到其他GPU,相较于DP,DDP传输的数据量更少,因此速度更快,效率更高。
参数简介:
torch.nn.parallel.DistributedDataParallel(module, device_ids=None, output_device=None, dim=0, broadcast_buffers=True, process_group=None, bucket_cap_mb=25, find_unused_parameters=False, check_reduction=False)- module: 是要放到多卡训练的模型;
- device_ids: 是一个列表, 表示可用的gpu卡号;
- output_devices: 也是列表,表示模型输出结果存放的卡号(如果不指定的话,默认放在0卡,这也是为什么多gpu训练并不是负载均衡的,一般0卡会占用的多,这里还涉及到一个小知识点: 如果程序开始加
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3",那么0卡(逻辑卡号)指的是2卡(物理卡号)); - dim: 指按哪个维度进行数据的划分,默认是输入数据的第一个维度,即按batchsize划分(设数据数据的格式是B, C, H, W)。
模型参数更新方式:
- process group(进程组)中的训练进程都起来后,rank为0的进程会将网络初始化参数broadcast到其它每个进程中,确保每个进程中的网络都是一样的初始化的值(默认行为,你也可以通过参数禁止);
- 每个进程各自读取各自的训练数据,DistributedSampler确保了进程两两之间读到的是不一样的数据;
- 前向和loss的计算如今都是在每个进程上(也就是每个cuda设备上)独立计算完成的;网络的输出不再需要gather到master进程上了,这和DP显著不一样;
- 反向阶段,梯度信息通过all-reduce的MPI(Message Passing Interface,消息传递接口)原语,将每个进程中计算到的梯度reduce到每个进程;也就是backward调用结束后,每个进程中的param.grad都是一样的值;注意,为了提高all-reduce的效率,梯度信息被划分成了多个buckets;
- 更新模型参数阶段,因为刚开始模型的参数是一样的,而梯度又是all-reduce的,这样更新完模型参数后,每个进程/设备上的权重参数也是一样的。因此,就无需DP那样每次迭代后需要同步一次网络参数,这个阶段的broadcast操作就不存在了。注意,Network中的Buffers (比如BatchNorm数据) 需要在每次迭代中从rank为0的进程broadcast到进程组的其它进程上。
基本概念: 假设我们有3台机子(节点),每台机子有4块GPU。我们希望达到12卡并行的效果。
- 进程: 程序运行起来就是进程。在DDP中,大家往往让一个进程控制一个GPU;反过来说,每个GPU由一个进程控制。因此12卡并行就需要同步运行的12个进程。因此后文中,只要提到进程,指的就是某台机子上的某个GPU在跑的程序;
- 进程组: 一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到group来管理,默认情况下只有一个group;
- world size: 进程组中进程个数。也叫全局并行数。就是指总共想要用的GPU的个数。这里我们的world size就是12;
- rank: 当前进程序号。范围覆盖整个进程组: 0 ~ world size-1,我们有12个GPU,各自跑1个进程,各自的进程号为0-11。进程号为0的进程叫做master,身份比较特别,需要留意;
- local rank: 每台机子上进程的序号,被各个机子用来区分跑在自己身上的进程。范围是0 ~ 某机子进程数-1。我们每台机子有4个GPU,因此三台机子上的local rank都是从0 ~ 3。在单机多卡的情况下,local rank与rank是相同的。

使用示例: 分布式训练框架介绍
DP vs DDP:
- DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DP是通过单进程控制多线程来实现的。还有一点,DDP也不存在前面DP提到的负载不均衡问题;
- 参数更新的方式不同。DDP在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由rank=0的进程,将其broadcast到所有进程后,各进程用该梯度来独立的更新参数,而DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个optimizer,对各个GPU上梯度进行求平均,在主卡进行参数更新,之后再将模型参数broadcast到其他GPU,相较于DP,DDP传输的数据量更少,因此速度更快,效率更高;
- DDP支持all-reduce(指汇总不同GPU计算所得的梯度,并同步计算结果),broadcast,send和receive等等。通过MPI GLOO实现CPU通信,通过NCCL实现GPU通信,缓解了进程间通信开销大的问题。
- 自动混合精度训练(AMP): 自动混合精度训练(automatic mixed-precision training)并不是一种分布式训练框架,通常它与其他分布式训练框架相结合,能进一步提升训练速度。下面我们简单介绍下AMP的原理,然后与DDP结合,给出AMP的使用范例。具体参考论文MIXED PRECISION TRAINING。
简介: 默认情况下,大多数深度学习框架都采用32位浮点算法进行训练。2017年,NVIDIA研究了一种用于混合精度训练的方法,该方法在训练网络时将单精度(FP32,以32bits表示数字,即4bytes)与半精度(FP16,以16bits表示数字,即2bytes)结合在一起,并使用相同的超参数实现了与FP32几乎相同的效果。以PyTorch为例,可通过如下命令查看模型参数精度:
1 2
for name, param in model.named_parameters(): print(name, param.dtype)关键词: AMP(自动混合精度)的关键词有两个: 自动,混合精度。
- 自动: Tensor的dtype类型会自动变化,框架按需自动调整tensor的dtype,当然有些地方还需手动干预;
- 混合精度: 采用不止一种精度的Tensor,torch.FloatTensor和torch.HalfTensor。
适用硬件: Tensor Core是一种矩阵乘累加的计算单元,每个tensor core时针执行64个浮点混合精度操作(FP16矩阵相乘和FP32累加)。英伟达宣称使用Tensor Core进行矩阵运算可以轻易的提速,同时降低一半的显存访问和存储。因此,在PyTorch中,当提到自动混合精度训练,指的就是在NVIDIA支持Tensor Core的CUDA设备上使用。
原理: 前面已介绍,AMP其实就是Float32与Float16的混合,那为什么不单独使用Float32或Float16,而是两种类型混合呢?原因是: 在某些情况下Float32有优势,而在另外一些情况下Float16有优势。而相比于之前的默认的torch.FloatTensor,torch.HalfTensor的劣势不可忽视。这里先介绍下FP16优劣势。 torch.HalfTensor的优势就是存储小 计算快 更好的利用CUDA设备的Tensor Core。因此训练的时候可以减少显存的占用(可以增加batchsize了),同时训练速度更快。
- 减少显存占用: 现在模型越来越大,当你使用Bert这一类的预训练模型时,往往模型及模型计算就占去显存的大半,当想要使用更大的batchsize的时候会显得捉襟见肘。由于FP16的内存占用只有FP32的一半,自然地就可以帮助训练过程节省一半的显存空间,可以增加batchsize了;
- 加快训练和推断的计算: 与普通的空间与时间Trade-off的加速方法不同,FP16除了能节约内存,还能同时节省模型的训练时间。在大部分的测试中,基于FP16的加速方法能够给模型训练能带来多一倍的加速体验;
- 张量核心的普及(NVIDIA Tensor Core): 低精度计算是未来深度学习的一个重要趋势。
torch.HalfTensor的劣势就是: 溢出错误,数值范围小(更容易Overflow / Underflow);舍入误差(Rounding Error),导致一些微小的梯度信息达不到16bit精度的最低分辨率,从而丢失。
- 溢出错误: 由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出(Overflow)和下溢出(Underflow),溢出之后就会出现”NaN”的问题。在深度学习中,由于激活函数的梯度往往要比权重梯度小,更易出现下溢出的情况。在训练后期,例如激活函数的梯度会非常小, 甚至在梯度乘以学习率后,值会更加小;
- 舍入误差: 指的是当梯度过小时,小于当前区间内的最小间隔时,该次梯度更新可能会失败。具体的细节如下图所示,由于更新的梯度值超出了FP16能够表示的最小值的范围,因此该数值将会被舍弃,这个权重将不进行更新。

综上可知,torch.HalfTensor存在一定的劣势。因此需要采取适当的方法,一方面可以利用torch.HalfTensor的优势,另一方面需要避免torch.HalfTensor的劣势。AMP即是最终的解决方案。
混合精度训练: 在某些模型中,FP16矩阵乘法的过程中,需要利用FP32来进行矩阵乘法中间的累加(accumulated),然后再将FP32的值转化为FP16进行存储。 换句不太严谨的话来说,也就是在内存中用FP16做储存和乘法从而加速计算,而用FP32做累加避免舍入误差。混合精度训练的策略有效地缓解了舍入误差的问题。
 在这里也就引出了,为什么网上大家都说,只有Nvidia Volta结构的拥有Tensor Core的CPU(例如V100),才能利用FP16混合精度来进行加速。 那是因为Tensor Core能够保证FP16的矩阵相乘,利用FP16 or FP32来进行累加。在累加阶段能够使用FP32大幅减少混合精度训练的精度损失。而其他的GPU只能支持FP16的multiply-add operation。这里直接贴出原文句子:
在这里也就引出了,为什么网上大家都说,只有Nvidia Volta结构的拥有Tensor Core的CPU(例如V100),才能利用FP16混合精度来进行加速。 那是因为Tensor Core能够保证FP16的矩阵相乘,利用FP16 or FP32来进行累加。在累加阶段能够使用FP32大幅减少混合精度训练的精度损失。而其他的GPU只能支持FP16的multiply-add operation。这里直接贴出原文句子:Whereas previous GPUs supported only FP16 multiply-add operation, NVIDIA Volta GPUs introduce Tensor Cores that multiply FP16 input matrices andaccumulate products into either FP16 or FP32 outputs
FP32权重备份: 这种方法主要是用于解决舍入误差的问题。其主要思路,可以概括为: weights,activations,gradients等数据在训练中都利用FP16来存储,同时拷贝一份FP32的weights,用于更新。如下图:
 可以看到,其他所有值(weights,activations, gradients)均使用FP16来存储,而唯独权重weights需要用FP32的格式额外备份一次。 这主要是因为,在更新权重的时候,往往公式: 权重 = 旧权重 + lr \ 梯度,而在深度模型中,lr \ 梯度这个值往往是非常小的,如果利用FP16来进行相加的话, 则很可能会出现上面所说的『舍入误差』的这个问题,导致更新无效。因此上图中,通过将weights拷贝成FP32格式,并且确保整个更新(update)过程是在FP32格式下进行的,如下所示: w e i g h t 32 = w e i g h t 32 + η ⋅ g r a d i e n t 32 weight_{32}=weight_{32}+\eta \cdot gradient_{32} weight32=weight32+η⋅gradient32 看到这里,可能有人提出这种FP32拷贝weights的方式,那岂不是使得内存占用反而更高了呢?是的,FP32额外拷贝一份weights的确新增加了训练时候存储的占用。 但是实际上,在训练过程中,内存中占据大部分的基本都是activations的值,如下图所示。特别是在batchsize很大的情况下, activations更是特别占据空间。 保存activiations主要是为了在backward的时候进行计算。因此,只要activations的值基本都是使用FP16来进行存储的话,则最终模型与FP32相比起来, 内存占用也基本能够减半。
可以看到,其他所有值(weights,activations, gradients)均使用FP16来存储,而唯独权重weights需要用FP32的格式额外备份一次。 这主要是因为,在更新权重的时候,往往公式: 权重 = 旧权重 + lr \ 梯度,而在深度模型中,lr \ 梯度这个值往往是非常小的,如果利用FP16来进行相加的话, 则很可能会出现上面所说的『舍入误差』的这个问题,导致更新无效。因此上图中,通过将weights拷贝成FP32格式,并且确保整个更新(update)过程是在FP32格式下进行的,如下所示: w e i g h t 32 = w e i g h t 32 + η ⋅ g r a d i e n t 32 weight_{32}=weight_{32}+\eta \cdot gradient_{32} weight32=weight32+η⋅gradient32 看到这里,可能有人提出这种FP32拷贝weights的方式,那岂不是使得内存占用反而更高了呢?是的,FP32额外拷贝一份weights的确新增加了训练时候存储的占用。 但是实际上,在训练过程中,内存中占据大部分的基本都是activations的值,如下图所示。特别是在batchsize很大的情况下, activations更是特别占据空间。 保存activiations主要是为了在backward的时候进行计算。因此,只要activations的值基本都是使用FP16来进行存储的话,则最终模型与FP32相比起来, 内存占用也基本能够减半。 
损失放大(Loss Scale): 即使采用了混合精度训练,还是存在无法收敛的情况,原因是激活梯度的值太小,造成了下溢出(Underflow)。Loss Scale主要是为了解决FP16 underflow的问题。刚才提到,训练到了后期,梯度(特别是激活函数平滑段的梯度)会特别小,如果用FP16来表示,则这些梯度都会变成0,因此导致FP16表示容易产生underflow现象。 为了解决梯度过小的问题,论文中对计算出来的loss值进行scale,由于链式法则的存在,loss上的scale会作用在梯度上。这样比起对每个梯度进行scale更加划算。 scaled过后的梯度,就会平移到FP16有效的展示范围内。 这样,scaled-gradient就可以一直使用FP16进行存储了。只有在进行更新的时候,才会将scaled-gradient转化为FP32,同时将scale抹去。论文指出, scale并非对于所有网络而言都是必须的。论文给出scale的取值在8 - 32k之间皆可。 Pytorch可以通过使用torch.cuda.amp.GradScaler,通过放大loss的值来防止梯度的underflow(只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去) 综上,损失放大的思路是:
- 反向传播前,将损失变化手动增大 2 k 2^{k} 2k倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出;
- 反向传播后,将权重梯度缩小 2 k 2^{k} 2k倍,恢复正常值。
使用示例: 分布式训练框架介绍
- Accelerate: DP简单且容易调试,DDP快但是难debug,且代码改动稍大,例如要开启后端通讯,数据sampler的方式也要改。有没有工具不仅代码改动量少,方便debug,而且训练起来快呢?其中一个答案就是Accelerate库,Accelerate库是大名鼎鼎的huggingface公司在2021年初推出的PyTorch分布式训练工具库,官方链接是 Accelerate。另外有篇比较好的说明文档是Accelerate。
- 简介: Accelerate是huggingface开源的一个方便将PyTorch模型迁移到multi-GPUs/TPU/FP16模式下训练的小巧工具。和标准的PyTorch方法相比,使用accelerate进行multi-GPUs/TPU/FP16模型训练变得非常简单(只需要在标准的PyTorch训练代码中改动几行代码就可以适应multi-GPUs/TPU/FP16等不同的训练环境),而且速度与原生PyTorch相比,非常之快。
- 使用示例: 分布式训练框架介绍
- 使用技巧: HuggingFace——Accelerate的使用
accelerate config: 通过在终端中回答一系列问题生成配置文件;
1
accelerate config --config_file ./accelerate_config.yaml
accelerate env: 验证配置文件的合法性;
1
accelerate env --config_file ./accelerate_config.yaml
accelerate launch: 运行自己的python文件;
1
accelerate launch --config_file ./conf/accelerate_config.yaml train_accelerate.py
accelerate test: 运行accelerate默认的神经网络模型来测试环境是否可以。
1
accelerate test --config_file ./accelerate_config.yaml
- 使用技巧: HuggingFace——Accelerate的使用
- Deepspeed: Deepspeed是Microsoft提供的分布式训练工具,适用于更大规模模型的训练,官方链接是DeepSpeed。这里我们详细介绍下Deepspeed的分布式原理,具体的使用示例可参考前文的PEFT实践部分。
简介: DeepSpeed是一个由微软开发的开源深度学习优化库,旨在提高大规模模型训练的效率和可扩展性。DeepSpeed的核心技术是ZeRO(Zero Redundancy Optimizer,零冗余优化),通过ZeRO技术实现了数据并行。另外,DeepSpeed也支持模型并行(借用英伟达的Megatron-LM来为基于Transformer的语言模型提供张量并行功能,张量并行参考Megatron-LM;通过梯度累积来实现流水线并行,流水线并行参考Pipeline Parallelism)。
原理: 关于模型并行部分具体原理,大家自行查阅相关文档,这里不予过多介绍。接下来,我们着重介绍下DeepSpeed的核心技术ZeRO: ZeRO-1 ZeRO-2 ZeRO-3 ZeRO-Offload与ZeRO-Infinity,具体参考《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》 《ZeRO-Offload: Democratizing Billion-Scale Model Training》 《ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning》 DeepSpeed ZeRO。
存储分类: 首先,大模型训练的过程中,GPU需要存储的内容包括两大块: Model States和Residual States。
- Model State: 指和模型本身息息相关的,必须存储的内容,具体包括:
- optimizer states: Adam优化算法中的momentum和variance;
- gradients: 模型梯度G;
- parameters: 模型参数W。
- Residual States: 指并非模型必须的,但在训练过程中会额外产生的内容,具体包括:
- activations: 激活值。在backward过程中使用链式法则计算梯度时会用到。有了它计算梯度会更快,但它不是必须存储的,因为可以通过重新做forward来计算算它。实际上,activations就是模型在训练过程中产生的中间值,举个例子: x 2 = w 1 ∗ x , y = w 2 ∗ x 2 x_{2}=w_{1} \ x,y=w_{2} \ x_{2} x2=w1∗x,y=w2∗x2,假设上面的参数( w 1 w_{1} w1, w 2 w_{2} w2)和输入 $x$ 都是标量,在反向传播阶段要计算 $y$ 对 w 2 w_{2} w2的梯度,很明显是 x 2 x_{2} x2,这个 x 2 x_{2} x2就属于activations,也就是在前向阶段需要保存的一个中间结果。当然我们也可以不保存,当反向阶段需要用到 x 2 x_{2} x2时再重新通过forward过程临时计算;
- temporary buffers: 临时存储。例如把梯度发送到某块GPU上做加总聚合时产生的存储。
- unusable fragment memory: 碎片化的存储空间。虽然总存储空间是够的,但是如果取不到连续的存储空间,相关的请求也会被fail掉。对这类空间浪费可以通过内存整理来解决。
- Model State: 指和模型本身息息相关的,必须存储的内容,具体包括:
存储大小: 了解了存储分类,接下来了解下每种存储占用的内存大小。首先我们回忆下混合精度训练的过程,大致如下图所示:

- 混合精度训练: 简单来说,混合精度训练的流程有如下几步。
- 存储一份FP32的parameter,momentum和variance(统称model states);
- 在forward开始之前,额外开辟一块存储空间,将FP32的parameter减半到FP16 parameter;
- 正常做forward和backward,在此之间产生的activations和gradients,都用FP16进行存储;
- 将FP16的gradients转换为FP32的gradients,用FP32的gradients去更新FP32下的model states。 当模型收敛后,FP32的parameter就是最终的参数输出。
现在,我们可以来计算模型在训练时需要的存储大小了,假设模型的参数W大小是 $\Phi$ (根据参数量预估显存占用的方法参见参数量估计与显存估计,这里简单提下,比如6B的模型,使用FP16方式载入显存,所需显存大小: 6B ∗ \ast ∗ 2 = 12G),则训练时对应的存储如下:
 因为采用了Adam优化,所以才会出现momentum和variance,当然你也可以选择别的优化办法,这里为了通用,模型必存的数据大小为 K Φ K\Phi KΦ,因此总的存储大小为 ( 2 + 2 + K ) Φ (2+2+K)\Phi (2+2+K)Φ。另外,这里暂不将activations纳入统计范围,原因是:
因为采用了Adam优化,所以才会出现momentum和variance,当然你也可以选择别的优化办法,这里为了通用,模型必存的数据大小为 K Φ K\Phi KΦ,因此总的存储大小为 ( 2 + 2 + K ) Φ (2+2+K)\Phi (2+2+K)Φ。另外,这里暂不将activations纳入统计范围,原因是:- activations不仅与模型参数相关,还与batchsize相关;
- activations的存储不是必须的。前文已经提到,存储activations只是为了在用链式法则做backward的过程中,计算梯度更快一些。但你永远可以通过只保留最初的输入X,重新做forward来得到每一层的activations(虽然实际中并不会这么极端);
- 因为activations的这种灵活性,纳入它后不方便衡量系统性能随模型增大的真实变动情况。因此在这里不考虑它。
- 混合精度训练: 简单来说,混合精度训练的流程有如下几步。
ZeRO-DP: 了解了存储种类以及它们所占的存储大小之后,接下来我们介绍下Deepspeed是如何优化存储的。这里提前透露下,ZeRO三阶段: ZeRO-1 ZeRO-2 ZeRO-3的实质是数据并行,因此我们也称之为ZeRO-DP,后面会介绍具体细节。首先我们应该清楚,在整个训练中,有很多states并不会每时每刻都用到,举例来说;
- Adam优化下的optimizer states只在最终做update时才用到;
- 数据并行中,gradients只在最后做all-reduce和update时才用到;
- 参数W只在做forward和backward的那一刻才用到。
诸如此类,所以,ZeRO-DP想了一个简单粗暴的办法: 如果数据算完即废,等需要的时候,我再想办法从个什么地方拿回来,那不就省了一笔存储空间吗?沿着这个思路,我们逐一来看ZeRO是如何递进做存储优化的。
- ZeRO-1: 即 P o s P_{os} Pos,优化状态分割。首先,从optimizer states开始优化。将optimizer states分成若干份,每块GPU上各自维护一份。这样就减少了相当一部分的显存开销。如下图:
 整体数据并行的流程如下:
整体数据并行的流程如下:- 每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各吃一份,做完一轮forward和backward后,各得一份梯度;
- 对梯度做一次all-reduce,得到完整的梯度G,产生单卡通讯量 $2\Phi$ 。对于all-reduce(reduce-scatter + all-gather)的通讯量,reduce-scatter操作发送和接收的通讯量为 $\Phi$ ,all-gather操作发送和接收的通讯量也为 $\Phi$ ,因此all-reduce的通讯录为 $2\Phi$ 。注意,此处我们不去探寻单次发送和接收的通讯量为什么是 $\Phi$ ,感兴趣的同学可自行探索手把手推导Ring All-reduce的数学性质;
- 得到完整梯度G,就可以对W做更新。我们知道W的更新由optimizer states和梯度共同决定。由于每块GPU上只保管部分optimizer states,因此只能将相应的W(蓝色部分)进行更新。上述步骤可以用下图表示:

- 此时,每块GPU上都有部分W没有完成更新(图中白色部分)。所以我们需要对W做一次all-gather,从别的GPU上把更新好的部分W取回来。产生单卡通讯量 $\Phi$ 。
做完 P o s P_{os} Pos后,设GPU个数为 N d N_{d} Nd,显存和通讯量的情况如下:
并行化技术
显存
显存(GB), Φ = 7.5 B \Phi=7.5B Φ=7.5B, N d = 64 N_{d}=64 Nd=64, K = 12 K=12 K=12
单卡通讯量
朴素DP
(2+2+ K K K) $\Phi$
120GB
2 $\Phi$
P o s P_{os} Pos
(2+2+ K N d \frac{K}{N_{d}} NdK) $\Phi$
31.4GB
3 $\Phi$
如图所示, P o s P_{os} Pos在增加1.5倍单卡通讯开销的基础上,将单卡存储降低了4倍。这里需要说明下,有其他相关技术博客,给出的 P o s P_{os} Pos单卡通讯量是2 $\Phi$ 。其实虽然按照论文中定义,计算的通讯量是3 $\Phi$ ,但在官方代码的具体实现中,通讯量应该是2 $\Phi$ ,这是因为在第二个步骤中,由于每块GPU上只保管部分optimizer states,因此根本不需要对梯度做all-gather操作。因为即使每块GPU上有完整的梯度,在实际计算中有部分梯度也用不上。这样 P o s P_{os} Pos单卡通讯量就是2 $\Phi$ 了。
- ZeRO-2: 即 P o s + P g P_{os}+P_{g} Pos+Pg,优化状态与梯度分割。现在,更近一步,我们把梯度也拆开,每个GPU格子维护一块梯度。
 此时,数据并行的整体流程如下:
此时,数据并行的整体流程如下:- 每块GPU上存一份完整的参数W。将一个batch的数据分成3份,每块GPU各吃一份,做完一轮foward和backward后,算得一份完整的梯度(下图中绿色+白色);
- 对梯度做一次reduce-scatter,保证每个GPU上所维持的那块梯度是聚合更新后的梯度。例如对GPU1,它负责维护G1,因此其他的GPU只需要把G1对应位置的梯度发给GPU1做加总就可。汇总完毕后,白色块对GPU无用,可以从显存中移除。单卡通讯量为 $\Phi$ 。如下图所示。

- 每块GPU用自己对应的O和G去更新相应的W。更新完毕后,每块GPU维持了一块更新完毕的W。同理,对W做一次all-gather,将别的GPU算好的W同步到自己这来。单卡通讯量 $\Phi$ 。
做完 P o s + P g P_{os}+P_{g} Pos+Pg后,设GPU个数为 N d N_{d} Nd,显存和通讯量的情况如下:
并行化技术
显存
显存(GB), Φ = 7.5 B \Phi=7.5B Φ=7.5B, N d = 64 N_{d}=64 Nd=64, K = 12 K=12 K=12
单卡通讯量
朴素DP
(2+2+ K K K) $\Phi$
120GB
2 $\Phi$
P o s P_{os} Pos
(2+2+ K N d \frac{K}{N_{d}} NdK) $\Phi$
31.4GB
3 $\Phi$
P o s + P g P_{os}+P_{g} Pos+Pg
(2+ 2 + K N d \frac{2+K}{N_{d}} Nd2+K) $\Phi$
16.6GB
2 $\Phi$
如图所示,和朴素DP相比,存储降了8倍,单卡通讯量持平。
- ZeRO-3: 即 P o s + P g + P p P_{os}+P_{g}+P_{p} Pos+Pg+Pp,优化状态 梯度与参数分割。现在,我们把参数也切开。每块GPU置维持对应的optimizer states,gradients和parameters(即W)。
 数据并行的流程如下:
数据并行的流程如下:- 每块GPU上只保存部分参数W。将一个batch的数据分成3份,每块GPU各吃一份;
- 做forward时,对W做一次all-gather,取回分布在别的GPU上的W,得到一份完整的W,单卡通讯量 $\Phi$ 。forward做完,立刻把不是自己维护的W抛弃;
- 做backward时,对W做一次all-gather,取回完整的W,单卡通讯量 $\Phi$ 。backward做完,立刻把不是自己维护的W抛弃;
- 做完backward,算得一份完整的梯度G,对G做一次reduce-scatter,从别的GPU上聚合自己维护的那部分梯度,单卡通讯量 $\Phi$ 。聚合操作结束后,立刻把不是自己维护的G抛弃。
- 用自己维护的O和G,更新W。由于只维护部分W,因此无需再对W做任何all-reduce操作。
做完 P o s + P g + P p P_{os}+P_{g}+P_{p} Pos+Pg+Pp后,设GPU个数为 N d N_{d} Nd,显存和通讯量的情况如下:
并行化技术
显存
显存(GB), Φ = 7.5 B \Phi=7.5B Φ=7.5B, N d = 64 N_{d}=64 Nd=64, K = 12 K=12 K=12
单卡通讯量
朴素DP
(2+2+ K K K) $\Phi$
120GB
2 $\Phi$
P o s P_{os} Pos
(2+2+ K N d \frac{K}{N_{d}} NdK) $\Phi$
31.4GB
3 $\Phi$
P o s + P g P_{os}+P_{g} Pos+Pg
(2+ 2 + K N d \frac{2+K}{N_{d}} Nd2+K) $\Phi$
16.6GB
2 $\Phi$
P o s + P g + P p P_{os}+P_{g}+P_{p} Pos+Pg+Pp
( 2 + 2 + K N d \frac{2+2+K}{N_{d}} Nd2+2+K) $\Phi$
1.9GB
3 $\Phi$
如图所示,和朴素DP相比,用1.5倍的通讯开销,换回近120倍的显存。最终,我们可以看下论文中的总体对比图:

ZeRO-DP VS 模型并行: 通过上述的介绍,大家可能会有疑问,既然ZeRO都把参数W给切了,那它应该是个模型并行,为什么却归到数据并行?其实ZeRO是模型并行的形式,数据并行的实质。
- 模型并行,是指在forward和backward的过程中,我只需要用自己维护的那块W来计算就行。即同样的输入X,每块GPU上各算模型的一部分,最后通过某些方式聚合结果;
- 但对ZeRO来说,它做forward和backward的时候,是需要把各GPU上维护的W聚合起来的,即本质上还是用完整的W进行计算。它是不同的输入X,完整的参数W,最终再做聚合。
ZeRO-Offload: 简单介绍一下ZeRO-Offload。它的核心思想是: 显存不够,内存来凑。如果把要存储的大头卸载(offload)到CPU上,而把计算部分放到GPU上,这样比起跨机,既能降低显存使用,也能减少一些通讯压力。ZeRO-Offload的做法是:
- forward和backward计算量高,因此和它们相关的部分,例如参数W(FP16) activations,就全放入GPU;
- update的部分计算量低,因此和它相关的部分,全部放入CPU中。例如W(FP32) optimizer states(FP32)和gradients(FP32)等。
具体切分如下图:

Accelerate vs Deepspeed:
- Accelerate是PyTorch官方提供的分布式训练工具,而Deepspeed是由Microsoft提供的分布式训练工具;
- 最主要的区别在于支持的模型规模不同,Deepspeed支持更大规模的模型;
- Deepspeed还提供了更多的优化策略和工具,例如ZeRO和Offload等;
- Accelerate更加稳定和易于使用,适合中小规模的训练任务;
- 目前Accelerate已经集成了Deepspeed及Megatron分布式技术,具体可详见前文的PEFT实践部分。
5.4 大模型知识问答
- nB大小的模型,训练和推理时,显存占用情况?
- 推理时显存的下限是2nGB ,至少要把模型加载完全;训练时,如果用Adam优化器,参考前文的2+2+12的公式,训练时显存下限是16nGB,需要把模型参数 梯度和优化器状态加载进来。
- 如果有N张显存足够大的显卡,怎么加速训练?
- 数据并行(DP),充分利用多张显卡的算力。
- 如果显卡的显存不够装下一个完整的模型呢?
- 最直观想法,需要分层加载,把不同的层加载到不同的GPU上(accelerate的device_map),也就是常见的PP,流水线并行。
- 但PP推理起来,是一个串行的过程,1个GPU计算,其他GPU空闲,有没有其他方式?
- 横向切分,流水线并行(PP),也就是分层加载到不同的显卡上;
- 纵向切分,张量并行(TP),也称作模型并行(MP)。
- 3种并行方式可以叠加吗?
- 是可以的,DP+PP+TP,这就是3D并行。如果真有1个超大模型需要预训练,3D并行那是必不可少的,参考BLOOM模型的训练,DP+PP用DeepSpeed,TP用Megatron-LM。
- 最主流的开源大模型?
- ChatGLM-6B,prefix LM;
- LLaMA-7B,causal LM。
- prefix LM和causal LM的区别?
- Attention Mask不同,前者的prefix部分的token互相能看到,后者严格遵守只有后面的token才能看到前面的token的规则。
- 哪种架构是主流?
- GPT系列就是Causal LM,目前除了T5和GLM,其他大模型基本上都是Causal LM。
- 如何给LLM注入领域知识?
- 第一种办法,检索+LLM,先用问题在领域数据库里检索到候选答案,再用LLM对答案进行加工;
- 第二种方法,把领域知识构建成问答数据集,用SFT让LLM学习这部分知识。
改進LLM
怎麼使用、使用哪個LLM來部屬產品? [^如何改進LLM]
- 用GPT4還是GTP3.5?Llama聽說不錯?
- 用API來服務還是要自己訓練、部屬模型?
- 需要Finetune嗎?
- 要做prompt engineering嗎?怎麼做?
- 要做retrival嗎?,RAG(Retrieval Augmented Generation)架構對我的任務有幫助嗎?
- 主流模型就有十多個、Training有數十種的方法,到底該怎麼辦?
- ……
FSDL的課程:
- 李宏毅老師
- Deep Learning.ai 的Andrew Ng老師
- UCBerkeley的 Full Stack Deep Learning
要選擇各種ML DL的技巧之前,應該先分清楚我們現在遇到的問題,並想清楚哪些方法可以解決這個問題
- 如果Training Error比Testing Error低一截,那我們遇到的就是
Overfitting,各種類型的regularization或是縮小model都可以派上用場。 - 但是如果我們遇到的是Training Error跟Human的水平有一截差距,那變成我們是
Underfitting,反而是要加大model甚至是重新定義問題,找到一個更好fit的問題。
從能找到的最強LLM(GPT4)開始
- 不論如何,請從你手邊能找到的最強LLM開始產品
- 對於任何一個AI產品而言,同時要面對兩個不確定性:1. 需求的不確定,2. 技術的不確定 。
- 技術的不確定指的是: 我們沒辦法在訓練模型之前知道我們最後可以得到的Performance 。因此很多AI產品投入了資源收集資料及訓練模型,最後卻發現模型遠沒有達到可接受的標準。
在LLM時期其實像是GPT4或是Bard這種模型,反倒提供給我們一個非常強的Baseline,所以先使用能找到的最強模型來開始產品。
- 先用GPT4來做MVP ,如果可行則確認unit economics、尋找護城河跟盡量減低cost。
- 分析錯誤來源
- 如果錯誤跟factual比較有關, 藉由跑「給定相關資訊來進行預測」的實驗測試LLM到底是不具備相關知識還是Hallucination 。
- 如果錯誤跟reasoning比較有關,藉由 perplexity區分model需要language modeling finetuning還是supervised finetuning。
- 如果finetuning是可行的(有一定量資料、成本可接受),直接跑小範圍的finetune可以驗證很多事情。
如果LLM沒有達成標準
如果達成標準, 則思考更多商業上的問題
- 確認unit economics :
- 確保每一次用戶使用服務時,你不會虧錢。
- Ex:用戶訂閱你服務一個月只要120,但是他平均每個月會使用超過120元的GPT-4額度,這就會出現問題(除非你有更完備的商業規劃)。
- 找尋護城河 :
- 因為你目前是使用第三方提供的LLM,所以你技術上不具備獨創性,請從其他方面尋找護城河。
- 在達成標準的前提下盡量降低cost :
- 換小模型
- GPT cache
- 在傳統chatbot中大多有一個功能是開發者提供QA pairs,然後每次用戶問問題,就從這些QA pairs中找尋最佳的回答,而GPT cache其實就是把每次GPT的回答記起來,當成一個QA pair,新問題進來時就可以先找有沒有相似的問題,減少訪問GPT API的次數。
- 限縮LLM使用場景。
如果LLM沒有達成標準
如果沒有達成標準,則需要思考技術上的改進策略。分析LLM失敗的原因。
通常來說,LLM會失敗主流會有4種原因,兩種大的類別:
- Factual 事實相關
- Reasoning 推理相關

- (Factual相關)LLM不具備這個知識 :
- 嘗試RAG(Retrieval Augmented Generation)
- finetuning
- (Factual相關)LLM在胡言亂語(Hallucination) :
- prompt engineering (CoT, Self Critique),
- finetuning
- (Reasoning相關)LLM不適應這種類型語料 :
- finetuning: language modeling,
- 更換LLM
- (Reasoning相關)LLM無法正確推理這個問題 :
- finetuning: supervised finetuning,
- In-Context Learning
Factual相關
- 如果LLM回答問題錯誤,
- 有可能是LLM根本不具備相關知識,導致他只能隨便回答,
- 也有可能試產生了Hallucination(胡言亂語)的現象
而最好區分這兩者的方法,就是做以下實驗。
- ICL + Retrieval Augmented Generation
- 選定 k筆LLM答錯的資料
- 在prompt中加入能夠回答這題的相關資訊(也是你確定你未來可以取得的相關資訊),檢測是否有 明顯變好
- 如果有的話那就可以走 RAG(Retrieval Augmented Generation) 這條路
- 如果還是有一定比例的資料無法達成,那則加入像是 self critique 之類的prompt engineering的方法。
- 更直覺的思考方式:
- 你想要LLM完成的這個任務,會不會在網路上常常出現?
- 如果會常常出現,那高機率用Prompt engineering就可以,
- 如果是冷門資訊,甚至是網路上不會出現的資訊(機構內部資訊),那就一定要走RAG。
- Ex:
- 開發銀行的客服機器人->RAG
- 開發一個每天誇獎對話機器人,高機率只要prompr engineering,因為誇獎的用詞、知識、方法網路上出現很多次。
Reasoning相關
- 如果LLM有相關知識,但是回答的時候錯誤率依舊很高,那就要考慮是不是LLM根本 不具備需要的推理能力 。
- 而這又分為兩種:
- LLM對這種類型的文本不熟悉,
- LLM對這種類型的推理、分類問題不熟悉。
- 兩者最直接的區分方法: 讓LLM在你對應的文本算perplexity。
perplexity是用來衡量「LLM預測下一個詞的混亂程度」
- 如果perplexity高
- 代表LLM對這類型的文本領域(domain)根本不熟,可能是語言不熟悉,也有可能是內容領域不熟悉
- 這時候就一定要
language model finetuning,藉由unsupervised finetuning,加強LLM對文本領域的熟悉度。
- 如果perplexity很低,但是問題還是解決不好
- 則更需要訓練LLM處理特定的問題,因此則要
supervised finetuning,這就類似傳統finetune CNN,蒐集Label data,讓模型學會執行對應任務。
- 則更需要訓練LLM處理特定的問題,因此則要
- 如果是利用GPT4之類的API,沒辦法取得perplexity的數值
- 可以從文本中找出你認為基礎的知識語句,找個100句,每一句拋棄後半段請GPT4自行接龍,再基於結果判斷LLM到底有沒有你這個領域的經驗。
- perplexity是高是低,其實是一個非常需要經驗的事情,所以只能當作參考指標。
- 如果一個model對文本的
embedding你可以取得,那可以對embedding去train linear classifier - 如果non separable,則表示這個model無法足夠細緻的處理這類型的問題,則更需要supervised finetuning。
- 如果一個model對文本的
只要finetuning對你而言是可以承擔的事情
- 建議對任何任務都先跑100~1,000筆資料、1個epoch的supervised finetuning,和10,000個token的language modeling
- 這會更像是以前DL我們直接用訓練來觀測模型是否會有顯著改善。
LLM Evaluation
Basic:
- check for empty strings
- check for format of output, Guardrails is good at this
Advanced:
- check for relevance
- rank results
- closed deomian only
Expert:
- Model-based checks (“Are you sure?”)
.
Comments powered by Disqus.