HTTP - Method & Requests & Response
- HTTP - Hypertext Transfer Protocol
- HTTP - Method \& Requests \& Response
- 4.3 HTTP Method
- HTTP - Requests
- HTTP - Responses
- HTTP - Header Fields
- General Headers
- Client Request Headers
- Accept 什么样的文件 text/plain/html/x-dvi/x-c
- Accept-Charset 接受的字符
- Accept-Encoding
- Accept-Language
- Authorization 后接encode的验证信息
- Cookie
- Expect 用户要求的server行动
- From
- Host
- If-Match
- If-Modified-Since
- If-None-Match
- If-Range 时间 本日部分更新/全新一日更新
- If-Unmodified-Since 如果在此时间前无修改的话
- Max-Forwards 最大跳跃数
- Proxy-Authorization 认证信息
- Range 取信息范围byte
- Referer 来自何网址的请求
- TE
- User-Agent 阅览器信息
- Server Response Headers
- entity-header field
HTTP - Hypertext Transfer Protocol
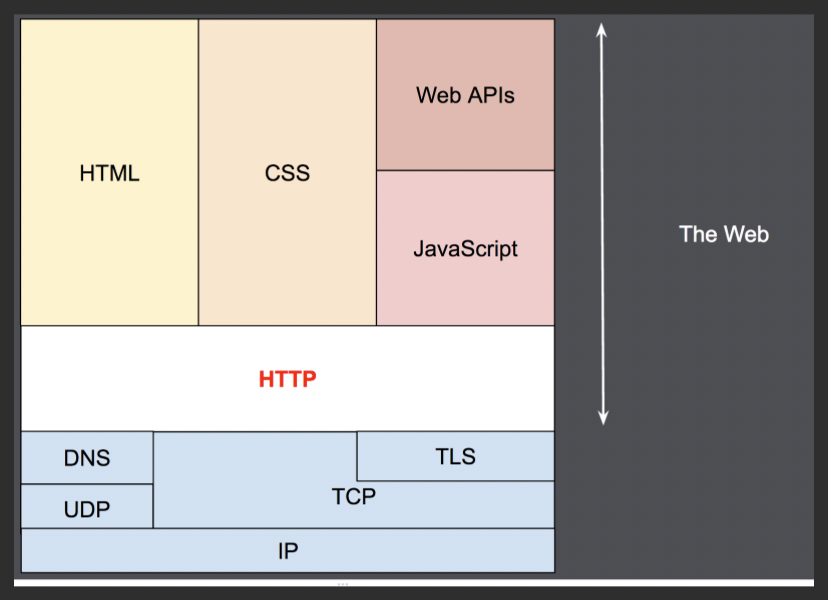
- originally designed to transfer
hypertext- Hypertext “structured text that uses logical links, a.k.a. hyperlinks, between nodes containing text”
- Designed in the early 1990s, HTTP is an extensible protocol which has evolved over time.
- It is an application layer protocol that is sent over TCP, or over a TLS-encrypted TCP connection, though any reliable transport protocol could theoretically be used.
- Due to its extensibility, it is used to fetch hypertext documents, images, videos or post content to servers, like with HTML form results. HTTP can also be used to fetch parts of documents to update Web pages on demand.
- was designed as a request-response Application layer protocol where a client could
request hypertext from a server.- This hypertext could be modified and set up in such a way as to provide all sorts of goodies to the requesting
user agent (UA)— for example, a web browser - example
- a client
requests a particular resourceusing its Uniform Resource Identifier (URI) — most commonly expressed for web requests in the form of a URL (Uniform Resource Locator) - a server
responds to the HTTP requestby providing the resource requested
- This hypertext could be modified and set up in such a way as to provide all sorts of goodies to the requesting
- HTTP can be used for virtually anything anymore, good or bad intent
- It also provides for (mostly) secure communication in its HTTPS version: HTTP over TLS, or SSL.
- Although I could go on and on about other features of HTTP, including some well-know recent attacks against the secure version (HEARTBLEED and POODLE)
- the particular markup of hypertext most see: HTML.
NOTE:
HTMLwas designed specifically to display dataXMLwas created to transport and store data.XML tagsare, basically, whatever you want them to be.
Clients and servers communicate by exchanging individual messages (as opposed to a stream of data).
- Requests: The messages sent by the client, usually a Web browser
- Responses: the messages sent by the server as an answer
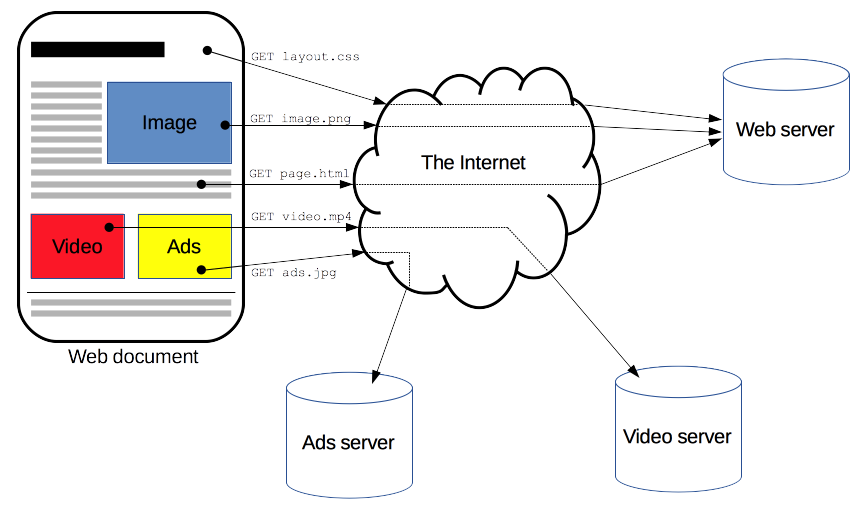
Components of HTTP-based systems
HTTP is a client-server protocol: requests are sent by one entity, the user-agent (or a proxy on behalf of it).
- Most of the time the user-agent is a Web browser, but it can be anything, for example a robot that crawls the Web to populate and maintain a search engine index.
In reality, there are more computers between a browser and the server handling the request.
Each individual request is sent to a server, which handles it and provides an answer, called
the response.Between the client and the server there are numerous entities, proxies, which perform different operations and act as
gateways or caches.

the layered design of the Web, these are hidden in the network and transport layers.
- HTTP is on top, at the application layer, the underlying layers are mostly irrelevant to the description of HTTP.
HTTP is an extensible protocol that is easy to use. The client-server structure, combined with the ability to simply add headers, allows HTTP to advance along with the extended capabilities of the Web.
HTTP/2: adds some complexity, embedding HTTP messages in frames to improve performance , the basic structure of messages has stayed the same since HTTP/1.0.
Session flow remains simple, allowing it to be investigated, and debugged with a simple HTTP message monitor.
Client, user-agent
Client: the user-agent
The user-agent is any tool that acts on the behalf of the user.
This role is primarily performed by the Web browser; or programs used by engineers and Web developers to debug their applications.
.
It is never the server (though some mechanisms have been added over the years to simulate server-initiated messages).
To present a Web page, the browser sends an original request to fetch the HTML document that represents the page.
It then parses this file, making additional requests corresponding to execution scripts, layout information (CSS) to display, and sub-resources contained within the page (usually images and videos).
The Web browser then mixes these resources to present to the user a complete document, the Web page.
Scripts executed by the browser can fetch more resources in later phases and the browser updates the Web page accordingly.
A Web page is a hypertext document .
This means some parts of displayed text are links which can be activated (click) to fetch a new Web page, allowing the user to direct their user-agent and navigate through the Web.
The browser translates these directions in HTTP requests, and further interprets the HTTP responses to present the user with a clear response.
Web server
On the opposite side of the communication channel, is the server , which serves the document as requested by the client .
A server appears as only a single machine virtually:
it may actually be a collection of servers, sharing the load (load balancing) or a complex piece of software interrogating other computers (like cache, a DB server, or e-commerce servers), totally or partially generating the document on demand.
A server is not necessarily a single machine, but several server software instances can be hosted on the same machine. With HTTP/1.1 and the Host header, they may even share the same IP address.
Proxies
Between the Web browser and the server, numerous computers and machines relay the HTTP messages.
Due to the layered structure of the Web stack, most operate at the
transport, network or physical levelsbecoming transparent at the HTTP layer and potentially making a significant impact on performance.Those operating at the application layers are generally called proxies .
These can be transparent,forwarding on the requests they receive without altering them in any way, or non-transparent, change the request in some way before passing it along to the server .
Proxies may perform numerous functions:
- caching
(the cache can be public or private, like the browser cache)
- filtering
(like an antivirus scan or parental controls)
- load balancing
(to allow multiple servers to serve the different requests)
- authentication
(to control access to different resources)
- logging
(allowing the storage of historical information)
- caching
Basic aspects of HTTP
HTTP is simple
- HTTP is generally designed to be simple and human readable, even with the added complexity introduced in HTTP/2 by encapsulating HTTP messages into frames. HTTP messages can be read and understood by humans, providing easier testing for developers, and reduced complexity for newcomers.
HTTP is extensible
- Introduced in HTTP/1.0, HTTP headers make this protocol easy to extend and experiment with .
- New functionality can even be introduced by a simple agreement between a client and a server about a new header’s semantics.
HTTP is stateless, but not sessionless
HTTP is stateless :
- there is no link between two requests being successively carried out on the same connection. This immediately has the prospect of being problematic for users attempting to interact with certain pages coherently, for example, using e-commerce shopping baskets.
HTTP itself is stateless, HTTP cookies allow stateful sessions .
- Using header extensibility, HTTP Cookies are added to the workflow, allowing session creation on each HTTP request to share the same context, or the same state.
HTTP and connections
A connection is controlled at the transport layer, fundamentally out of scope for HTTP.
Though HTTP doesn’t require the underlying transport protocol to be connection-based; only requiring it to be reliable, or not lose messages (so at minimum presenting an error).
transport protocols: TCP is reliable and UDP isn’t.
HTTP therefore relies on the TCP standard, which is connection-based.
Before a client and server can exchange an HTTP request/response pair, they must establish a TCP connection , a process which requires several round-trips.
The default behavior of HTTP/1.0 is to open a separate TCP connection for each HTTP request/response pair . less efficient than sharing a single TCP connection when multiple requests are sent in close succession.
- to mitigate this flaw, HTTP/1.1 introduced pipelining (proved difficult to implement) and persistent connections:
- the underlying TCP connection can be partially controlled using the
Connectionheader.
- the underlying TCP connection can be partially controlled using the
- HTTP/2 multiplexing messages over a single connection
, helping keep the connection warm and more efficient.
Experiments are in progress to design a better transport protocol more suited to HTTP.
- For example, Google is experimenting with QUIC which builds on UDP to provide a more reliable and efficient transport protocol.
What can be controlled by HTTP
This extensible nature of HTTP has, over time, allowed for more control and functionality of the Web. Cache or authentication methods were functions handled early in HTTP history. The ability to relax the origin constraint, by contrast, has only been added in the 2010s.
Here is a list of common features controllable with HTTP.
- Caching
- How documents are cached can be controlled by HTTP .
- The server can instruct 命令 proxies and clients, about what to cache and for how long
.
- The client can instruct intermediate cache proxies to ignore the stored document.
- Relaxing the origin constraint
- To prevent snooping and privacy invasions , Web browsers enforce strict separation between Web sites.
- Only pages from the same origin can access all the information of a Web page. Though such constraint is a burden to the server, HTTP headers can relax this strict separation on the server side, allowing a document to become a patchwork of information sourced from different domains; there could even be security-related reasons to do so.
- Authentication
- Some pages may be protected so that only specific users can access them.
- Basic authentication may be provided by HTTP, either using the
WWW-Authenticate and similar headers, or by setting aspecific session using HTTP cookies.
- Proxy and tunneling
- Servers or clients are often located on intranets and hide their true IP address from other computers. HTTP requests then go through proxies to cross this network barrier.
- Not all proxies are HTTP proxies. The SOCKS protocol, for example, operates at a lower level. Other protocols, like ftp, can be handled by these proxies.
- Sessions
- Using HTTP cookies allows you to link requests with the state of the server .
- This creates sessions, despite basic HTTP being a stateless protocol. This is useful not only for e-commerce shopping baskets, but also for any site allowing user configuration of the output.
HTTP flow
When a client wants to communicate with a server (final server or an intermediate proxy), it performs the following steps:
- Open a TCP connection
:
- The TCP connection is used to send a request, or several, and receive an answer.
- The client may
- open a new connection,
- reuse an existing connection,
- open several TCP connections to the servers.
- Send an HTTP message
:
- HTTP messages (before HTTP/2) are human-readable.
- With HTTP/2, these simple messages are encapsulated in frames , making them impossible to read directly, but the principle remains the same.
- For example:

- Read the response
sent by the server
- Close or reuse the connection
for further requests.
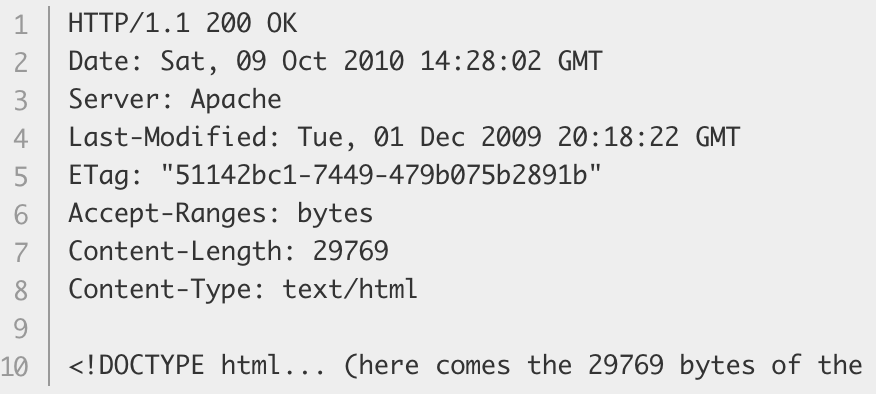
If HTTP pipelining is activated, several requests can be sent without waiting for the first response to be fully received.
HTTP pipelining has proven difficult to implement in existing networks, where old pieces of software coexist with modern versions.
HTTP pipelining has been superseded in HTTP/2 with more robust multiplexing requests within a frame.
HTTP Messages

in HTTP/1.1 and earlier , HTTP messages are human-readable.
In HTTP/2 , these messages are embedded into a frame (binary structure) , allowing optimizations like compression of headers and multiplexing. Even if only part of the original HTTP message is sent in this version of HTTP, the semantics of each message is unchanged and the client reconstitutes (virtually) the original HTTP/1.1 request. It is therefore useful to comprehend HTTP/2 messages in the HTTP/1.1 format.
There are two types of HTTP messages, requests and responses, each with its own format.
HTTP Requests
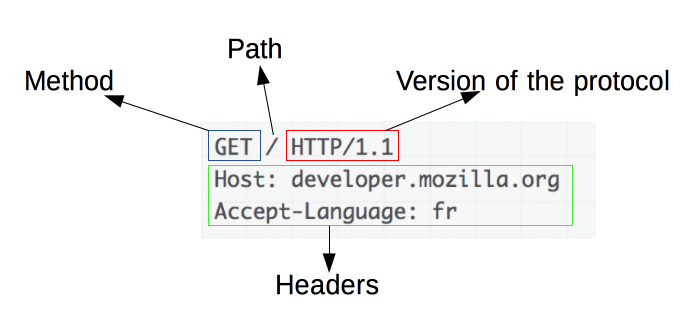
Requests consists of the following elements:
- An HTTP method , usually a verb like GET, POST or a noun like OPTIONS or HEAD
- defines the operation the client wants to perform.
- Typically, a client wants to fetch a resource (GET) or post the value of an HTML form (POST).
- The path of the resource to fetch ; the URL of the resource stripped from elements that are obvious from the context
- the protocol (http://), the domain (developer.mozilla.org), the TCP port (80).
The version of the HTTP protocol .
- Optional headers
: convey additional information for the servers.
- Or a body , for some methods like
POST, similar to those in responses, which contain the resource sent.
HTTP Responses
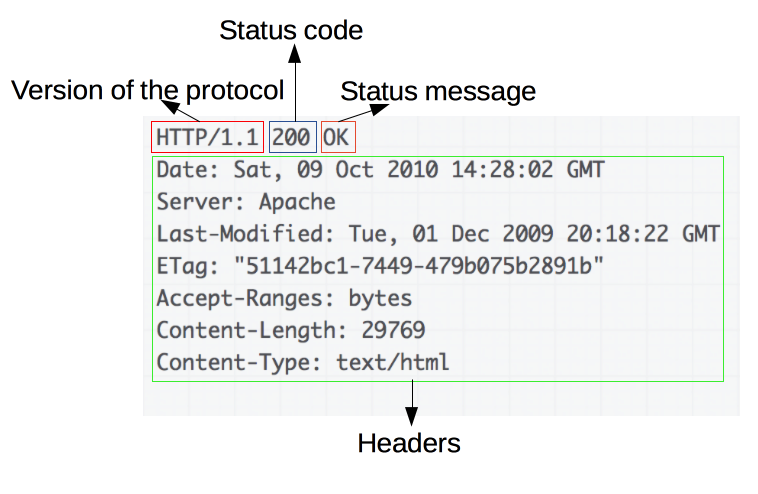
Responses consist of the following elements:
The version of the HTTP protocol they follow.
A status code , indicating if the request was successful, or not, and why.
A status message , a non-authoritative short description of the status code.
- HTTP headers
, like those for requests.
- Optionally, a body containing the fetched resource.
APIs based on HTTP
The most commonly used API based on HTTP is the XMLHttpRequest API
- can be used to exchange data between a user agent and a server.
The modern Fetch API provides the same features with a more powerful and flexible feature set.
Another API, server-sent events, is a one-way service that allows a server to send events to the client, using HTTP as a transport mechanism.
Using the EventSource interface, the client opens a connection and establishes event handlers. The client browser automatically converts the messages that arrive on the HTTP stream into appropriate Event objects, delivering them to the event handlers that have been registered for the events’ type if known, or to the onmessage event handler if no type-specific event handler was established.
HTTP - Method & Requests & Response
4.3 HTTP Method
4.3.1. GET

Syntax
GET /index.html
The GET method
- requests transfer of a current representation for the target resource.
- Requests using
GETshould only retrieve data. - Not secure, content will be in the URL.
- the primary mechanism of information retrieval and the focus of performance optimizations.
- when speak of retrieving some information via HTTP, it is generally making a
GETrequest.
- when speak of retrieving some information via HTTP, it is generally making a
- Requests using
- It is tempting to think of
- resource identifiers as remote file system pathnames
- representations as a copy of the contents of such files.
- In fact, that is how many resources are implemented. However, there are no such limitations in practice.
- The HTTP interface for a resource is like a tree of content objects, a programmatic view on various database records, a gateway to other information systems.
- Even when the URI mapping mechanism is tied to a file system, an origin server might be configured to execute the files with the request as input and send the output as the representation rather than transfer the files directly.
- only the origin server needs to know
- how each of its resource identifiers corresponds to an implementation
- how each implementation manages to select
- send a current representation of the target resource in a response to
GET.
- A client can alter the semantics of
GETto be a “range request”,- requesting transfer of only some part(s) of the selected representation, by sending a Range header field in the request ([RFC7233]).
- A payload within a
GETrequest message has no defined semantics;- sending a payload body on a
GETrequest might cause some existing implementations to reject the request.
- sending a payload body on a
- The response to a
GETrequest is cacheable;- a cache MAY use it to satisfy subsequent
GETandHEADrequests unless otherwise indicated by the Cache-Control header field (Section 5.2 of [RFC7234]).
- a cache MAY use it to satisfy subsequent
4.3.2. HEAD

Syntax
HEAD /index.html
| Method | Body | header |
|---|---|---|
GET | server MUST NOT send a message body in the response the response terminates at the end of the header section | |
HEAD | HEAD response should not have a body. If so, it must be ignored. | server SHOULD send the same header fields in response to a HEAD request as for GET request except the payload header fields MAY be omitted. |
- A response to a
HEADmethod should not have abody. If so, it must be ignored.- Even so, entity headers describing the content of the body, like Content-Length may be included in the response.
- They don’t relate to the body of the
HEADresponse (should be empty), but to the body which a similar request using theGETmethod would have returned as a response.
- If the result of a
HEADrequest shows that a cached resource after aGETrequest is now outdated- the cache is invalidated, even if no
GETrequest has been made.
- the cache is invalidated, even if no
- This method can be used for obtaining metadata about the selected representation without transferring the representation data
- often used for testing hypertext links for validity, accessibility, and recent modification.
- 允许客户端在未获取实际资源的情况下,对资源的首部进行检查。
- 在不获取资源的情况下了解资源的情况(比如,判断其类型);
- 通过查看响应中的状态码,看看某个对象是否存在;
- 通过查看首部,测试资源是否被修改了。
- A payload within a
HEADrequest message has no defined semantics;- sending a payload body on a
HEADrequest might cause some existing implementations to reject the request.
- sending a payload body on a
- The response to a
HEADrequest is cacheable;- a cache MAY use it to satisfy subsequent
HEADrequests unless otherwise indicated by the Cache-Control header field (Section 5.2 of [RFC7234]).
- a cache MAY use it to satisfy subsequent
- A
HEADresponse might also have an effect on previously cachedGETresponses. - 服务器开发者必须确保返回的首部与
GET请求所返回的首部完全相同。遵循 HTTP/1.1 规范,就必须实现HEAD方法。
4.3.3. POST

Syntax
POST /test
The POST method
- requests that the target resource process the representation enclosed in the request according to the resource’s own specific semantics.
sends data to the server.
The type of the body of the request is indicated by the
Content-Typeheader.POSTis designed to allow a uniform method to cover the following functions:- Providing a block of data
- such as the fields entered into an HTML form, to a data-handling process;
- Posting a message
- to a bulletin board, newsgroup, mailing list, blog, or similar group of articles;
- Creating a new resource that has yet to be identified by the origin server
- Appending data to a resource’s existing representation(s).
- Annotation of existing resources
- Adding a new user through a signup modal;
- Extending a database through an append operation.
- Providing a block of data
The difference between PUT and POST
PUTis idempotent: calling it once or several times successively has the same effect (no side effect),- successive identical
POSTmay have additional effects, like passing an order several times.
Responses to POST:
- origin server indicates response semantics by appropriate status code depending on the result of the
POSTrequest; - almost all of the status codes might be received in a response to
POST- (the exceptions being 206 (Partial Content), 304 (Not Modified), and 416 (Range Not Satisfiable)).
- If resources has been created on the origin server by processing a
POSTrequest,- the origin server SHOULD send a
201 (Created) responsecontaining - a
Location headerfield that provides an identifier for the primary resource created - and a
representationdescribes the status of the request while referring to the new resource(s).
- the origin server SHOULD send a
- If the result of processing a
POSTwould be equivalent to a representation of an existing resource- an origin server MAY redirect the user agent to that resource by sending a
303 (See Other) responsewith the existing resource’s identifier in the Location field. - This has the benefits of providing the user agent a resource identifier and transferring the representation via a method more amenable to shared caching, though at the cost of an extra request if the user agent does not already have the representation cached.
- an origin server MAY redirect the user agent to that resource by sending a
Responses to
POSTrequests are only cacheable when they include explicit freshness information. However,POSTcaching is not widely implemented.
- For cases where an origin server wishes the client to be able to cache the result of a
POSTin a way that can be reused by a laterGET,- the origin server MAY send a
200 (OK) responsecontaining - the result
- and a
Content-Locationheader field that has the same value as the POST’s effective request URI (Section 3.1.4.2).
- the origin server MAY send a
A POST request is typically sent via an HTML form and results in a change on the server.
- the
content typeis selected by putting the adequate string in- the
enctypeattribute of the<form>element - or the
formenctypeattribute of the<input>or<button>elements:
- the
application/x-www-form-urlencoded:- the keys and values are encoded in key-value tuples separated by
'&', with a'='between the key and the value. - Non-alphanumeric characters in both keys and values are percent encoded:
- this is the reason why this type is not suitable to use with binary data (use multipart/form-data instead)
- the keys and values are encoded in key-value tuples separated by
multipart/form-data:- each value is sent as a block of data (“body part”), with a user agent-defined delimiter (“boundary”) separating each part.
- The keys are given in the
Content-Dispositionheader of each part.
text/plain
When the POST request is sent via method other than an HTML form — like XMLHttpRequest — the body can take any type.
Example
A simple form using the default application/x-www-form-urlencoded content type:
1
2
3
4
5
POST /test HTTP/1.1
Host: foo.example
Content-Type: application/x-www-form-urlencoded
Content-Length: 27
field1=value1&field2=value2
A form using the multipart/form-data content type:
1
2
3
4
5
6
7
8
9
10
POST /test HTTP/1.1
Host: foo.example
Content-Type: multipart/form-data;boundary="boundary"
--boundary
Content-Disposition: form-data; name="field1"
value1
--boundary
Content-Disposition: form-data; name="field2"; filename="example.txt"
value2
--boundary--
4.3.4. PUT

Syntax
PUT /new.html HTTP/1.1
URI = Universal Resource Identifier
URL = Universal Resource Locator
The PUT method
- requests the state of the target resource be created or replaced with the state defined by the representation enclosed in the request message payload.
Request
1
2
3
4
5
PUT /new.html HTTP/1.1
Host: example.com
Content-type: text/html
Content-length: 16
<p>New File</p>
Responses
- A successful response only implies that the user agent’s intent was achieved at the time of its processing by the origin server.
- A successful
PUTof a given representation would suggest that a subsequentGETon that same target resource will result in an equivalent representation being sent in a200 (OK) response. - However, there is no guarantee that such a state change will be observable, since the target resource might be acted upon by other user agents in parallel, or might be subject to dynamic processing by the origin server, before any subsequent
GETis received.
- A successful
If the target resource
- does not have a current representation and the
PUTsuccessfully creates one- the origin server MUST inform the user agent by sending a
201 (Created) response.1 2
HTTP/1.1 201 Created Content-Location: /new.html
- the origin server MUST inform the user agent by sending a
- does have a current representation and that representation is successfully modified in accordance with the state of the enclosed representation
- the origin server MUST send either a
200 (OK) / 204 (No Content) responseto indicate successful completion of the request.1 2
HTTP/1.1 204 No Content Content-Location: /existing.html
- the origin server MUST send either a
- origin server SHOULD ignore unrecognized header fields received in a
PUTrequest- do not save them as part of the resource state
- origin server SHOULD verify that the
PUTrepresentation is consistent with any 参数 constraints the server has for the target resource that cannot or will not be changed by thePUT.- particularly important when the origin server uses internal configuration information related to the URI to set the values for representation metadata on
GETresponses. - When a
PUTrepresentation is inconsistent 不一致的 with the target resource- For example
- if the target resource is configured to always have a Content-Type of “text/html”
- and the representation being
PUThas a Content-Type of “image/jpeg”
- the origin server SHOULD
- make them consistent, by transforming the representation or changing the resource configuration
- transform the
PUTrepresentation to a format consistent with that of the resource before saving it as the new resource state; - reconfigure the target resource to reflect the new media type;
- or respond with an appropriate error message.
- containing sufficient information to explain why the representation is unsuitable.
- The
409 (Conflict) or 415 (Unsupported Media Type) status codesare suggested, with the latter being specific to constraints on Content-Type values. - reject the request with a
415 (Unsupported Media Type) responseindicating that the target resource is limited to “text/html”, perhaps including a link to a different resource that would be a suitable target for the new representation.
- For example
- particularly important when the origin server uses internal configuration information related to the URI to set the values for representation metadata on
- HTTP does not define exactly how a
PUTmethod affects the state of an origin server beyond what can be expressed by the intent of the user agent request and the semantics of the origin server response. - It does not define what a resource might be, in any sense of that word, beyond the interface provided via HTTP.
- It does not define how resource state is “stored”, nor how such storage might change as a result of a change in resource state, nor how the origin server translates resource state into representations.
- Generally speaking, all implementation details behind the resource interface are intentionally hidden by the server.
An origin server MUST NOT send a validator header field, such as an ETag or Last-Modified field, in a successful response to PUT
- unless the request’s representation data was saved without any transformation applied to the body (i.e., the resource’s new representation data is identical to the representation data received in the
PUTrequest) and the validator field value reflects the new representation.
This requirement allows a user agent to know when the representation body it has in memory remains current as a result of the PUT, thus not in need of being retrieved again from the origin server, and that the new validator(s) received in the response can be used for future conditional requests in order to prevent accidental overwrites.
POST和PUT请求最根本的区别是 Request-URI 的含义不同。
- POST请求里的URI指示一个能处理请求实体的资源:
- 资源可能是一段程序,如jsp里的servlet),一个数据接收过程,一个网关(gateway,译注:网关和代理服务器的区别是:网关可以进行协议转换,而代理服务器不能,只是起代理的作用,比如缓存服务器其实就是一个代理服务器),或者一个单独接收注释的实体。
- PUT方法请求里有一个实体:
- 用户代理知道URI意指什么,并且服务器不能把此请求应用于其他URI指定的资源。
- 如果服务器期望请求被应用于一个不同的URI,那么它必须发送301(永久移动了)响应;
- 用户代理可以自己决定是否重定向请求。
The fundamental difference between the POST and PUT methods:
- the different intent for the enclosed representation.
- The target resource in a
POSTrequest is intended to handle the enclosed representation according to the resource’s own semantics, - the enclosed representation in a
PUTrequest is replacing the state of the target resource.
- The target resource in a
- the intent of
PUTis idempotent and visible to intermediaries, even though the exact effect is only known by the origin server.- calling it once or several times successively has the same effect (no side effect)
Proper interpretation of a PUT request presumes that the user agent knows which target resource is desired.
- A service that selects a proper URI on behalf of the client, after receiving a state-changing request, SHOULD be implemented using the
POSTmethod rather than PUT. - If the origin server will not make the requested
PUTstate change to the target resource and instead wishes to have it applied to a different resource, such as when the resource has been moved to a different URI- then the origin server MUST send an appropriate 3xx (Redirection) response;
- the user agent make its own decision regarding whether or not to redirect the request.
A PUT request applied to the target resource can have side effects on other resources.
- For example
- an article have a URI for identifying “the current version” (a resource) that is separate from the URIs identifying each particular version (different resources that at one point shared the same state as the current version resource).
- A successful
PUTrequest on “the current version” URI might therefore create a new version resource in addition to changing the state of the target resource, and might also cause links to be added between the related resources.
An origin server that allows PUT on a given target resource MUST send a 400 (Bad Request) response to a PUT request that contains a Content-Range header field, since the payload is likely to be partial content that has been mistakenly PUT as a full representation.
- Partial content updates are possible by targeting a separately identified resource with state that overlaps a portion of the larger resource, or by using a different method that has been specifically defined for partial updates (for example, the PATCH method defined in [RFC5789]).
PUT responses are not cacheable.
- If a successful
PUTrequest passes through a cache that has one or more stored responses for the effective request URI, those stored responses will be invalidated.
4.3.5. DELETE
 
Syntax
DELETE /file.html HTTP/1.1

The DELETE method
- requests that the origin server remove the association between the target resource and its current functionality.
- similar to the rm command in UNIX:
- a deletion operation on the URI mapping of the origin server rather than an expectation that the previously associated information be deleted.
If the target resource has one or more current representations, they might or might not be destroyed by the origin server, and the associated storage might or might not be reclaimed,
- depending entirely on the nature of the resource and its implementation by the origin server (which are beyond the scope of this specification).
other implementation aspects of a resource might need to be deactivated or archived as a result of a DELETE, such as database or gateway connections.
- In general, it is assumed that the origin server will only allow
DELETEon resources for which it has a prescribed mechanism for accomplishing the deletion.
Relatively few resources allow the DELETE method
- its primary use for remote authoring environments, where the user has some direction regarding its effect.
- For example,
- a resource that was previously created using a
PUTrequest, - or identified via the
Location headerfield after a201 (Created) responseto aPOSTrequest - might allow a corresponding
DELETErequest to undo those actions. - Similarly, custom user agent implementations that implement an authoring function, such as revision control clients using HTTP for remote operations, might use
DELETEbased on an assumption that the server’s URI space has been crafted to correspond to a version repository.
- a resource that was previously created using a
Responses
If a DELETE method is successfully applied, the origin server SHOULD send
- a
202 (Accepted) status codeif the action will likely succeed but has not yet been enacted, - a
204 (No Content) status codeif the action has been enacted and no further information is to be supplied, - a
200 (OK) status codeif the action has been enacted and the response message includes a representation describing the status.
1
2
3
4
5
6
7
8
HTTP/1.1 200 OK
Date: Wed, 21 Oct 2015 07:28:00 GMT
<html>
<body>
<h1>File deleted.</h1>
</body>
</html>
A payload within a DELETE request message has no defined semantics; sending a payload body on a DELETE request might cause some existing implementations to reject the request.
Responses to the DELETE method are not cacheable.
- If a
DELETErequest passes through a cache that has one or more stored responses for the effective request URI, those stored responses will be invalidated.
4.3.6. CONNECT

Syntax
CONNECT www.example.com:443 HTTP/1.1
The CONNECT method
- a hop-by-hop method.
- requests that
the recipient establish a tunnel to the destination origin serveridentified by the request-target, starts two-way communications with the requested resource.- if successful, thereafter restrict its behavior to blind forwarding of packets, in both directions, until the tunnel is closed.
- Tunnels are commonly used to create an end-to-end virtual connection, through one or more proxies, which can then be secured using TLS (Transport Layer Security).
For example, the CONNECT method can be used to access websites that use SSL (HTTPS).
- The client asks an HTTP Proxy server to tunnel the TCP connection to the desired destination.
- The server then proceeds to make the connection on behalf of the client.
- Once the connection has been established by the server, the Proxy server continues to proxy the TCP stream to and from the client.
CONNECT is intended only for use in requests to a proxy.
- An origin server that receives a
CONNECTrequest for itself MAY respond with a2xx (Successful) status codeto indicate that a connection is established. - However, most origin servers do not implement
CONNECT.
A client sending a CONNECT request MUST send the authority form of request-target;
- i.e., the request-target consists of only the host name and port number of the tunnel destination, separated by a colon.
- For example,
1
2
CONNECT server.example.com:80 HTTP/1.1
Host: server.example.com:80
The recipient proxy can establish a tunnel either
- by directly connecting to the request-target
- or, if configured to use another proxy, by forwarding the
CONNECTrequest to the next inbound proxy.
Any 2xx (Successful) response # the sender (and all inbound proxies) will switch to tunnel mode immediately after the blank line that concludes the successful response’s header section; data received after that blank line is from the server identified by the request-target.
Any response other than a successful response # the tunnel has not yet been formed and that the connection remains governed by HTTP.
A tunnel is closed when a tunnel intermediary detects that either side has closed its connection:
- the intermediary MUST attempt to send any outstanding data that came from the closed side to the other side, close both connections, and then discard any remaining data left undelivered.
Proxy authentication might be used to establish the authority to create a tunnel.
- For example,
1
2
3
CONNECT server.example.com:80 HTTP/1.1
Host: server.example.com:80
Proxy-Authorization: basic aGVsbG86d29ybGQ=
significant risks in establishing a tunnel to arbitrary servers, well-known or reserved destination TCP port that is not for Web traffic.
- For example,
- a
CONNECTto a request-target of “example.com:25” would suggest that the proxy connect to the reserved port for SMTP traffic; - if allowed, that could trick the proxy into relaying spam email.
- Proxies that support
CONNECTSHOULD restrict its use to a limited set of known ports or a configurable whitelist of safe request targets.
- A server MUST NOT send any Transfer-Encoding or Content-Length header fields in a 2xx (Successful) response to
CONNECT. - A client MUST ignore any Content-Length or Transfer-Encoding header fields received in a successful response to
CONNECT.
A payload within a CONNECT request message has no defined semantics;
- sending a payload body on a
CONNECTrequest might cause some existing implementations to reject the request.
CONNECT Responses are not cacheable.
4.3.7. OPTIONS

Syntax
1
2
OPTIONS /index.html HTTP/1.1
OPTIONS * HTTP/1.1
The OPTIONS method
- requests information about the communication options available for the target resource, at either the origin server or an intervening intermediary.
- allows a client to determine the options and/or requirements associated with a resource, or the capabilities of a server, without implying a resource action.
An OPTIONS request with an asterisk ("*")
- the request-target applies to the server in general rather than to a specific resource.
- Since a server’s communication options typically depend on the resource, the
"*"request is only useful as a “ping” or “no-op” type of method; - it does nothing beyond allowing the client to test the capabilities of the server.
- For example
- this can be used to test a proxy for HTTP/1.1 conformance (or lack thereof).
If the OPTIONS request-target is not an asterisk
- the
OPTIONSrequest applies to the options that are available when communicating with the target resource.
A server generating a successful response to OPTIONS SHOULD send any header fields that indicate optional features implemented by the server and applicable to the target resource (e.g., Allow), including potential extensions not defined by this specification.
- The response payload, if any
- might also describe the communication options in a machine or human-readable representation.
- A standard format for such a representation is not defined by this specification, but might be defined by future extensions to HTTP.
- A server MUST generate a
Content-Length fieldwith a value of “0” if no payload body is sent in the response.
A client MAY send a Max-Forwards header field in an OPTIONS request to target a specific recipient in the request chain. A proxy MUST NOT generate a Max-Forwards header field while forwarding a request unless that request was received with a Max-Forwards field.
A client that generates an OPTIONS request containing a payload body MUST send a valid Content-Type header field describing the representation media type.
- Although this specification does not define any use for such a payload, future extensions to HTTP might use the
OPTIONSbody to make more detailed queries about the target resource.
Responses to the OPTIONS method are not cacheable.
Identifying allowed request methods
find out which request methods a server supports
- use
curland issue anOPTIONSrequest:
1
2
3
4
5
6
7
8
9
10
11
curl -X OPTIONS https://example.org -i
// The response then contains an Allow header with the allowed methods:
HTTP/1.1 204 No Content
Allow: OPTIONS, GET, HEAD, POST
Cache-Control: max-age=604800
Date: Thu, 13 Oct 2016 11:45:00 GMT
Expires: Thu, 20 Oct 2016 11:45:00 GMT
Server: EOS (lax004/2813)
x-ec-custom-error: 1
- Preflighted requests in CORS
- In CORS, a preflight request with the
OPTIONSmethod is sent, server can respond whether it is acceptable to send the request with these parameters. - The
Access-Control-Request-Methodheader- notifies the server as part of a preflight request that when the actual request is sent,
- it will be sent with a
POSTrequest method.
- The
Access-Control-Request-Headersheader- notifies the server that when the actual request is sent, it will be sent with a
X-PINGOTHER and Content-Typecustom headers. - The server now has an opportunity to determine whether it wishes to accept a request under these circumstances.
- notifies the server that when the actual request is sent, it will be sent with a
- In CORS, a preflight request with the
1
2
3
4
5
6
7
8
9
10
OPTIONS /resources/post-here/ HTTP/1.1
Host: bar.other
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Origin: https://foo.example
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
- The server responds with
Access-Control-Allow-Methodsand says thatPOST, GET, and OPTIONSare viable methods to query the resource in question. - This header is similar to the Allow response header, but used strictly within the context of CORS.
1
2
3
4
5
6
7
8
9
10
HTTP/1.1 204 No Content
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: https://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
4.3.8. TRACE

Syntax
TRACE /index.html
The TRACE method
- requests a remote, application-level loop-back of the request message.
- performs a message loop-back test along the path to the target resource
- useful debugging mechanism.
- The final recipient of the request SHOULD reflect the message received,
- excluding some fields described below, back to the client as the message body of a
200 (OK) responsewith a Content-Type of “message/http”.
- excluding some fields described below, back to the client as the message body of a
- The final recipient is either the origin server or the first server to receive a
Max-Forwardsvalue of zero (0) in the request.
TRACE request,
- A client MUST NOT generate header fields containing sensitive data that might be disclosed by the response.
- do not send stored user credentials or cookies in a
TRACErequest.
- do not send stored user credentials or cookies in a
- The final recipient of the request exclude any request header fields that are likely to contain sensitive data when that recipient generates the response body.
TRACE allows the client to see what is being received at the other end of the request chain and use that data for testing or diagnostic information.
- The value of the
Viaheader field is of particular interest, since it acts as a trace of the request chain. - Use of the Max-Forwards header field allows the client to limit the length of the request chain, which is useful for testing a chain of proxies forwarding messages in an infinite loop.
A client MUST NOT send a message body in a TRACE request.
Responses to the TRACE method are not cacheable.
PATCH
The HTTP PATCH request method
- applies partial modifications to a resource.
- PATCH is somewhat analogous to the “update” concept found in CRUD (in general, HTTP is different than CRUD, and the two should not be confused).
A PATCH request is considered a set of instructions on how to modify a resource.
- Contrast this with
PUT; which is a complete representation of a resource.
A PATCH is not necessarily idempotent, although it can be.
- Contrast with
PUT, always idempotent. - For example
- if an auto-incrementing counter field is an integral part of the resource, then a
PUTwill naturally overwrite it (since it overwrites everything), but not necessarily so forPATCH.
PATCH (like PUT) may have side-effects on other resources.
- To find out whether a server supports
PATCH - a server can advertise its support by adding it to the list in the
Allow or Access-Control-Allow-Methods(for CORS) response headers. - Another (implicit) indication that
PATCHis allowed, is the presence of theAccept-Patchheader, which specifies the patch document formats accepted by the server.
Syntax
1
2
3
4
5
6
7
8
9
PATCH /file.txt HTTP/1.1
Example
Request
PATCH /file.txt HTTP/1.1
Host: www.example.com
Content-Type: application/example
If-Match: "e0023aa4e"
Content-Length: 100
[description of changes]
Response
- A successful response is indicated by any
2xx status code. 204 response codeis used, because the response does not carry a payload body.- A
200 responsecould have contained a payload body.
1
2
3
HTTP/1.1 204 No Content
Content-Location: /file.txt
ETag: "e0023aa4f"
HTTP - Requests
An HTTP client sends an HTTP request to a server in the form of a request message which includes following format:
1
2
3
4
5
6
7
8
A Request-line
Zero or more header (General|Request|Entity) fields followed by CRLF
An empty line (i.e., a line with nothing preceding the CRLF)
indicating the end of the header fields
Optionally a message-body
Request-Line
The Request-Line begins with a method token, followed by the Request-URI and the protocol version, and ending with CRLF. The elements are separated by space SP characters.
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
Request-URI
The Request-URI is a Uniform Resource Identifier and identifies the resource upon which to apply the request.
Request-URI = "*" | absoluteURI | abs_path | authority
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 1. The asterisk *
# used when an HTTP request does not apply to a particular resource, but to the server itself
# only allowed when the method used does not necessarily apply to a resource.
OPTIONS * HTTP/1.1
# 2. The absoluteURI
# used when an HTTP request is being made to a proxy.
# The proxy is requested to forward the request or service from a valid cache, and return the response.
GET https://www.w3.org/pub/WWW/TheProject.html HTTP/1.1
# 3. The most common form of Request-URI
# to identify a resource on an origin server or gateway.
# For example, a client wishing to retrieve a resource directly from the origin server would create a TCP connection to port 80 of the host "www.w3.org" and send the following lines:
GET /pub/WWW/TheProject.html HTTP/1.1
Host: www.w3.org
# Note that the absolute path cannot be empty; if none is present in the original URI, it MUST be given as "/" (the server root).
General-header, Entity-header and Request header
POST/cgi-bin/process.cgiHTTP/1.1User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT)Host: www.tutorialspoint.comContent-Type: application/x-www-form-urlencodedContent-Length: 12345Accept-Language: en-usAccept-Encoding: gzip, deflateConnection: Keep-Alive- licenseID=string&content=string&/paramsXML=string
Request Header Fields
The request-header fields
- allow the client to pass additional information about the request, and about the client itself, to the server.
- These fields act as request modifiers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# to fetch hello.htm page from the web server running on tutorialspoint.com
# not sending any request data to the server because we are fetching a plain HTML page from the server.
GET /hello.htm HTTP/1.1
User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT)
Host: www.tutorialspoint.com
Accept-Language: en-us
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
# Connection is a general-header, and the rest of the headers are request headers.
POST /cgi-bin/process.cgi HTTP/1.1
User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT)
Host: www.tutorialspoint.com
Content-Type: application/x-www-form-urlencoded
# the passed data is a simple web form data
Content-Length: 12345
# the actual length of the data put in the message body
Accept-Language: en-us
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
licenseID=string&content=string&/paramsXML=string
HTTP - Responses
After receiving and interpreting a request message, a server responds with an HTTP response message:
1
2
3
4
5
6
7
A Status-line
Zero or more header (General|Response|Entity) fields followed by CRLF
An empty line (i.e., a line with nothing preceding the CRLF) indicating the end of the header fields
Optionally a message-body
Message Status-Line
A Status-Line consists of the protocol version followed by a numeric status code and its associated textual phrase.
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF```
HTTP Version
HTTP-Version = HTTP/1.1```
Status Code
3-digit integer
- first digit of the Status-Code defines the class of response
- the last two digits do not have any categorization role.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1xx: Informational
# It means the request was received and the process is continuing.
2xx: Success
# It means the action was successfully received, understood, and accepted.
3xx: Redirection
# It means further action must be taken in order to complete the request.
4xx: Client Error
# It means the request contains incorrect syntax or cannot be fulfilled.
5xx: Server Error
# It means the server failed to fulfill an apparently valid request.
HTTP - Header Fields
HTTP header fields provide required information about the request or response, or about the object sent in the message body. There are four types of HTTP message headers:
General-header: These header fields have general applicability for both request and response messages.Client Request-header: These header fields have applicability only for request messages.Server Response-header: These header fields have applicability only for response messages.Entity-header: These header fields define meta information about the entity-body or, if no body is present, about the resource identified by the request.
General Headers
Cache-Control 怎么留留多久
Cache-Control : cache-request-directive | cache-response-directive- An HTTP client or server use it
- specify directives that MUST be obeyed by all the caching system.
- specify parameters for the cache
cache request directives that can be used by the client in its HTTP request:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1 no-cache
# A cache must not use the response to satisfy a subsequent request without successful revalidation with the origin server.
2 no-store
# The cache should not store anything about the client request or server response.
3 max-age = seconds
# the client is willing to accept a response
# whose age is not greater than the specified time in seconds.
4 max-stale [ = seconds ]
# the client is willing to accept a response that has exceeded its expiration time.
# If seconds are given, it must not be expired by more than that time.
5 min-fresh = seconds
# the client is willing to accept a response
# whose freshness lifetime is not less than its current age plus the specified time in seconds.
6 no-transform
# Does not convert the entity-body.
7 only-if-cached
# Does not retrieve new data.
# The cache can send a document only if it is in the cache, and should not contact the origin-server to see if a newer copy exists.
cache response directives that can be used by the server in its HTTP response:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1 public
# the response may be cached by any cache.
2 private
# all or part of the response message is intended for a single user
# must not be cached by a shared cache.
3 no-cache
# A cache must not use the response to satisfy a subsequent request without successful re-validation with the origin server.
4 no-store
# The cache should not store anything about the client request or server response.
5 no-transform
# Does not convert the entity-body.
6 must-revalidate
# The cache must verify the status of the stale documents before using it and expired ones should not be used.
7 proxy-revalidate
# The proxy-revalidate directive has the same meaning as the must- revalidate directive, except that it does not apply to non-shared user agent caches.
8 max-age = seconds
# the client is willing to accept a response
# whose age is not greater than the specified time in seconds.
9 s-maxage = seconds
# The maximum age specified by this directive overrides the maximum age specified by either the max-age directive or the Expires header.
# The s-maxage directive is always ignored by a private cache.
Connection 告诉server希望close还是keep-alive
- allows the sender to
specify optionsthat are desired for that particular connection andmust not be communicated by proxiesover further connections.
Connection : "Connection"
- HTTP/1.1 defines the “close” connection option for the sender
- to signal that the connection will be closed after completion of the response.
1
2
3
4
5
Connection: close
# By default, HTTP 1.1 uses persistent connections, where the connection does not automatically close after a transaction. HTTP 1.0, on the other hand, does not have persistent connections by default.
Connection: keep-alive
# If a 1.0 client wishes to use persistent connections, it uses the keep-alive parameter
Date
All HTTP date/time stamps MUST be represented in Greenwich Mean Time (GMT), without exception.
HTTP applications are allowed to use any of the following three representations of date/time stamps:
1
2
3
4
# Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822, updated by RFC 1123
Here the first format is the most preferred one.
Sunday, 06-Nov-94 08:49:37 GMT ; RFC 850, obsoleted by RFC 1036
Sun Nov 6 08:49:37 1994 ; ANSI Cs asctime() format
Pragma
to include implementation specific directives that might apply to any recipient along the request/response chain.
1
2
3
Pragma: no-cache
# The only directive defined in HTTP/1.0 is the no-cache directive and is maintained in HTTP 1.1 for backward compatibility.
# No new Pragma directives will be defined in the future.
Trailer
indicates that the given set of header fields is present in the trailer of a message encoded with chunked transfer-coding.
1
2
3
4
5
6
Trailer : field-name
# Message header fields listed in the Trailer header field must not include the following header fields:
Transfer-Encoding
Content-Length
Trailer
Transfer-Encoding
indicates what type of transformation has been applied to the message body
- in order to safely transfer it between the sender and the recipient.
- This is not the same as content-encoding because transfer-encodings are a property of the message, not of the entity-body.
- All transfer-coding values are case-insensitive.
1
Transfer-Encoding: chunked
Upgrade
allows the client to specify what additional communication protocols it supports and would like to use if the server finds it appropriate to switch protocols.
- provide a simple mechanism for transition from HTTP/1.1 to some other, incompatible protocol.
1
Upgrade: HTTP/2.0, HTTPS/1.3, IRC/6.9, RTA/x11
Via 中途proxy路径
- to provide a simple mechanism for transition from HTTP/1.1 to some other, incompatible protocol.
- must be used by gateways and proxies to indicate the intermediate protocols and recipients.
- For example:
- a request message sent from an HTTP/1.0
user agentto aninternal proxy code-named "fred" internal proxy code-named "fred"uses HTTP/1.1 to forward the request to apublic proxy at nowhere.compublic proxy at nowhere.comto forward it to theorigin server at www.ics.uci.edu.- request completes
- a request message sent from an HTTP/1.0
- The request received by www.ics.uci.edu would then have the following Via header field:
1
Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1)
Warning
- carry
additional information about the status or transformationof a message whichmight not be reflected in the message. - A response may carry more than one Warning header.
1
Warning : warn-code SP warn-agent SP warn-text SP warn-date
Client Request Headers
Accept 什么样的文件 text/plain/html/x-dvi/x-c
- specify
certain media typeswhich are acceptable for the response.
1
2
3
4
5
6
7
8
Accept: type/subtype [q=qvalue]
# Multiple media types can be listed separated by commas
# the optional qvalue represents an acceptable quality level for accept types on a scale of 0 to 1.
Accept: text/plain; q=0.5, text/html, text/x-dvi; q=0.8, text/x-c
# This would be interpreted as text/html and text/x-c are the preferred media types
# but if they do not exist, then send the text/x-dvi entity
# if that does not exist, send the text/plain entity.
Accept-Charset 接受的字符
- indicate what
character setsare acceptable for the response.
1
2
3
4
5
Accept-Charset: character_set [q=qvalue]
# Multiple character sets can be listed separated by commas and the optional qvalue represents an acceptable quality level for nonpreferred character sets on a scale of 0 to 1. Following is an example:
Accept-Charset: iso-8859-5, unicode-1-1; q=0.8
# The special value "*", if present in the Accept-Charset field, matches every character set and if no Accept-Charset header is present, the default is that any character set is acceptable.
Accept-Encoding
- similar to Accept, but restricts the
content-codings that are acceptablein the response.
1
2
3
4
5
6
7
8
Accept-Encoding: encoding types
# Examples:
Accept-Encoding: compress, gzip
Accept-Encoding:
Accept-Encoding: *
Accept-Encoding: compress;q=0.5, gzip;q=1.0
Accept-Encoding: gzip;q=1.0, identity;q=0.5, *;q=0
Accept-Language
- similar to Accept, but restricts the set of natural languages that are preferred as a response to the request.
1
2
3
4
Accept-Language: language [q=qvalue]
# Multiple languages can be listed separated by commas and the optional qvalue represents an acceptable quality level for non preferred languages on a scale of 0 to 1. Following is an example:
Accept-Language: da, en-gb;q=0.8, en;q=0.7
Authorization 后接encode的验证信息
- consists of credentials containing the
authentication information of the user agentfor therealmof the resource being requested.
1
2
3
4
5
Authorization : credentials
# The HTTP/1.0 specification defines the BASIC authorization scheme, where the authorization parameter is the string of username:password encoded in base 64.
Authorization: BASIC Z3Vlc3Q6Z3Vlc3QxMjM=
# The value decodes into is guest:guest123 where guest is user ID and guest123 is the password.
Cookie
- contains a name/value pair of information stored for that URL.
1
2
3
4
Cookie: name=value
Multiple cookies can be specified separated by semicolons as follows:
Cookie: name1=value1;name2=value2;name3=value3
Expect 用户要求的server行动
- indicate that a
particular set of server behaviors is required by the client.
1
2
3
Expect : 100-continue | expectation-extension
# If a server receives a request containing an Expect field that includes an expectation-extension that it does not support,
# it must respond with a 417 (Expectation Failed) status.
From
- contains an Internet e-mail address for the human user who controls the requesting user agent.
1
2
From: webmaster@w3.org
# This header field may be used for logging purposes and as a means for identifying the source of invalid or unwanted requests.
Host
- to specify the Internet host and the port number of the resource being requested.
1
2
3
4
5
6
Host : "Host" ":" host [ ":" port ] ;
# A host without any trailing port information implies the default port, which is 80.
# request on the origin server for https://www.w3.org/pub/WWW/ would be:
GET /pub/WWW/ HTTP/1.1
Host: www.w3.org
If-Match
- used with a method to make it conditional.
- This header
requests the server to perform the requested method - only if the
given value in this tagmatches thegiven entity tags represented by ETag. - If none of the entity tags match, or if “*” is given and no current entity exists
- the server must not perform the requested method, and must return a
412 (Precondition Failed) response.
1
2
3
4
5
6
If-Match : entity-tag
# An asterisk (*) matches any entity, and the transaction continues only if the entity exists.
If-Match: "xyzzy"
If-Match: "xyzzy", "r2d2xxxx", "c3piozzzz"
If-Match: *
If-Modified-Since
- used with a method to make it conditional.
- If the requested URL
has not been modified since the timespecified in this field- an entity will not be returned from the server;
- instead, a
304 (not modified) responsewill be returned without any message-body. - If none of the entity tags match, or if “*” is given and no current entity exists, the server must not perform the requested method, and must return a
412 (Precondition Failed) response.
1
2
3
4
If-Modified-Since : HTTP-date
# An example of the field is:
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT
If-None-Match
- used with a method to make it conditional.
- This header requests the server to perform the requested method only if none of the
given value in this tagmatches thegiven entity tags represented by ETag.
1
2
3
4
5
6
If-None-Match : entity-tag
# An asterisk (*) matches any entity, and the transaction continues only if the entity does not exist.
If-None-Match: "xyzzy"
If-None-Match: "xyzzy", "r2d2xxxx", "c3piozzzz"
If-None-Match: *
If-Range 时间 本日部分更新/全新一日更新
- can be used with a conditional
GETto- request
only the portion of the entity that is missing, if it has not been changed, the entire entityif it has been changed.
- request
1
2
3
4
5
If-Range : entity-tag | HTTP-date
# Either an entity tag or a date can be used to identify the partial entity already received. For example:
If-Range: Sat, 29 Oct 1994 19:43:31 GMT
# Here if the document has not been modified since the given date, the server returns the byte range given by the Range header, otherwise it returns all of the new document.
If-Unmodified-Since 如果在此时间前无修改的话
- used with a method to make it conditional.
- If the requested resource has not been modified since the time, the server should perform the requested operation
- as if the If-Unmodified-Since header were not present.
1
2
3
4
5
If-Unmodified-Since : HTTP-date
# If the requested resource has not been modified since the time specified in this field, the server should perform the requested operation as if the If-Unmodified-Since header were not present.
If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT
If the request results in anything other than a 2xx or 412 status, the If-Unmodified-Since header should be ignored.
Max-Forwards 最大跳跃数
- provides a mechanism with the
TRACEandOPTIONSmethods - limit the
number of proxies or gateways that can forwardthe request to the next inbound server. - This is useful for debugging with the
TRACEmethod, avoiding infinite loops.
1
2
3
4
Max-Forwards : 5
# The Max-Forwards header field may be ignored for all other methods defined in the HTTP specification.
# - The Max-Forwards value is a decimal integer
# - indicating `the remaining number of times` this request message may be forwarded.
Proxy-Authorization 认证信息
allows the client to identify itself/user to a proxy which requires authentication.
1
2
Proxy-Authorization : credentials
# The Proxy-Authorization field value consists of credentials containing the authentication information of the user agent for the proxy and/or realm of the resource being requested.
Range 取信息范围byte
- specifies the
partial range(s) of the content requested from the document.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Range: bytes-unit= [first-byte-pos] - [last-byte-pos]
# The first-byte-pos: the first byte in a range.
# The last-byte-pos: the byte-offset of the last byte in the range;
# the byte positions specified are inclusive.
# can specify a byte-unit as bytes.
# Byte offsets start at zero.
# - The first 500 bytes
Range: bytes=0-499
# - The second 500 bytes
Range: bytes=500-999
# - The final 500 bytes
Range: bytes=-500
# - The first and last bytes only
Range: bytes=0-0,-1
# Multiple ranges can be listed, separated by commas.
# If the first digit in the comma-separated byte range(s) is missing, the range is assumed to count from the end of the document.
# If the second digit is missing, the range is byte n to the end of the document.
Referer 来自何网址的请求
- allows the client to specify the URI of the resource
from which the URL has been requested.
1
2
3
4
Referer : absoluteURI | relativeURI
Referer: https://www.tutorialspoint.org/ http/index.htm
# If the field value is a relative URI, it should be interpreted relative to the Request-URI.
TE
- indicates
what extension transfer-coding it is willing to acceptin the response and whether or not it is willing to accepttrailerfields in a chunked transfer-coding.
1
2
3
4
5
6
7
8
TE : t-codings
# The presence of the keyword "trailers" indicates that the client is willing to accept trailer fields in a chunked transfer-coding and it is specified either of the ways
TE: trailers, deflate;q=0.5
TE: deflate
TE:
# If the TE field-value is empty or if no TE field is present, then only transfer-coding is chunked.
# A message with no transfer-coding is always acceptable.
User-Agent 阅览器信息
- contains
information about the user agentoriginating the request.
1
2
3
4
# The general syntax:
User-Agent : product | comment
User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT)
Server Response Headers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
<!-- an HTTP response message displaying error condition when the web server could not find the requested page: -->
- HTTP/1.1 `200` OK
- `Date`: Mon, 27 Jul 2009 12:28:53 GMT
- `Server`: Apache/2.2.14 (Win32)
- `Last-Modified`: Wed, 22 Jul 2009 19:15:56 GMT
- `Content-Length`: 88
- `Content-Type`: text/html
- `Connection`: Closed
- <html>
- <body>
- <h1>Hello, World!</h1>
- </body>
- </html>
<!-- an HTTP response message displaying error condition when the web server could not find the requested page: -->
HTTP/1.1 404 Not Found
Date: Sun, 18 Oct 2012 10:36:20 GMT
Server: Apache/2.2.14 (Win32)
Content-Length: 230
Content-Type: text/html; charset=iso-8859-1
Connection: Closed
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html>
<head>
<title>404 Not Found</title>
</head>
<body>
...
</body>
</html>
<!-- HTTP response message showing error condition when the web server encountered a wrong HTTP version in the given HTTP request: -->
HTTP/1.1 400 Bad Request
Date: Sun, 18 Oct 2012 10:36:20 GMT
Server: Apache/2.2.14 (Win32)
Content-Length: 230
Content-Type: text/html; charset=iso-8859-1
Connection: Closed
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html>
<head>
<title>400 Bad Request</title>
</head>
<body>
...
</body>
</html>
Accept-Ranges
- allows the server to indicate its acceptance of range requests for a resource.
1
2
3
4
5
6
7
8
9
# The general syntax is:
Accept-Ranges : range-unit | none
# For example a server that accepts byte-range requests may send:
Accept-Ranges: bytes
# Servers that do not accept any kind of range request for a resource may send:
Accept-Ranges: none
# This will advise the client not to attempt a range request.
Age 有cache就需要这个
- conveys the sender’s estimate of the amount of time since the response (or its revalidation) was generated at the origin server.
- An HTTP/1.1 server that
includes a cachemust include an Age header field in every response generated from its own cache.
1
2
3
4
5
# The general syntax is:
Age : delta-seconds
# Age values are non-negative decimal integers, representing time in seconds.
Age: 1030
ETag
- provides the current value of the entity tag for the requested variant.
1
2
3
4
5
6
# The general syntax is:
ETag : entity-tag
ETag: "xyzzy"
ETag: W/"xyzzy"
ETag: ""
Location redirect用户去其他网址
redirect the recipient to a locationother than the Request-URI for completion.
1
2
3
4
5
# The general syntax is:
Location : absoluteURI
Location: https://www.tutorialspoint.org/ http/index.htm
# The Content-Location header field differs from Location in that the Content-Location identifies the original location of the entity enclosed in the request.
Proxy-Authenticate 跟407一起发送
- must be included as a part of a
407 (Proxy Authentication Required) response.
1
2
# The general syntax is:
Proxy-Authenticate : challenge
Retry-After 跟503一起 多久后service就会失效
- can be used with a
503 (Service Unavailable) response - to indicate
how long the service is expected to be unavailableto the requesting client.
1
2
3
4
5
6
# The general syntax is:
Retry-After : HTTP-date | delta-seconds
Retry-After: Fri, 31 Dec 1999 23:59:59 GMT
Retry-After: 120
# In the latter example, the delay is 2 minutes.
Server
- contains information about the software used by the origin server to handle the request.
1
2
3
4
5
# The general syntax is:
Server : product | comment
Server: Apache/2.2.14 (Win32)
# If the response is being forwarded through a proxy, the proxy application must not modify the Server response-header.
Set-Cookie cookie的一些特性
- contains a
name/value pair of information to retain for this URL.
1
2
3
4
5
# The general syntax is:
Set-Cookie: NAME=VALUE; OPTIONS
# Set-Cookie response header comprises the token Set-Cookie, followed by a comma-separated list of one or more cookies.
Set-Cookie: name1=value1,name2=value2; Expires=Wed, 09 Jun 2021 10:18:14 GMT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
1 Comment=comment
# This option can be used to specify any comment associated with the cookie.
2 Domain=domain
# The Domain attribute specifies the domain for which the cookie is valid.
3 Expires=Date-time
# The date the cookie will expire. If it is blank, the cookie will expire when the visitor quits the browser.
4 Path=path
# The Path attribute specifies the subset of URLs to which this cookie applies.
5 Secure
# It instructs the user agent to return the cookie only under a secure connection.
Vary 有些header根据网站不同会不同
- specifies that the entity has multiple sources
- and may therefore vary according to the specified list of request header(s).
1
2
3
4
5
Vary : field-name
# Here field names are case-insensitive.
Vary: Accept-Language, Accept-Encoding
# can specify multiple headers separated by commas and a value of asterisk "*" signals that unspecified parameters are not limited to the request-headers.
WWW-Authenticate 跟401一期 用来用户认证
- must be included in
401 (Unauthorized) response messages. - The field value consists of at least one challenge that indicates
the authentication scheme(s) and parameters applicable to the Request-URI.
1
2
3
4
5
# The general syntax is:
WWW-Authenticate : challenge
# WWW- Authenticate field value might contain more than one challenge, or if more than one WWW-Authenticate header field is provided, the contents of a challenge itself can contain a comma-separated list of authentication parameters
WWW-Authenticate: BASIC realm="Admin"
# Entity Headers
entity-header field
Allow 网页支持的http method
- lists the set of
methods supported by the resourceidentified by the Request-URI.
1
2
3
4
5
6
# The general syntax is:
Allow : Method
Allow: GET, HEAD, PUT
# can specify multiple methods separated by commas.
# This field cannot prevent a client from trying other methods.
Content-Encoding 回复内容的格式
- used as a modifier to the media-type.
- If the content-coding of an entity in a request message is not acceptable to the origin server, the server should respond with a status code of
415 (Unsupported Media Type).
1
2
3
4
5
# The general syntax is:
Content-Encoding : content-coding
# The content-coding is a characteristic of the entity identified by the Request-URI.
Content-Encoding: gzip
Content-Language
- describes the natural language(s) of the intended audience for the enclosed entity.
- The primary purpose of Content-Language is to allow a user to identify and differentiate entities according to the user’s own preferred language.
1
2
3
4
5
# Following is the general syntax:
Content-Language : language-tag
# Multiple languages may be listed for content that is intended for multiple audiences
Content-Language: mi, en
Content-Length
- indicates the
size of the entity-body, in decimal number of OCTETs, sent to the recipient - or, in the case of the HEAD method, the size of the entity-body that would have been sent, had the request been a GET.
1
2
3
4
5
6
# The general syntax is:
Content-Length : DIGITS
Content-Length: 3495
Any Content-Length greater than or equal to zero is a valid value.
Content-Location entity-header field
- supply the resource location for the entity enclosed in the message when that entity is accessible from a location separate from the requested resource’s URI.
1
2
3
4
5
6
# The general syntax is:
Content-Location: absoluteURI | relativeURI
Content-Location: https://www.tutorialspoint.org/ http/index.htm
# The value of Content-Location also defines the base URI for the entity.
Content-MD5 entity-header field
- to supply an MD5 digest of the entity
- checking the integrity of the message upon receipt.
1
2
3
4
5
6
# The general syntax is:
Content-MD5 : md5-digest using base64 of 128 bit MD5 digest as per RFC 1864
Content-MD5 : 8c2d46911f3f5a326455f0ed7a8ed3b3
# The MD5 digest is computed based on the content of the entity-body, including any content-coding that has been applied, but not including any transfer-encoding applied to the message-body.
Content-Range entity-header field
- sent with a partial entity-body to specify where in the
full entity-bodythe partial bodyshould be applied.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# The general syntax is:
Content-Range : bytes-unit [first-byte-pos]-[last-byte-pos]
# Examples of byte-content-range-spec values, assuming that the entity contains a total of 1234 bytes:
# - The first 500 bytes:
Content-Range : bytes 0-499/1234
# - The second 500 bytes:
Content-Range : bytes 500-999/1234
# - All except for the first 500 bytes:
Content-Range : bytes 500-1233/1234
# - The last 500 bytes:
Content-Range : bytes 734-1233/1234
# When an HTTP message includes the content of a single range, this content is transmitted with a Content-Range header,
# a Content-Length header showing the number of bytes actually transferred.
HTTP/1.1 206 Partial content
Date: Wed, 15 Nov 1995 06:25:24 GMT
Last-Modified: Wed, 15 Nov 1995 04:58:08 GMT
Content-Range: bytes 21010-47021/47022
Content-Length: 26012
Content-Type: image/gif
Content-Type entity-header field
- indicates
the media typeof the entity-body sent to the recipient - or, in the case of the HEAD method, the media type that would have been sent, had the request been a GET.
1
2
3
4
# The general syntax is:
Content-Type : media-type
Content-Type: text/html; charset=ISO-8859-4
Expires entity-header field
- gives the date/time after which the response is considered stale.
1
2
3
4
# The general syntax is:
Expires : HTTP-date
Expires: Thu, 01 Dec 1994 16:00:00 GMT
Last-Modified entity-header field
- indicates the date and time at which the origin server believes the variant was last modified.
1
2
3
4
# The general syntax is:
Last-Modified: HTTP-date
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
.
Comments powered by Disqus.