LLMs Paper - JaCoText A Pretrained Model for Java Code-Text
JaCoText: A Pretrained Model for Java Code-Text
Pretrained transformer-based modelshave shown high performance innatural language generationtask. However, a new wave of interest has surged:automatic programming language generation.This task consists of translating natural language instructions to a programming code. effort is still needed in automatic code generation
When developing software, programmers use both
natural language (NL)andprogramming language (PL).- natural language is used to write documentation (ex: JavaDoc) to describe different classes, methods and variables.
- Documentation is usually written by experts and aims to provide a comprehensive explanation of the source code to every person who wants to use/develop the project.
the automation of
programming code generationfrom natural language has been studied using various techniques of artificial intelligence (AI): automatically generate code for simple tasks, while allowing them to tackle only the most difficult ones.After the big success of Transformers Neural Network, it has been adapted to many
Natural Language Processing (NLP) tasks(such as question answering, text translation, automatic summarization)- popular models are GPT, BERT, BART, and T5
- One of the main factors of success: trained on very large corpora.
Recently, there has been an increasing interest in programming code generation. scientific community based its research on proposing systems that are based on pretrained transformers.
CodeGPTandGPT-adaptedare based onGPT2PLBARTis based onBART,CoTexTfollowsT5.- Note that these models have been pretrained on
bimodal data(containing both PL and NL) and onunimodal data(containing only PL).
Programming language generation is more challenging than standard text generation, PLs contain stricter grammar and syntactic rules.
an example of an input sequence received by the model (in NL), the output of the model (in PL) and the target code (called gold standard or reference code).

JaCoText- model based on Transformers neural network.
- pretrained model based on Transformers
- It aims to generate java source code from natural language text.
- It leverages advantages of both natural language and code generation models.
study from the
state of the artand use them to- (1) initialize the model from powerful pretrained models,
- (2) explore additional pretraining on the java dataset,
- (3) carry out experiments combining the unimodal and bimodal data in the training
- (4) scale the input and output length during the fine-tuning of the model
- Conducted experiments on
CONCODEdataset show thatJaCoTextachieves new best results.
step
- initialize the model from pretrained weights of
CoTexT-1CC and CoTexT-2CC, instead of performing a training from scratch. - conduct an additional pretraining step using data that belongs to a specific programming language (Java)
- unlike works that based their pretraining on
CodeSearchNet(such asCodeBERTandCoTexT), we use more java data in the pretraining stage of the model Transformers neural network improves its performance significantly from increasing the amount of pretraining data.
- unlike works that based their pretraining on
- carry out experiments to measure the impact of the input and output sequences length on code generation task.
- test the unimodal data and study its impact on the model’s performance.
- crucial to evaluate the model in the pretraining stage.
- initialize the model from pretrained weights of
main findings
T5 has shown the best performance in language generation tasks.
Models initialized from previous pretrained weights achieve better performance than models trained from scratch
Models such as SciBERT and BioBERT have shown the benefits to pretrain a model using data related to a specific domain.
Increased data implies better training performance. This finding is intuitive since a large and diversified dataset helps improving the model’s representation.
The input and output sequence length used to train the model matters in the performance of the model
The objective learning used during the pretraining stage gives the model some benefits when learning the downstream tasks
the core component of
JaCoTextA. Fine-tuning
fine-tune models based on two criteria: We apply both criteria initializing the fine-tuning from
CoTexT checkpoints 2CC and 1CC, respectively.- CoTexT-1CC is pretrained on unimodal data (only code)
- CoTexT-2CC is pretrained on bimodal data (both code and natural language)
- Results of these experiments are shown in Table III
a. Sequence Length:
- After analyzing the outputs generated by previous works, we observed that some of the code sequences produced by the models were incomplete compared to the target ones.
- Consequently, we tokenized the training and validation sets with
SentencePiecemodel. - We then computed the largest sequence data, and used its length for both the inputs and the targets.
b. Number of steps: Since we increased the length of sequences in the model, we increased the number of fine-tuning steps. a way to improve the model’s performance is by increasing the number of steps in the training.
B. Additional Pretraining
some important observations that support in the work:
- (1) for some specific tasks, the way to improve the model’s performance is to
pretrain it with a dataset that belongs to a specific domain, - (2) additional pretraining can improve the performance of a model,
(3)
a low number of epochs when pretraining a model leads to higher scores in generation tasks.- models initialized with pretrained weights achieve better results than models trained from scratch.
- (1) for some specific tasks, the way to improve the model’s performance is to
Based on the previous highlighted points, we carried out additional pretraining on unimodal java data.
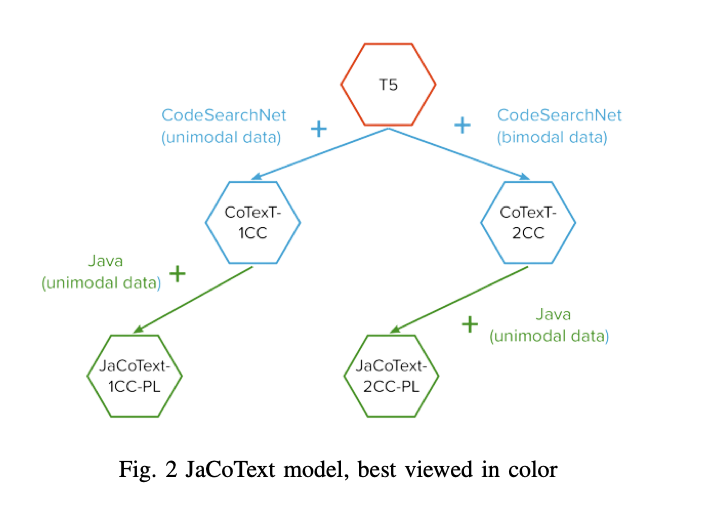
step
- initialized
JaCoText-B-1CC-PLandJaCoText-B-2CC-PLmodels from pretrained weights ofCoTexT-1CCandCoTexT-2CC, respectively. We trained the previous models on only-code sequences. follow the same procedure for both
T5baseandT5large.- The input of the encoder is a noisy Java code.
- The input of the decoder is the original Java code with one position offset.
once the model is initialized from T5 weights (previously pretrained on C4 dataset), we further pretrain it on
CodeSearchNetand the java dataset.- Later, we use the final checkpoints to initialize the fine-tuning on
CONCODEdataset.
- initialized
EXPERIMENTAL SETUP
A. Architecture
JaCoTextuses the same architecture as T5, which is based on Transformers.T5baseconsists of 12 layers in both the encoder and the decoder, with model dimension of 768 and 12 heads (approx. 220M parameters).T5largehas 24 layers in both the encoder and the decoder, with model dimension of 1024 and 16 heads (approx. 770M parameters).
B. Code Generation Dataset
To perform the experiments in Java code generation task, we used
CONCODE,CONCODE:- dataset that contains context of a real world Java programming environment.
- aims to generate Java member functions that have class member variables from documentation.
CONCODEdataset: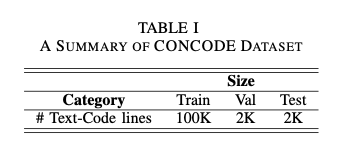
C. Additional Pretraining Dataset
For the additional pretraining, we used the Java dataset.
Originally, it consists of 812,008, 40,468, and 51,210 samples in the training, validation, and test sets, respectively.
deleted the problematic samples in the three sets (2974 in the training set, 235 in the validation set, and 161 in the test set).
use the rest of samples (900,316) from the three sets to pretrain the model.
D. Evaluation Metrics
To evaluate the models, we used the three metrics described below.
a.
BLEU:- a metric based on
n-gram precisioncomputed between the candidate and the reference(s). N-gram precisionpenalizes the model if:- (1) words appear in the candidate but not in any of the references, or
- (2) word appear more times in the candidate than in the maximum reference count.
- However, the metric fails if the candidate does not have the appropriate length. we use the
corpus-level BLEU scorein the code generation task.
- a metric based on
b.
CodeBLEU:- works via n-gram match, and it takes into account both the syntactic and semantic matches.
- The syntax match is obtained by matching between the
code candidate and code reference(s) sub-treesofabstract syntax tree (AST). - The semantic match considers the data-flow structure.
c.
Exact Match (EM):- the ratio of the number of predictions that match exactly any of the code reference(s).
E. Baselines
We compare the model with 4 best Transformer-based models.
CodeGPTandCodeGPT-adaptedare based on GPT-2 model. The difference:- CodeGPT is trained from scratch on
CodeSearchNetdataset - CodeGPT-adapted is initialized from GPT-2 pretrained weights.
- CodeGPT is trained from scratch on
PLBARTuses the same architecture thanBARTbase.PLBARTuses three noising strategies: token masking, token deletion and token infilling.CoTexTuses the same architecture than T5base. It is trained on both unimodal and bimodal data usingCodeSearchNet, Corpus, and GitHub Repositories.
RESULTS AND DISCUSSION
for the performance of T5 model on the Java generation task.
directly fine-tune on
CONCODEdataset 3 types of T5:T5base,T5large,T53B.The best parameters we used are highlighted in Table III.
Table II provides the scores of each type of T5 models directly after the fine-tuning using
CONCODEdataset.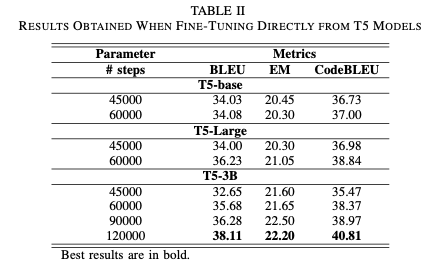
- all score improves as the number of steps increases.
- the
most sophisticated T53B model gets the best results, followed by T5large and T5base, while T53B takes more time to converge.
Table III provides results obtained when varying the number of steps and the length of input and output sequences while fine tuning
CoTexT-2CCandCoTexT-1CCcheckpoints onCONCODEdataset.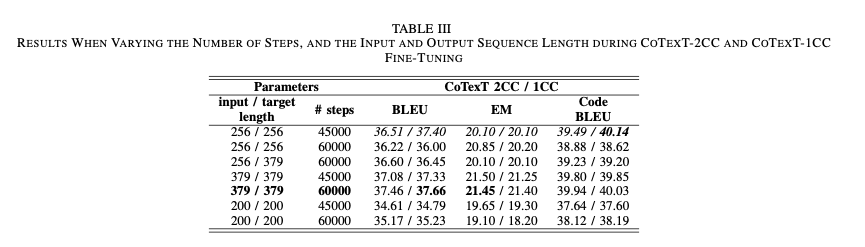
Results show that using 60000 steps provides better results than using 45000 steps in the fine-tuning
- by using the largest code sequence length, we outperform the
BLEUandEMscores obtained by (highlighted in italic). Results vary slightly, almost undetectable. - However, CoTexT-1CC performs better using BLEU and CodeBLEU, while CoTexT-2CC achieves better results using the EM metric.
Varying the number of steps and augmenting the length of both the input and target in the fine-tuning provide the first step to improve results on Java code generation task. The second step consists in using the additional pretraining from CoTexT weights following. After additional pretraining, we fine-tune the model using the best parameter values from Table III.
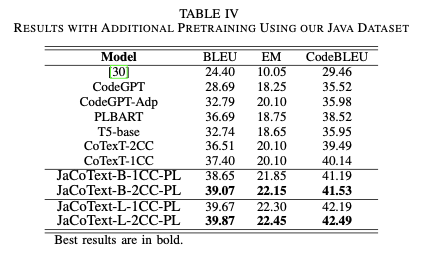
Table IV provides fine-tuning results after performing the additional pretraining using the Java dataset.
The models are
- initialized with
JaCoText-Bweights when they are trained following theT5basearchitecture - initialized with
JaCoText-Lweights when they are trained followingT5large.
- initialized with
the additional training using the Java dataset is initialized from CoTexT weights.
However, the training of
JaCoText-L-1CC-PLandJaCoText-L-2CC-PLmodels started fromT5largeweights (previously trained on C4 dataset).We trained
T5largeonCodeSearchNetdataset, and later on the Java dataset during 200,000 steps each and using unimodal data (PL only).Finally, we fine-tune the model on
CONCODEdataset for 45,000 steps.
Results show that
JaCoTextachieves best results.- Unsurprisingly,
JaCoText-Lmodels get the highest scores using the three metrics, becauseT5largehas a more sophisticated architecture. - in both architectures, base and large, the best results are obtained with models that were pretrained on bimodal data. This finding proves that training models with bimodal data performs better than with unimodal data.
- Unsurprisingly,
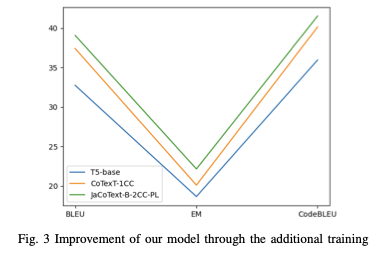
Finally, Fig. 3 shows the improvements of the model
JaCoText-B-2CC-PL with an additional training using the Java dataset.- For a fair comparison, the three models are fine-tuned for 60, 000 steps, and they all follow the T 5base architecture.
RELATED WORK
Early interesting approaches
mapped natural language to source codeusingregular expressionsanddatabase queries.Most recently, neural networks have proven their effectiveness to automatically generate source code from different general-purpose programming languages like Python and Java.
- Simultaneously, large-scale datasets have surged in order to facilitate tackling the problem.
These datasets include
CONCODE,CONALA, andCodeSearchNet.Reference used a BiLSTM encoder, and an RNN decoder to generate syntactically valid parse trees.
- Inspired by the grammar-aware decoder, used Bi-LSTMs encoder to compute the contextual representations of the NL, and an LSTM-based RNN decoder with two-step attention mechanism followed by a copying mechanism to map NL with the source code.
Recently, models based on Transformers and originally intended for the generation of natural language have been of a great benefit for automatic code generation.
PLBARTuses the same model architecture asBARTbase.- Unlike
BARTbase,PLBARTstabilizes the training by adding a normalization layer on the top of both the encoder and the decoder, following. - Similarly to
PLBART, CoTexT (Code and Text Transfer Transformer) is an encoder-decoder model, and it follows T5base architecture.
Moreover, encoder-only models such as RoBERTa-(code) inspired by RoBERTa, and decoder-only models like
- CodeGPT and CodeGPT-adapted have achieved competitive results in the state of the art. Similarly to CodeGPT and CodeGPT-adapted, RoBERTa-(code) is pretrained on
CodeSearchNetdataset. - Unlike RoBERTa-(code), CodeGPT is pretrained on
CodeSearchNetfrom scratch, and CodeGPT-adapted is pretrained starting from pretrained weights of GPT-2 [13]. - Both CodeGPT and CodeGPT-adapted follow the same architecture and training objective of GPT-2.
CONCLUSION
- We present
JaCoText, a set of T5-based pretrained models designed to generate Java code from natural language. - We evaluate the performance of three architectures:
T5base,T5large, andT53Bto generate Java code. We improve the performance of T5 model on Java code generation.
Some takeaways from these experiments are:
- (1) pretraining the model using a dataset designed to tackle a specific task is beneficial,
- (2) additional pretraining can improve the performance of the model
- (3) using a low number of epochs in the pretraining helps improving the final performance.
the models achieve best results on the Java code generation task.
We prove that, each modification in the models, such as the additional training, allows
JaCoTextto have better comprehension of the java programming language.In the future, it would be interesting to explore other neural network models performance, and improve the programming language syntax through the decoding algorithm.
- In addition, since in this paper we focus the work on additional training using code only, we leave additional training using bimodal data for future work.
- We present
Comments powered by Disqus.