GCP - PubSub
GCP - PubSub
subscriptions
To receive messages published to a
topic, you must create asubscriptionto that topic.Only messages published to the topic after the subscription is created are available to subscriber clients.
The
subscriber clientreceives and processes the messages published to the topic.A topic can have multiple subscriptions, but a given subscription belongs to a single topic.
The topic retention feature
- it lets a subscription attached to a topic to seek back in time and replay previously published messages.
Subscription workflow
After a message is sent to a subscriber, the subscriber must
acknowledgethe message.- If a message is sent out for delivery and a subscriber is yet to acknowledge it, the message is called
outstanding.- Pub/Sub repeatedly attempts to deliver any message that is not yet acknowledged.
- However, Pub/Sub tries not to deliver an outstanding message to any other subscriber on the same subscription.
- The subscriber has a configurable, limited amount of time, known as the
ackDeadline, to acknowledge the outstanding message.- After the deadline passes, the message is no longer considered outstanding, and Pub/Sub attempts to redeliver the message.
Types of subscriptions
you must specify the
type of message deliverywhen create a subscription,You can update the type of subscription at any time after you create it.
Pub/Sub offers 3 types of message delivery that corresponds to the following the types of subscriptions.
- Pull subscription
- Use case
- Large volume of messages (GBs per second).
- Efficiency and throughput of message processing is critical.
- Environments where a public HTTPS endpoint with a non-self-signed SSL certificate is not feasible to set up.
- Endpoints
- Any device on the internet that has authorized credentials is able to call the
Pub/Sub API.
- Any device on the internet that has authorized credentials is able to call the
- Load balancing
- Multiple subscribers can make pull calls to the same “shared” subscription.
- Each subscriber receives a subset of the messages.
- Configuration
- No configuration is necessary.
- Flow control
- The subscriber client controls the rate of delivery.
- The subscriber can dynamically modify the acknowledgment deadline, allowing message processing to be arbitrarily long.
- Efficiency and throughput
- Achieves high throughput at low CPU and bandwidth by allowing batched delivery and acknowledgments as well as massively parallel consumption.
- May be inefficient if aggressive polling is used to minimize message delivery time.
- Use case
- Push subscription
- Use case
- Multiple topics that must be processed by the same webhook.
- Cloud Run or App Engine Standard and Cloud Functions subscribers.
- Environments where Google Cloud dependencies (such as credentials and the client library) are not feasible to set up.
- Endpoints
- An HTTPS server with non-self-signed certificate accessible on the public web.
- The receiving endpoint may be decoupled from the Pub/Sub subscription, so that messages from multiple subscriptions may be sent to a single endpoint.
- Load balancing
- The push endpoint can be a load balancer.
- Configuration
- No configuration is necessary for Cloud Run or App Engine apps in the same project as the subscriber.
- Verification of push endpoints is not required in the Google Cloud console.
- Endpoints must be reachable using DNS names and have SSL certificates installed.
- Flow control
- The Pub/Sub server automatically implements flow control.
- There’s no need to handle message flow at the client side.
- However, it’s possible to indicate that the client cannot handle the current message load by passing back an HTTP error.
- Efficiency and throughput
- Delivers one message per request and limits the maximum number of outstanding messages.
- Use case
- BigQuery subscription
- Use case
- Large volume of messages that can scale up to multiple millions of messages per second.
- Messages are directly sent to BigQuery without any additional processing.
- Endpoints
- A BigQuery table.
- Load balancing
- The Pub/Sub service automatically balances the load.
- Configuration
- A BigQuery table must exist for the topic subscription
- Flow control
- The Pub/Sub server automatically implements flow control in order to optimize writing messages to BigQuery.
- Efficiency and throughput
- Scalability is dynamically handled by Pub/Sub servers.
- Use case
Default subscription properties
By default, Pub/Sub offers
at-least-oncedelivery withno ordering guaranteeson all subscription types.- Alternatively, if messages have the same ordering key and are in the same region, you can enable
message ordering.- After you set the message ordering property, the Pub/Sub service delivers messages with the same ordering key and in the order that the Pub/Sub service receives the messages.
- Pub/Sub also supports
exactly-oncedelivery.- In general, Pub/Sub delivers each message once and in the order in which it was published.
- However, messages may sometimes be delivered out of order or more than once. Pub/Sub might redeliver a message even after an acknowledgement request for the message returns successfully.
- This redelivery can be caused by issues such as server-side restarts or client-side issues.
- Thus, although rare, any message can be redelivered at any time.
- Accommodating
more-than-oncedelivery requires the subscriber to be idempotent when processing messages.
Subscription expiry
By default, subscriptions expire after 31 days of subscriber inactivity or if there are no updates made to the subscription. Examples of subscriber activities include open connections, active pulls, or successful pushes. If Pub/Sub detects subscriber activity or an update to the subscription properties, the subscription deletion clock restarts. Using subscription expiration policies, you can configure the inactivity duration or make the subscription persistent regardless of activity. You can also delete a subscription manually.
Although you can create a new subscription with the same name as a deleted one, the new subscription has no relationship to the old one. Even if the deleted subscription had many unacknowledged messages, a new subscription created with the same name would have no backlog (no messages waiting for delivery) at the time it’s created.
Pull subscription
Required roles and permissions
- grant the
Pub/Sub Editor (roles/pubsub.editor)IAM role on the topic or project.- This predefined role contains the permissions required to create pull subscriptions and manage them.
- can configure access control at the project level and at the individual resource level.
- can create a subscription in one project and attach it to a topic located in a different project. n
Pull subscription
In a pull subscription, a subscriber client requests messages from the Pub/Sub server.
The pull mode
- can use one of the two service APIs,
PullorStreamingPull. - can select a
Google-provided high-level client library, or alow-level auto-generated client library - can choose between
asynchronousandsynchronousmessage processing. - Note: For most use cases, we recommend the Google-provided high-level client library + StreamingPull API + asynchronous message processing.
- can use one of the two service APIs,
Pull subscription workflow
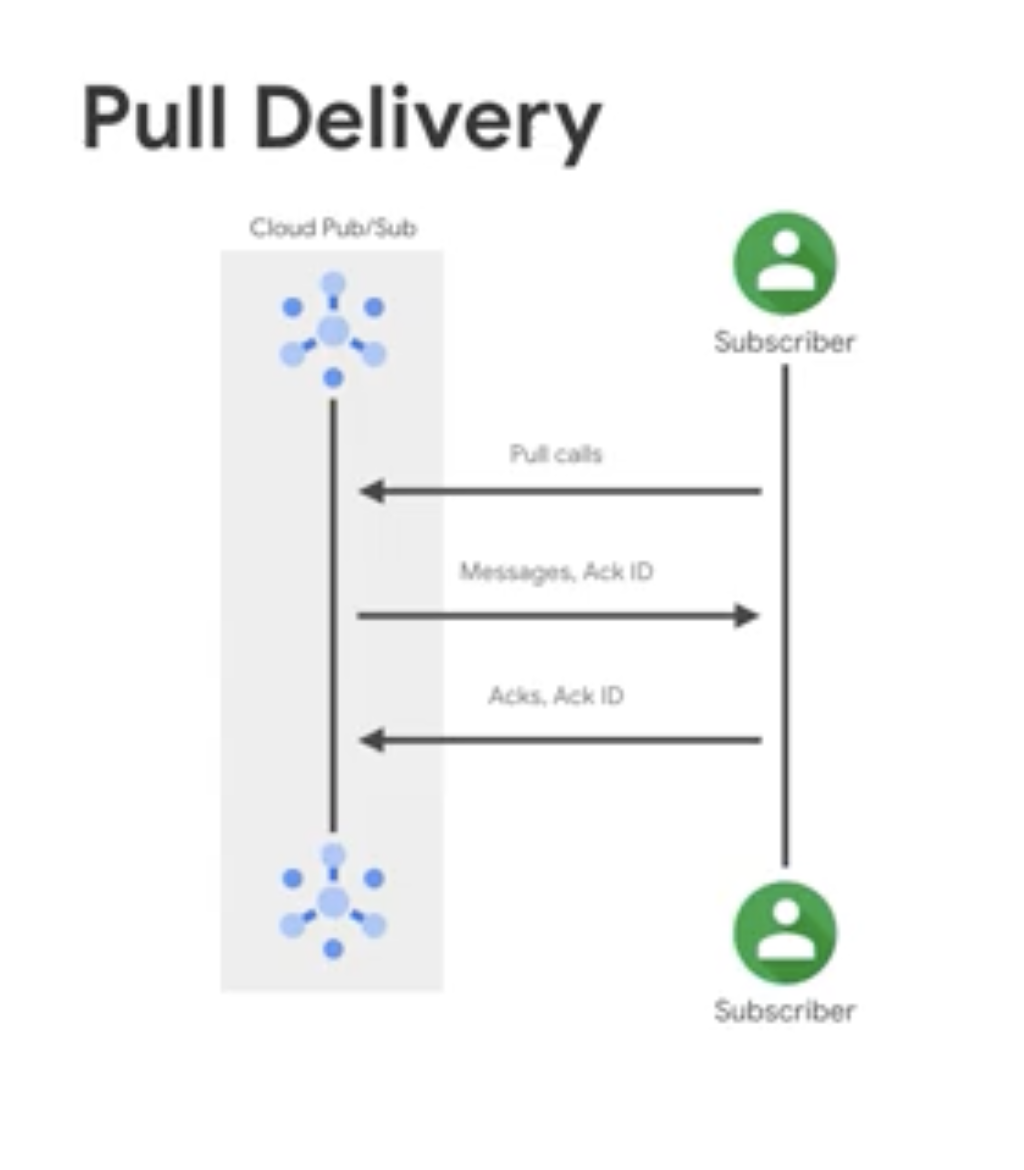
For a pull subscription, the
subscriber client initiates requeststo a Pub/Sub server to retrieve messages.- The subscriber client uses one of the following APIs:
- REST PullAPI
- RPC PullRequest API
- REST StreamingPullRequest API
- RPC StreamingPullRequest API
- library
Google Cloud-provided high-level client library- Most subscriber clients don’t make these requests directly, they rely on the
Google Cloud-provided high-level client library - it performs
streaming pull requests internallyand delivers messagesasynchronously.
- Most subscriber clients don’t make these requests directly, they rely on the
low-level and automatically generated gRPC library- For subscriber client that needs greater control over how messages are pulled,
- Pub/Sub uses a
low-level and automatically generated gRPC libraryto makes pull or streaming pull requests directly. - These requests can be synchronous or asynchronous.
The following two images show the workflow between a subscriber client and a pull subscription.
- The subscriber client explicitly calls the pull method (
PullRequest), which requests messages for delivery. - The Pub/Sub server responds
PullResponsewith zero or more messages and acknowledgment IDs.- A response with zero messages or with an error does not necessarily indicate that there are no messages available to receive.
- The subscriber client explicitly calls the acknowledge method.
- The client uses the returned acknowledgment ID to acknowledge that the message is processed and need not be delivered again.
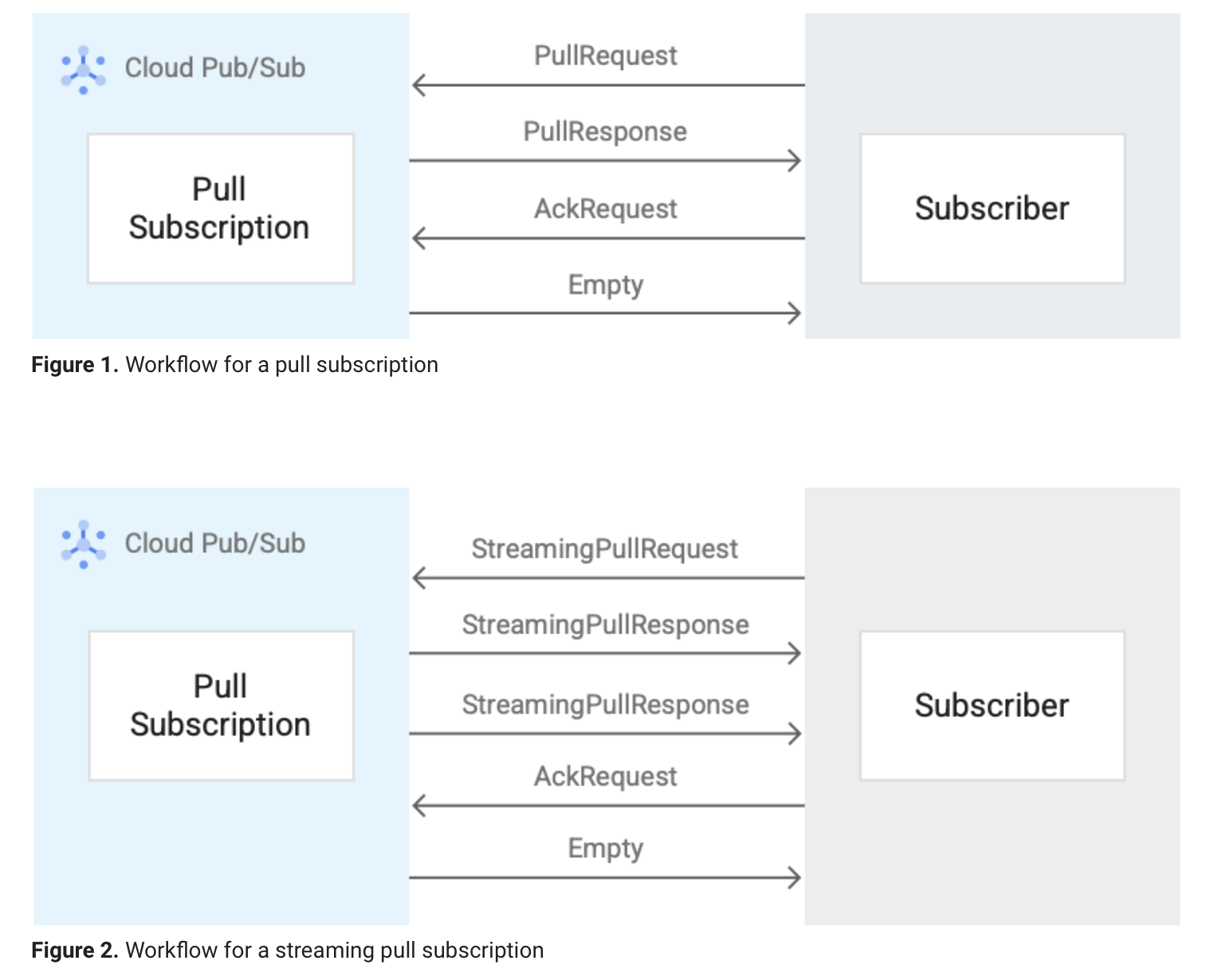
APIs
- For a single
StreamingPullRequestrequest, a subscriber client can have multiple responses returned due to the open connection.- For a single
PullRequestrequest,only one response is returned for each pull request.
The Pub/Sub pull subscription can use one of the following two APIs for retrieving messages:
- Pull
StreamingPull
- Use unary Acknowledge and ModifyAckDeadline RPCs when you receive messages using these APIs.
StreamingPull API
Where possible, the Pub/Sub client libraries use StreamingPull for maximum throughput and lowest latency.
The StreamingPull API relies on a persistent bidirectional connection to receive multiple messages as they become available.
Messages are sent to the connection when they are available.
The StreamingPull API thus minimizes latency and maximizes throughput for messages.
workflow:
The client sends a request to the server to establish a connection.
- the server
- If the connection quota is exceeded, the server returns a resource exhausted error. The client library retries the out-of-quota errors automatically.
- If there is no error or the connection quota is available again, the server continuously sends messages to the connected client.
- If or when the throughput quota is exceeded, the server stops sending messages. However, the connection is not broken. Whenever there’s sufficient throughput quota available again, the stream resumes.
The client or the server eventually closes the connection.
- The StreamingPull API keeps an open connection. The Pub/Sub servers recurrently close the connection after a time period to avoid a long-running sticky connection. The client library automatically reopens a StreamingPull connection.
Note:
- The PHP client library does not support the StreamingPull API.
- Read more about the StreamingPull REST methods: StreamingPullRequest and StreamingPullResponse.
- Read more about the StreamingPull RPC methods: StreamingPullRequest and StreamingPullResponse.
Pull API
This API is a traditional unary RPC that is based on a request and response model.
A single pull response corresponds to a single pull request.
Using the Pull API does not guarantee low latency and a high throughput of messages.
- To achieve high throughput and low latency with the Pull API, you must have multiple simultaneous outstanding requests.
- New requests are created when old requests receive a response.
- Architecting such a solution is error-prone and hard to maintain.
- recommend to use the StreamingPull API for such use cases.
Use the Pull API instead of the StreamingPull API only if you require strict control over the following:
- The number of messages that the subscriber client can process
- The client memory and resources
- You can also use this API when your subscriber is a proxy between Pub/Sub and another service that operates in a more pull-oriented way.
workflow:
The client sends a request to the server for messages.
- the server
- If the throughput quota is exceeded, the server returns a resource exhausted error.
- If there is no error or the throughput quota is available again, the server replies with zero or more messages and acknowledgment IDs.
- When using the unary Pull API, a response with zero messages or with an error does not necessarily indicate that there are no messages available to receive.
Note: Read more about the Pull REST methods: Method: projects.subscriptions.pull. Read more about the Pull RPC methods: PullRequest and PullResponse.
message processing modes
Choose one of the following pull modes for your subscriber clients.
Asynchronous pull mode
- decouples the receiving of messages from the processing of messages in a subscriber client.
- This mode is the default for most subscriber clients.
- can use the StreamingPull API or unary Pull API.
- can use the high-level client library or low-level auto-generated client library.
Synchronous pull mode
- the receiving and processing of messages occur in sequence and are not decoupled from each other.
Hence, similar to StreamingPull versus unary Pull APIs, asynchronous processing offers lower latency and higher throughput than synchronous processing.
- Use synchronous pull mode only for applications where low latency and high throughput are not the most important factors as compared to some other requirements.
- For example
- an application might be limited to using only the synchronous programming model.
- an application with resource constraints might require more exact control over memory, network, or CPU.
- In such cases, use synchronous mode with the unary Pull API.
client libraries
Pub/Sub offers a high-level and a low-level auto-generated client library.
High-level Pub/Sub client library
- recommended for cases where you require high throughput and low latency with minimal operational overhead and processing cost.
By default, the high-level client library uses the StreamingPull API.
- it provides options for controlling the acknowledgment deadlines by using lease management.
- These options are more granular than when you configure the acknowledgment deadlines by using the console or the CLI at the subscription level.
it implements support for features such as ordered delivery, exactly-once delivery, and flow control.
- We recommend using asynchronous pull and the StreamingPull API with the high-level client library.
- Not all languages that are supported for Google Cloud also support the Pull API in the high-level client library.
Low-level auto-generated Pub/Sub client library
available for cases where you must use the Pull API directly.
an auto-generated gRPC library and comes into play when you use the service APIs directly.
You can use synchronous or asynchronous processing with the low-level auto-generated client library.
You must manually code features such as ordered delivery, exactly-once delivery, flow control, and lease management when you use the low-level auto-generated client library.
You can use the synchronous processing model when you use the low-level auto-generated client library for all supported languages. You might use the low-level auto-generated client library and synchronous pull in cases where using the Pull API directly makes sense. For example, you might have existing application logic that relies on this model.
Pull subscription properties
When you configure a pull subscription, you can specify the following properties.
- Common properties
- the common subscription properties that you can set across all subscriptions.
- https://cloud.google.com/pubsub/docs/subscription-properties
Exactly-once delivery
Exactly-once delivery.- If set, Pub/Sub fulfills exactly-once delivery guarantees.
- If unspecified, the subscription supports at-least-once delivery for each message.
pull subscription Creation
1
2
3
4
gcloud pubsub subscriptions create SUBSCRIPTION_ID --topic=TOPIC_ID
# Replace the following:
# SUBSCRIPTION_ID: The name or ID of the new pull subscription.
# TOPIC_ID: The name or ID of the topic.
- StreamingPull and high-level client library code samples
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from concurrent.futures import TimeoutError
from google.cloud import pubsub_v1
# TODO(developer)
# project_id = "your-project-id"
# subscription_id = "your-subscription-id"
# Number of seconds the subscriber should listen for messages
# timeout = 5.0
subscriber = pubsub_v1.SubscriberClient()
# The `subscription_path` method creates a fully qualified identifier
# in the form `projects/{project_id}/subscriptions/{subscription_id}`
subscription_path = subscriber.subscription_path(project_id, subscription_id)
def callback(message: pubsub_v1.subscriber.message.Message) -> None:
print(f"Received {message}.")
message.ack()
streaming_pull_future = subscriber.subscribe(
subscription_path, callback=callback)
print(f"Listening for messages on {subscription_path}..\n")
# Wrap subscriber in a 'with' block to automatically call close() when done.
with subscriber:
try:
# When `timeout` is not set, result() will block indefinitely,
# unless an exception is encountered first.
streaming_pull_future.result(timeout=timeout)
except TimeoutError:
streaming_pull_future.cancel() # Trigger the shutdown.
streaming_pull_future.result() # Block until the shutdown is complete.
- Retrieve custom attributes using the high-level client library
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project_id, subscription_id)
def callback(message: pubsub_v1.subscriber.message.Message) -> None:
print(f"Received {message.data!r}.")
if message.attributes:
print("Attributes:")
for key in message.attributes:
value = message.attributes.get(key)
print(f"{key}: {value}")
message.ack()
streaming_pull_future = subscriber.subscribe(subscription_path, callback=callback)
print(f"Listening for messages on {subscription_path}..\n")
# Wrap subscriber in a 'with' block to automatically call close() when done.
with subscriber:
try:
# When `timeout` is not set, result() will block indefinitely,
# unless an exception is encountered first.
streaming_pull_future.result(timeout=timeout)
except TimeoutError:
streaming_pull_future.cancel() # Trigger the shutdown.
streaming_pull_future.result() # Block until the shutdown is complete.
- Handle errors using the high-level client library
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 1
streaming_pull_future = subscriber.subscribe(subscription_path, callback=callback)
# Wrap subscriber in a 'with' block to automatically call close() when done.
with subscriber:
# When `timeout` is not set, result() will block indefinitely,
# unless an exception is encountered first.
try:
streaming_pull_future.result(timeout=timeout)
except Exception as e:
print(
f"Listening for messages on {subscription_path} threw an exception: {e}."
)
streaming_pull_future.cancel() # Trigger the shutdown.
streaming_pull_future.result() # Block until the shutdown is complete.
# 2
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project_id, subscription_id)
NUM_MESSAGES = 3
# Wrap the subscriber in a 'with' block to automatically call close() to
# close the underlying gRPC channel when done.
with subscriber:
# The subscriber pulls a specific number of messages. The actual
# number of messages pulled may be smaller than max_messages.
response = subscriber.pull(
request={"subscription": subscription_path, "max_messages": NUM_MESSAGES},
retry=retry.Retry(deadline=300),
)
if len(response.received_messages) == 0:
return
ack_ids = []
for received_message in response.received_messages:
print(f"Received: {received_message.message.data}.")
ack_ids.append(received_message.ack_id)
# Acknowledges the received messages so they will not be sent again.
subscriber.acknowledge(
request={"subscription": subscription_path, "ack_ids": ack_ids}
)
print(
f"Received and acknowledged {len(response.received_messages)} messages from {subscription_path}."
)
Push subscriptions
In push delivery, Pub/Sub initiates requests to your subscriber application to deliver messages.
Messages are delivered to a publicly addressable server or a webhook, such as an HTTPS POST request.
it minimize dependencies on Pub/Sub-specific client libraries and authentication mechanisms. They also work well with serverless and autoscaling service technologies, such as Cloud Functions, Cloud Run, and Google Kubernetes Engine.
Push subscription workflow
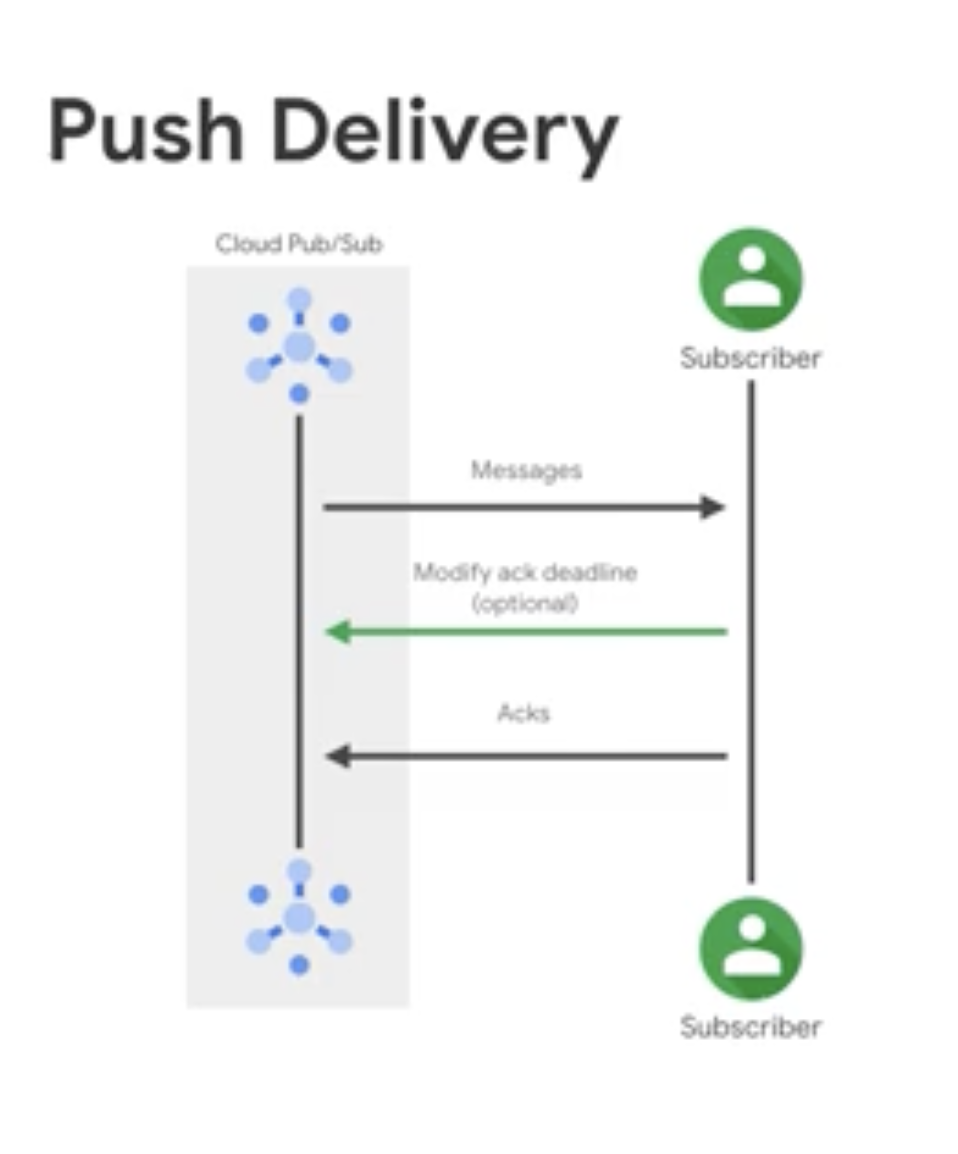
- Pub/Sub server initiates a request to your subscriber client to deliver messages.
the workflow between a subscriber client and a push subscription.
The Pub/Sub server sends each message as an HTTPS request (
PushRequest) to the subscriber client at a pre-configured endpoint.- The endpoint acknowledges the message (
PushResponse) by returning an HTTP success status code.- A non-success response indicates that Pub/Sub must resend the messages.
- Pub/Sub dynamically adjusts the rate of push requests based on the rate at which it receives success responses.
How push endpoints receive messages
When Pub/Sub delivers a message to a push endpoint, Pub/Sub sends the message in the body of a
POSTrequest.The body of the request is a JSON object and the message data is in the message.data field. The message data is base64-encoded.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# example: the body of a POST request to a push endpoint:
{
"message": {
"attributes": {
"key": "value"
},
"data": "SGVsbG8gQ2xvdWQgUHViL1N1YiEgSGVyZSBpcyBteSBtZXNzYWdlIQ==",
"messageId": "2070443601311540",
"message_id": "2070443601311540",
"publishTime": "2021-02-26T19:13:55.749Z",
"publish_time": "2021-02-26T19:13:55.749Z"
},
"subscription": "projects/myproject/subscriptions/mysubscription"
}
- To receive messages from push subscriptions,
- use a webhook and process the POST requests that Pub/Sub sends to the push endpoint.
- After you receive a push request, return an HTTP status code. To acknowledge the message, return one of the following status codes:
- 102
- 200
- 201
- 202
- 204
- To send a negative acknowledgment for the message, return any other status code. If you send a negative acknowledgment or the acknowledgment deadline expires, Pub/Sub resends the message. You can’t modify the acknowledgment deadline of individual messages that you receive from push subscriptions.
Authentication for push subscriptions
- If a push subscription uses authentication, the Pub/Sub service signs a JWT and sends the JWT in the authorization header of the push request.
Stop and resume message delivery
- To temporarily stop Pub/Sub from sending requests to the push endpoint, change the subscription to pull.
The changeover can take several minutes to take effect.
To resume push delivery, set the URL to a valid endpoint again.
- To permanently stop delivery, delete the subscription.
Push backoff
- If a push subscriber sends too many negative acknowledgments, Pub/Sub might start delivering messages using a push backoff.
- When Pub/Sub uses a push backoff, it stops delivering messages for a predetermined amount of time.
- This time span can range between 100 milliseconds to 60 seconds.
- After the time has elapsed, Pub/Sub starts delivering messages again.
Note: This feature is independent from the subscription retry policy. You can use these two features together to better control the flow of messages. In this case, The total delay is the maximum combined value of both the push backoff value and the retry policy value. If you’re noticing issues with message delivery, double check how your retry policy is interacting with push backoff. Push backoff uses an exponential backoff algorithm to determine the delay Pub/Sub that uses between sending messages. This amount of time is calculated based on the number of negative acknowledgments that push subscribers send.
- For example
- if a push subscriber receives five messages per second and sends one negative acknowledgment per second, Pub/Sub delivers messages approximately every 500 milliseconds.
- if the push subscriber sends five negative acknowledgments per second, Pub/Sub delivers messages every 30 through 60 seconds.
Push backoff can’t be turned on or off. You also can’t modify the values used to calculate the delay.
- Push backoff triggers on the following actions:
- When a negative acknowledgment is received.
- When the acknowledgment deadline of a message expires.
- Push backoff applies to all the messages in a subscription (global).
Delivery rate
Pub/Sub adjusts the number of concurrent push requests using a
slow-startalgorithm.- The maximum allowed number of concurrent push requests is the
push window.- The push window increases on any successful delivery and decreases on any failure.
- The system starts with a small single-digit window size.
- When a subscriber acknowledges messages, the window increases exponentially.
For subscriptions where subscribers acknowledge greater than 99% of messages and average less than one second of push request latency, the push window should expand enough to keep up with any publish throughput.
- The push request latency includes the following:
- The round-trip network latency between Pub/Sub servers and the push endpoint
- The processing time of the subscriber
- After 3,000 outstanding messages per region, the window increases linearly to prevent the push endpoint from receiving too many messages. If the average latency exceeds one second or the subscriber acknowledges less than 99% of requests, the window decreases to the lower limit of 3,000 outstanding messages.
Quotas and limits
- Push subscriptions are subject to a set of quotas and resource limits.
Considerations
VPC Service Controls
For a project protected by VPC Service Controls, note the following limitations for push subscriptions:
- You can only create new push subscriptions for which the push endpoint is set to a Cloud Run service with a default
run.appURL. Custom domains don’t work. - When routing events through Eventarc to Workflows destinations for which the push endpoint is set to a Workflows execution, you can only create new push subscriptions through Eventarc.
- You can’t update existing push subscriptions. These push subscriptions continue to function, although they are not protected by VPC Service Controls.
- Cloud Functions can create a push subscription using an endpoint within a VPC Service Controls perimeter.
Push subscription properties
- Common subscription properties
- Pub/Sub subscription properties are the characteristics of a subscription.
- You can set subscription properties when you create or update a subscription.
- https://cloud.google.com/pubsub/docs/subscription-properties
Endpoints
- Endpoint URL (required).
- A publicly accessible HTTPS address.
- The server for the push endpoint must have a valid SSL certificate signed by a certificate authority.
The Pub/Sub service delivers messages to push endpoints from the same Google Cloud region that the Pub/Sub service stores the messages. The Pub/Sub service delivers messages from the same Google Cloud region on a best-effort basis.
- Pub/Sub no longer requires proof of ownership for push subscription URL domains. If the domain receives unexpected POST requests from Pub/Sub, you can report suspected abuse.
Authentication
Enable authentication.- When enabled, messages delivered by Pub/Sub to the push endpoint include an authorization header to allow the
endpoint to authenticate the request. Automatic authentication and authorization mechanisms are available for App Engine Standard and Cloud Functions endpoints hosted in the same project as the subscription.
- The authentication configuration for an authenticated push subscription consists of a user-managed service account, and the audience parameters that are specified in a
create, patch, or ModifyPushConfig call. You must also grant a special Google-managed service account a specific role
- When enabled, messages delivered by Pub/Sub to the push endpoint include an authorization header to allow the
User-managed service account (required).- The service account associated with the push subscription.
- This account is used as the email claim of the generated JSON Web Token (JWT).
Requirements for the service account:
This service account must be in the same project as the push subscription.
The principal who is creating or modifying the push subscription must have the
iam.serviceAccounts.actAspermission on the service account.- You can either
- grant a role with this permission on the
project, folder, or organizationto allow the caller to impersonate multiple service accounts - or grant a role with this permission on the
service accountto allow the caller to impersonate only this service account.
Audience.- A single, case-insensitive string that the webhook uses to validate the intended audience of this particular token.
Google-managed service account (required).- Pub/Sub automatically creates a service account for you with the format
service-{PROJECT_NUMBER}@gcp-sa-pubsub.iam.gserviceaccount.com. - The service account must be granted the
iam.serviceAccounts.getOpenIdTokenpermission (included in the roles/iam.serviceAccountTokenCreator role) to allow Pub/Sub to create JWT tokens for authenticated push requests.
- Pub/Sub automatically creates a service account for you with the format
BigQuery subscriptions
BigQuery subscription
Without the BigQuery subscription type, you need a pull or push subscription and a subscriber (such as Dataflow) that reads messages and writes them to a BigQuery table. The overhead of running a Dataflow job is not necessary when messages don’t require additional processing before storing them in a BigQuery table; you can use a BigQuery subscription instead.
A BigQuery subscription writes messages to an existing BigQuery table as they are received. You don’t need to configure a separate subscriber client.
An alternative for simple data ingestion pipelines that often use Dataflow to write to BigQuery
- Simple deployment. You can set up a BigQuery subscription through a single workflow in the console, Google Cloud CLI, client library, or Pub/Sub API.
- Offers low costs. Removes the additional cost and latency of similar Pub/Sub pipelines that include Dataflow jobs. This cost optimization is useful for messaging systems that don’t require additional processing before storage. Minimizes monitoring. BigQuery subscriptions are part of the multi-tenant Pub/Sub service and don’t require you to run separate monitoring jobs.
Cloud Architecture Center
Integrating microservices with Pub/Sub and GKE
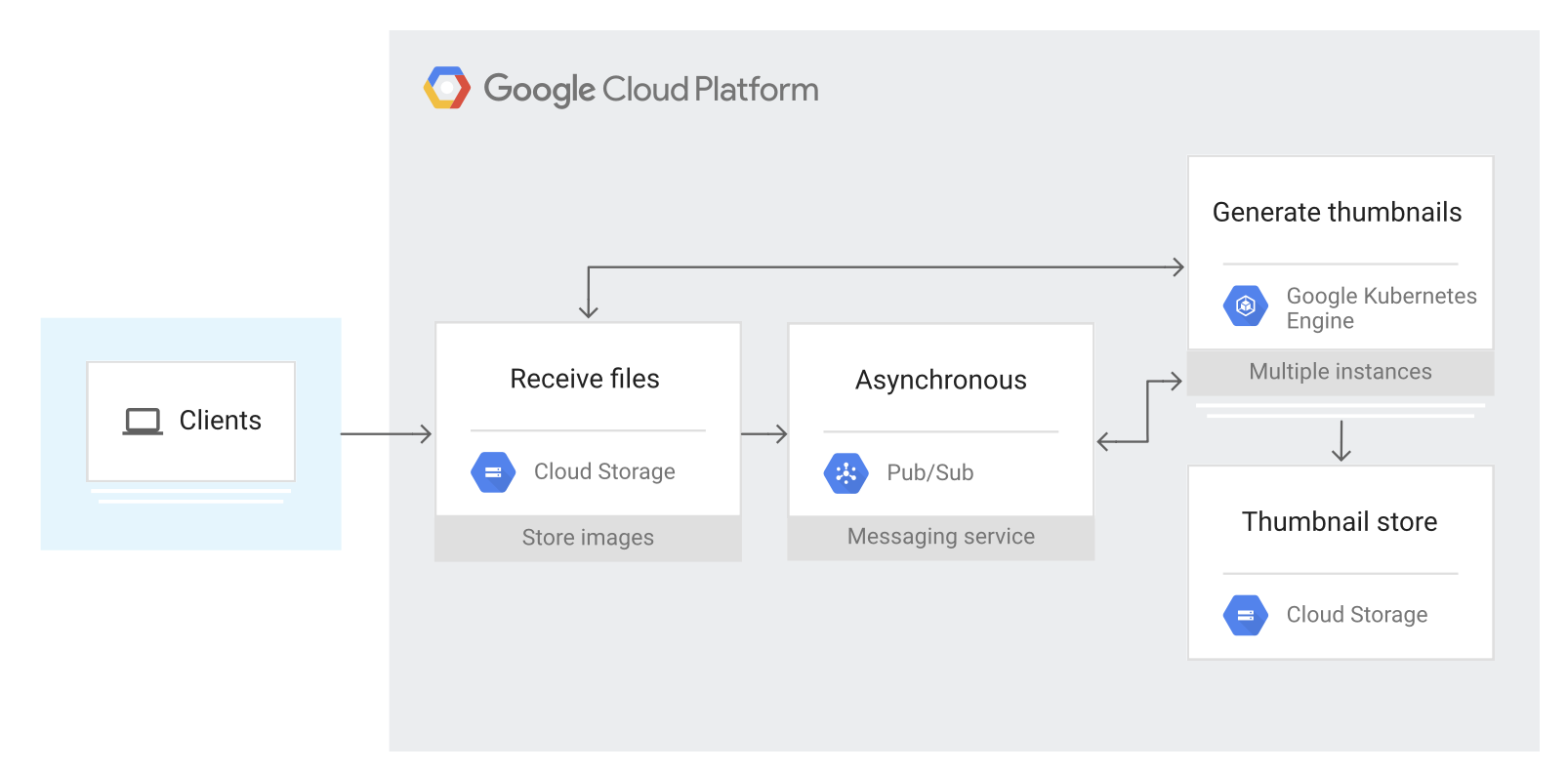
Objectives
- Deploy an example photo album app on GKE.
- Make asynchronous service calls from the app.
- Use Pub/Sub notifications for
Cloud Storage to trigger the appwhen a new file is uploaded to the Cloud Storage bucket. - Use Pub/Sub to perform more tasks without modifying the app.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
# ========== Setting up the environment
gcloud config set project project-id
gcloud config set compute/region region
export REGION=region
gcloud config set compute/zone zone
export ZONE=zone
git clone https://github.com/GoogleCloudPlatform/gke-photoalbum-example
cd gke-photoalbum-example
# ========== Creating a Cloud Storage bucket and uploading the default thumbnail image
# create a Cloud Storage bucket to store the original images and thumbnails:
export PROJECT_ID=$(gcloud config get-value project)
gsutil mb -c regional -l ${REGION} gs://${PROJECT_ID}-photostore
# Upload the default thumbnail file:
gsutil cp ./application/photoalbum/images/default.png \
gs://${PROJECT_ID}-photostore/thumbnails/default.png
# Make the thumbnail file public:
gsutil acl ch -u AllUsers:R \
gs://${PROJECT_ID}-photostore/thumbnails/default.png
# ========== Creating a Cloud SQL instance and a MySQL database
# create the Cloud SQL instance:
gcloud sql instances create photoalbum-db \
--region=${REGION} \
--database-version=MYSQL_5_7
# Retrieve the connection name:
gcloud sql instances describe photoalbum-db \
--format="value(connectionName)"
# Set the password for the root@% MySQL user:
gcloud sql users set-password root \
--host=% \
--instance=photoalbum-db \
--password=password
# Connect to the Cloud SQL instance:
gcloud sql connect photoalbum-db --user=root --quiet
# Create a database called photo_db, where the user is appuser with a password of pas4appuser:
create database photo_db;
grant all privileges on photo_db.* to appuser@"%" \
identified by 'pas4appuser' with grant option;
# create database photo_db;
grant all privileges on photo_db.* to appuser@"%" \
identified by 'pas4appuser' with grant option;
# Confirm the result and exit from MySQL:
show databases;
select user from mysql.user;
exit
# In the output, confirm that the photo_db database and the appuser user are created:
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| photo_db |
| sys |
+--------------------+
5 rows in set (0.16 sec)
MySQL [(none)]> select user from mysql.user;
+-----------+
| user |
+-----------+
| appuser |
| root |
| mysql.sys |
+-----------+
3 rows in set (0.16 sec)
MySQL [(none)]> exit
Bye
# ========== Creating a Pub/Sub topic and a subscription
# create a Pub/Sub topic called thumbnail-service:
gcloud pubsub topics create thumbnail-service
# The photo album app sends requests to the thumbnail generation service by publishing a message on the thumbnail-service topic.
# Create a Pub/Sub subscription called thumbnail-workers:
gcloud pubsub subscriptions create \
--topic thumbnail-service thumbnail-workers
# The thumbnail generation service receives requests from the thumbnail-workers subscription.
# ========== Creating a GKE cluster
# create a GKE cluster with permission to call APIs:
gcloud container clusters create "photoalbum-cluster" \
--scopes "https://www.googleapis.com/auth/cloud-platform" \
--num-nodes "5"
# Get access credentials configured so that you can manage the cluster using the kubectl command in later steps:
gcloud container clusters get-credentials photoalbum-cluster
# Show the list of nodes:
kubectl get nodes
# In the output, confirm that there are five nodes with the STATUS of Ready:
NAME STATUS ROLES AGE VERSION
gke-photoalbum-cluster-default-pool-0912a91a-24vt Ready <none> 6m v1.9.7-gke.6
gke-photoalbum-cluster-default-pool-0912a91a-5h1n Ready <none> 6m v1.9.7-gke.6
gke-photoalbum-cluster-default-pool-0912a91a-gdm9 Ready <none> 6m v1.9.7-gke.6
gke-photoalbum-cluster-default-pool-0912a91a-swv6 Ready <none> 6m v1.9.7-gke.6
gke-photoalbum-cluster-default-pool-0912a91a-thv8 Ready <none> 6m v1.9.7-gke.6
# ========== Building images for the app
# In a text editor, open the application/photoalbum/src/auth_decorator.py file and update the username and password:
USERNAME = 'username'
PASSWORD = 'passw0rd'
# build an image for the photo album app by using the Cloud Build service:
gcloud builds submit ./application/photoalbum -t \
gcr.io/${PROJECT_ID}/photoalbum-app
# Build an image for the thumbnail-worker thumbnail generation service by using the Cloud Build service:
gcloud builds submit ./application/thumbnail -t \
gcr.io/${PROJECT_ID}/thumbnail-worker
# ========== Deploying the photo album app
# update the Kubernetes Deployment manifests for the photo album and the thumbnail generator with values from your environment:
connection_name=$(gcloud sql instances describe photoalbum-db \
--format "value(connectionName)")
digest_photoalbum=$(gcloud container images describe gcr.io/${PROJECT_ID}/photoalbum-app:latest \
--format "value(image_summary.digest)")
sed -i.bak -e "s/\[PROJECT_ID\]/${PROJECT_ID}/" \
-e "s/\[CONNECTION_NAME\]/${connection_name}/" \
-e "s/\[DIGEST\]/${digest_photoalbum}/" \
config/photoalbum-deployment.yaml
digest_thumbnail=$(gcloud container images describe gcr.io/${PROJECT_ID}/thumbnail-worker:latest \
--format "value(image_summary.digest)")
sed -i.bak -e "s/\[PROJECT_ID\]/${PROJECT_ID}/" \
-e "s/\[CONNECTION_NAME\]/${connection_name}/" \
-e "s/\[DIGEST\]/${digest_thumbnail}/" \
config/thumbnail-deployment.yaml
# Create deployment resources to launch the photo album app and the thumbnail generation service:
kubectl create -f config/photoalbum-deployment.yaml
kubectl create -f config/thumbnail-deployment.yaml
# Create a service resource to assign an external IP address to the app:
kubectl create -f config/photoalbum-service.yaml
# Check the results for the Pods
kubectl get pods
# In the output, confirm that there are three pods for each photoalbum-app and thumbail-worker with a STATUS of Running:
NAME READY STATUS RESTARTS AGE
photoalbum-app-555f7cbdb7-cp8nw 2/2 Running 0 2m
photoalbum-app-555f7cbdb7-ftlc6 2/2 Running 0 2m
photoalbum-app-555f7cbdb7-xsr4b 2/2 Running 0 2m
thumbnail-worker-86bd95cd68-728k5 2/2 Running 0 2m
thumbnail-worker-86bd95cd68-hqxqr 2/2 Running 0 2m
thumbnail-worker-86bd95cd68-xnxhc 2/2 Running 0 2m
# Note: thumbnail-worker subscribes thumbnail generation requests from the thumbnail-workers subscription. For more details, see how the callback function is used in the source code.
# Check the results for the Services:
kubectl get services
# In the output, confirm that there is an external IP address in the EXTERNAL-IP column for photoalbum-service. It might take a few minutes until they are all set and running.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.23.240.1 <none> 443/TCP 20m
photoalbum-service LoadBalancer 10.23.253.241 146.148.111.115 80:32657/TCP 2m
# Make a note of the external IP address because it's used later in this tutorial. In this example, it is 146.148.111.115.
# ========== Testing the photo album app
# To access the deployed app in a web browser, go to the following URL and enter the username and password that you previously set up:
https://external-ip
# Replace external-ip with the IP address that you copied in the previous step.
# To upload an image file of your choice, click Upload
# ========== Create a Pub/Sub topic, subscription, and notification
# create a Pub/Sub topic called safeimage-service:
gcloud pubsub topics create safeimage-service
# Create a Pub/Sub subscription called safeimage-workers:
gcloud pubsub subscriptions create \
--topic safeimage-service safeimage-workers
# Configure a Pub/Sub notification so that a message is sent to the safeimage-service topic when a new file is uploaded to the Cloud Storage bucket:
gsutil notification create -t safeimage-service -f json \
gs://${PROJECT_ID}-photostore
# ========== Build and deploy the worker image
# build a container image for the safeimage-workers subscription by using Cloud Build:
gcloud builds submit ./application/safeimage \
-t gcr.io/${PROJECT_ID}/safeimage-worker
# Update the Kubernetes Deployment manifests for the safe-image service with your Google Cloud project ID, Cloud SQL connection name, and container image digests:
digest_safeimage=$(gcloud container images describe \
gcr.io/${PROJECT_ID}/safeimage-worker:latest --format \
"value(image_summary.digest)")
sed -i.bak -e "s/\[PROJECT_ID\]/${PROJECT_ID}/" \
-e "s/\[CONNECTION_NAME\]/${connection_name}/" \
-e "s/\[DIGEST\]/${digest_safeimage}/" \
config/safeimage-deployment.yaml
# ========== Create a deployment resource
# Create a deployment resource called safeimage-deployment to deploy the safeimage-service topic:
kubectl create -f config/safeimage-deployment.yaml
# Check the results:
kubectl get pods
# In the output, confirm that there are three pods of safeimage-worker with the STATUS of Running.
NAME READY STATUS RESTARTS AGE
photoalbum-app-555f7cbdb7-cp8nw 2/2 Running 0 30m
photoalbum-app-555f7cbdb7-ftlc6 2/2 Running 0 30m
photoalbum-app-555f7cbdb7-xsr4b 2/2 Running 8 30m
safeimage-worker-7dc8c84f54-6sqzs 1/1 Running 0 2m
safeimage-worker-7dc8c84f54-9bskw 1/1 Running 0 2m
safeimage-worker-7dc8c84f54-b7gtp 1/1 Running 0 2m
thumbnail-worker-86bd95cd68-9wrpv 2/2 Running 0 30m
thumbnail-worker-86bd95cd68-kbhsn 2/2 Running 2 30m
thumbnail-worker-86bd95cd68-n4rj7 2/2 Running 0 30m
.
Comments powered by Disqus.