Data Structures - Basic 1 - Data Structures
- Data Structures - Basic 1 - Data Structures
- Linear Structures
- String
- Arrays 数组 (fixed size)
- List Interface
- Positional Lists Interface
- Iterators Interface
- Iterable Interface
- Collection Interface
- Stack
- Queue
- Deque (Double-Ended Queues)
- Priority Queues
- Maps, Hash Tables, and Skip Lists
- Hashing
- Nonlinear data structures
Data Structures - Basic 1 - Data Structures
source:
- https://runestone.academy/runestone/books/published/pythonds/BasicDS/toctree.html
- Problem Solving with Algorithms and Data Structures using Python
- Data Structures and Algorithms in Java, 6th Edition.pdf
Data Structures - Basic 1 - Data Structures
- Data Structures - Basic 1 - Data Structures
- Linear Structures
- String
- Arrays 数组 (fixed size)
- List Interface
- Positional Lists Interface
- Iterators Interface
- Iterable Interface
- Collection Interface
- Stack
- Queue
- Deque (Double-Ended Queues)
- Priority Queues
- Maps, Hash Tables, and Skip Lists
- Hashing
- Nonlinear data structures
Overview

interfaceis a type definition that includes public declarations of various methods, an interface cannot include definitions for any of those methods.abstract classmay define concrete implementations for some of its methods, while leaving other abstract methods without definition.- An abstract class is designed to serve as a base class, through inheritance, for one or more concrete implementations of an interface.
- When some of the functionality of an interface is implemented in an abstract class, less work remains to complete a concrete implementation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// interface
public interface Tree<E> extends Iterable<E> {
Position<E> root();
Position<E> parent(Position<E> p) throws IllegalStateException;
Iterable<Position<E>> children(Position<E> p) throws IllegalStateException;
int numChildren(Position<E> p) throws IllegalStateException;
boolean isInternal(Position<E> p) throws IllegalStateException;
boolean isExternal(Position<E> p) throws IllegalStateException;
boolean isRoot(Position<E> p) throws IllegalStateException;
int size();
boolean isEmpty();
Iterator<E> iterator();
Iterable<Position<E>> positions();
}
// abstract class
public abstract class AbstractTree<E> implements Tree<E> {
public boolean isInternal(Position<E> p) {return numChildren(p)>0;}
public boolean isExternal(Position<E> p) {return numChildren(p)<0;}
public boolean isRoot(Position<E> p) {return p==root();}
public boolean isEmpty(){return size()==0;}
}
pic









Linear Structures
Stacks, queues, dequeues, lists
- examples of data collections whose items are ordered depending on
how they are added or removed. - Once an item is added, it stays in that position relative to the other elements that came before and came after it.
- these Collections are often referred as linear data structures.
Linear structures can be thought of as having two ends.
- “left” and the “right”
- “front” and the “rear”
- “top” and the “bottom.”
What distinguishes one linear structure from another is the way in which items are added and removed
- in particular the location where these additions and removals occur.
- 唯一前后,左右 前后,
- 添加,去除,插入
- stack, queue, deque, list
Array:
- limit capacity
- O(n) for insert and delete
- have index but need traverse
表 list:
- 可以根据索引取值;
- 缺点:插入和删除是O(n)的
LinkedList:
- unbounded capacity (n -> 2n)
- O(1) for insert and delete
- have index but need traverse
PositionalList:
- unbounded capacity (n -> 2n)
- O(1) for insert and delete
- have p for each element, no need traverse
栈 stack:
- 先进后出 FILO,操作较快;
- 缺点:查询慢,读非栈顶数值需要
遍历
队列 queue:
- 先进先出 FIFO,同样操作较快;
- 缺点:读取内部数值需要
遍历



String
two algorithms for composing a long string
String class
String
- Because it is common to work with sequences of text characters in programs, Java provides support in the form of a String class.
- The class provides extensive support for various text-processing tasks
A string instance represents
a sequence of zero or more characters.- Java uses double quotes to designate string literals.
- declare and initialize a String instance as follows:
String title = "Data Structures & Algorithms in Java"
- declare and initialize a String instance as follows:
- Character Indexing
- Each character within a string can be referenced by using an index
- Concatenation 级联
P + Q- The primary operation for combining strings is called concatenation,
- P + Q, which consists of all the characters of P followed by all the characters of Q.
- concatenation on two strings:
String term = "over" + "load";
- immutable
- An important trait, String instances are immutable;
- once an instance is created and initialized, the value of that instance cannot be changed.
- This is an intentional design, it allows for great efficiencies and optimizations within the Java Virtual Machine.
However, as String is a class, a reference type,
variablesof type String can be reassigned to anotherstring instance(even if the current string instance cannot be changed)1 2 3 4
String greeting = "Hello"; greeting = "Ciao"; // changed our mind greeting = greeting + '!'; // now it is ”Ciao!”
- However, this operation does create a new string instance, copying all the characters of the existing string in the process.
- For long string (such as DNA sequences), this can be very time consuming.
- An important trait, String instances are immutable;
StringBuilder class
StringBuilder
- to support more efficient editing of character strings
effectively a mutable version of a string.
- significantly faster, with empirical evidence that suggested
- a quadratic running time for the algorithm with repeated concatenations,
- and a linear running time for the algorithm with the StringBuilder.
The StringBuilder class represents a mutable string by storing characters in a dynamic array.
it guarantees that a series of append operations resulting in a string of length n execute in a combined time of O(n). (Insertions at positions other than the end of a string builder do not carry this guarantee, just as they do not for an ArrayList.)
- In contrast, the repeated use of string concatenation requires quadratic time. that approach is akin to a dynamic array with an arithmetic progression of size one, repeatedly copying all characters from one array to a new array with size one greater than before.
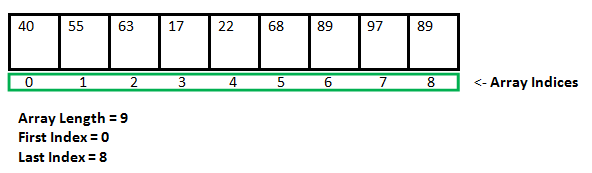
Arrays 数组 (fixed size)
- https://www.geeksforgeeks.org/arrays-in-java/
- https://leetcode.com/explore/learn/card/array-and-string/201/introduction-to-array/1143/

basic data structure
In Java all arrays are
dynamically allocated.The idea is to
store multiple items of the same type together.- Since arrays are objects in Java, can find their length using the object property length. This is different from C/C++, where find length using sizeof.
- A Java array variable can also be declared like other variables with [] after the data type.
- The variables in the array are ordered, and each has an index beginning from 0.
- Java array can be also be used as a static field, a local variable, or a method parameter.
- The size of an array must be specified by int or short value and not long.
- The direct superclass of an array type is Object.
- Every array type implements the interfaces Cloneable and java.io.Serializable.
An array can contain primitives (int, char, etc.) and object (non-primitive) references of a class depending on the definition of the array.
- primitive data types: the actual values are stored in contiguous memory locations.
class objects, the actual objects are stored in a heap segment.
- to store a collection of elements sequentially
- keep track of an ordered sequence of related values or objects.
- a collection of items stored at contiguous 连续的 memory locations
element: Each value stored in an array
- capacity: the length of an array
- the length of an array determines the maximum number of things that can be stored in the array
- an array has a fixed capacity
- he capacity of the array must be fixed when it is created, specify the size of the array when initialize it.
- the precise size of array must be internally declared in order for
the system to properly allocate a consecutive piece of memory for its storage.- For example,
- an array with 12 cells
- might be stored in memory locations 2146 through 2157 on a computer system.
- For example,
- Because the system may allocate neighboring memory locations to store other data, the capacity of an array cannot be increased by expanding into subsequent cells.
- serious limitation;
- it requires that a
fixed maximum capacity be declared, throwing an exception if attempting to add an element once full. - risk: either too large of an array will be requested, inefficient waste of memory,
- or that too small of an array will be requested, fatal error when exhausting that capacity.
- it requires that a
- Array can contains primitives (int, char, etc) as well as object (or non-primitives) references of a class depending on the definition of array.
- In case of primitives data types
- the actual
valuesare stored incontiguous memory locations.
- the actual
- In case of objects of a class
- the actual
objectsare stored inheap segment
- the actual
- In case of primitives data types
Advantages
- have better cache locality
- big difference in performance.
- index:
- elements can be accessed randomly as each element in the array can be identified by an array index.
- easier to calculate the
position of each elementby simply adding an 抵消 offset to a base value - i.e., the memory location of the first element of the array (generally denoted by the name of the array).
- Each element can be uniquely identified by their
indexin the array. - makes accessing elements by position faster.

- Out of Bounds Errors
- attempt to index into an array a using a number outside the range.
- Such a reference is said to be out of bounds.
- buffer overflow attack
- Out of bounds references have been exploited numerous times by hackers to compromise the security of computer systems written in languages other than Java.
- As a safety feature, array indices are always checked in Java to see if they are ever out of bounds.
- If an array index is out of bounds, the runtime Java environment signals an error condition. The name of this condition is the
ArrayIndexOutOfBoundsException. This check helps Java avoid a number of security problems, such as buffer overflow attacks.
Create Array
One-Dimensional Arrays
An array declaration has two components: the type and the name.
- type
- declares the
element typeof the array. - determines the data type of each element that comprises the array.
- determines what type of data the array will hold.
- Like an array of integers, other primitive data types like char, float, double, etc., or user-defined data types (objects of a class).
- declares the
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
type var-name[];
type[] var-name;
// both are valid declarations
int intArray[];
int[] intArray;
byte byteArray[];
short shortsArray[];
boolean booleanArray[];
long longArray[];
float floatArray[];
double doubleArray[];
char charArray[];
// an array of references to objects of the class
MyClass myClassArray[];
Object[] ao, // array of Object
Collection[] ca; // array of Collection of unknown type
Although the first declaration establishes that intArray is an array variable, no actual array exists.
- It merely tells the compiler that this variable (intArray) will hold an array of the integer type.
- To link intArray with an actual, physical array of integers, allocate one using new and assign it to intArray.
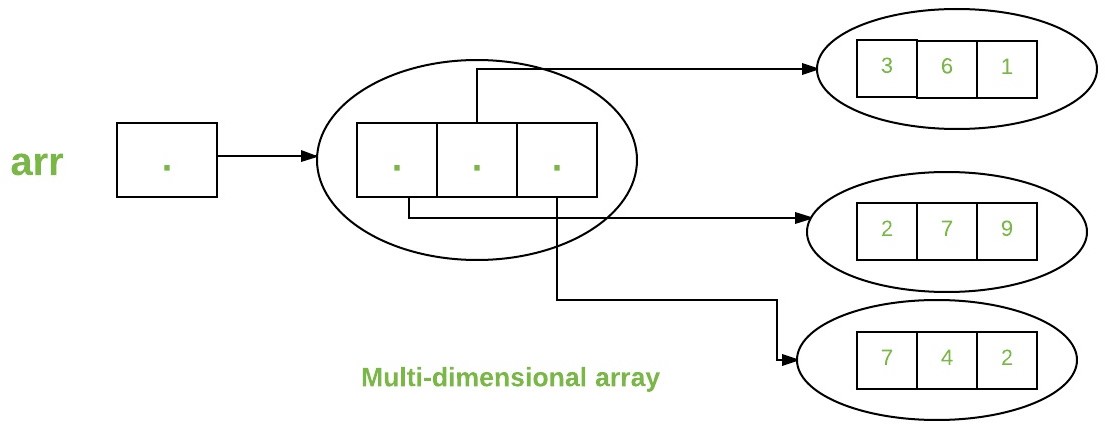
Multidimensional Arrays
- drawbacks.
insertions and deletions at interior positions of an array can be time consuming if many elements must be shifted.
an array has a fixed capacity, The capacity of the array must be fixed when it is created, need to specify the size of the array when initialize it.
unbounded/dynamic array
- Therefore, most programming languages offer built-in dynamic array
- still a random access list data structure
- but with variable size.
- For example, have
vectorin C++ andArrayListin Java.
Java’s ArrayList classprovides a more robust abstraction, allowing a user to add elements to the list, with no apparent limit on the overall capacity.- To provide this abstraction, Java relies on an algorithmic sleight of hand that is known as a dynamic array.
- an array list instance maintains an internal array that often has greater capacity than the current length of the list.
- If a user continues to add elements to a list, all reserved capacity in the underlying array will eventually be exhausted.
- In that case, the class requests a new, larger array from the system, and copies all references from the smaller array into the beginning of the new array.
- At that point in time, the old array is no longer needed, so it can be reclaimed by the system.
Multidimensional arrays are arrays of arrays with each element of the array holding the reference of other arrays.
- two-dimensional array is sometimes also called a matrix.
- These are also known as Jagged Arrays.
- A
multidimensional arrayis created by appending one set of square brackets ([]) per dimension. Examples:
1
2
int[] intArray = new int[10][20]; //a 2D array or matrix
int[] intArray = new int[10][20][10]; //a 3D array
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
type var-name[];
type[] var-name;
List<Integer> v0 = new ArrayList<>();
List<Integer> v1; // v1 == null
Integer[] a = {0, 1, 2, 3, 4};
v1 = new ArrayList<>(Arrays.asList(a));
// 3. make a copy
List<Integer> v2 = v1; // another reference to v1
List<Integer> v3 = new ArrayList<>(v1); // make an actual copy of v1
// both are valid declarations
int intArray[];
int[] intArray;
byte byteArray[];
short shortsArray[];
boolean booleanArray[];
long longArray[];
float floatArray[];
double doubleArray[];
char charArray[];
// an array of references to objects of
// the class MyClass (a class created by
// user)
MyClass myClassArray[];
Object[] ao, // array of Object
Collection[] ca; // array of Collection of unknown type
running time:
- size( ):
O(1) - isEmpty( ):
O(1) - first(), last():
O(1) - before(p), after(p):
O(1) - addFirst(e), addLast(e):
O(1) - addBefore(p, e), addAfter(p, e):
O(1) - set(p, e):
O(1) - remove( p):
O(1)
Instantiating an Array in Java
When an array is declared, only a reference of an array is created.
To create or give memory to the array, you create an array like this: The general form of new as it applies to one-dimensional arrays appears as follows:
- type specifies the type of data being allocated,
- size determines the number of elements in the array,
- var-name is the name of the array variable that is linked to the array.
- use new to allocate an array, you must specify the type and number of elements to allocate.
an instance of an array is treated as an object by Java, and variables of an array type are reference variables.
var-name = new type [size];
typespecifies the type of data being allocatedsizespecifies the number of elements in the arrayvar-nameis the name of array variable that is linked to the array.- to use new to allocate an array, must specify the type and number of elements to allocate.
Instantiating
- Obtaining an array is a two-step process.
- First, must declare a variable of the desired array type.
- Second, must allocate the memory that will hold the array, using
new, and assign it to the array variable. Thus, in Java all arrays are dynamically allocated.
- declaration
- declare a variable of the desired array type.
- establishes the fact that intArray is an array variable,
- but no array actually exists.
- When an array is declared, only a reference of array is created.
- It simply tells to the compiler that
this(intArray) variable will hold an array of the integer type.
- allocate
- must allocate one using
newand assign it to intArray. - allocate the memory to hold the array, using new, and assign it to the array variable. Thus, in Java, all arrays are dynamically allocated.
- To link intArray with an actual, physical array of integers
- The elements in the array allocated by
newwill automatically be initialized tozero (for numeric types),false (for boolean), ornull (for reference types).
- must allocate one using
1
2
3
4
5
6
var-name = new type [size];
int intArray[]; //declaring array
intArray = new int[20]; // allocating memory to array
int[] intArray = new int[20]; // combining both statements in one
int[] intArray = new int[]{ 1,2,3,4,5,6,7,8,9,10 };
where the size of the array and variables of array are already known, array literals can be used.
- The length of this array determines the length of the created array.
- no need to write the new int[] part in the latest versions of Java
method
- Because arrays are so important, Java provides a class,
java.util.Arrays, with a number of built-in static methods for performing common tasks on arrays.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
elementType[] arrayName = {initialValue0, initialValue1, . . . , initialValueN−1};
elementType[] arrayName = new elementType[length]
// When arrays are created using the new operator, all of their elements are automatically assigned the default value for the element type.
// if the element type is numeric, all cells of the array are initialized to zero,
// if the element type is boolean, all cells are false,
// if the element type is a reference type, all cells are initialized to null.
int[] a0 = new int[5];
int[] a1 = {1, 2, 3};
a1.length;
a1[0];
a1[0] = 4;
for (int i = 0; i < a1.length; ++i) System.out.print(" " + a1[i]);
for (int item: a1) System.out.print(" " + item);
Arrays.sort(a1);
Arrays.equals(A, B)
Arrays.fill(A, x)
Arrays.copyOf(A, n)
// Returns an array of size n such that the first k elements of this array are copied from A, where k = min{n, A.length}. If n > A.length, then the last n − A.length elements in this array will be padded with default values, e.g., 0 for an array of int and null for an array of objects.
Arrays.copyOfRange(A, s, t) // order from A[s] to A[t − 1]
Arrays.toString(A)
Arrays.sort(A)
Arrays.binarySearch(A, x)
running time
- size( ):
O(1) - isEmpty( ):
O(1) - get(i):
O(1) - set(i, e):
O(1) - add(i, e):
O(n) - remove(i):
O(n)
Time
O(1)to add/remove at end (amortized for allocations for more space), index, or updateO(n)to insert/remove elsewhere
Space
- contiguous in memory, so proximity helps performance
- space needed = (array capacity, which is >= n) * size of item,
- but even if 2n, still O(n)
Arrays of Objects
An array of objects is created like an array of primitive type data items in the following way.
1
Student[] arr = new Student[7]; //student is a user-defined class
The studentArray contains seven memory spaces each of the size of student class in which the address of seven Student objects can be stored. The Student objects have to be instantiated using the constructor of the Student class, and their references should be assigned to the array elements in the following way.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
Student[] arr = new Student[5];
// Java program to illustrate creating an array of objects`
class Student {
public int roll_no;
public String name;
Student(int roll_no, String name) {
this.roll_no = roll_no;
this.name = name;
}
}
// Elements of the array are objects of a class Student.`
public class GFG {
public static void main (String[] args) {
// declares an Array of integers.
Student[] arr;
// allocating memory for 5 objects of type Student.
arr =new Student[5];
arr[0] =new Student(1, "aman");
arr[1] =new Student(2, "vaibhav");
arr[2] =new Student(3, "shikar");
arr[3] =new Student(4, "dharmesh");
arr[4] =new Student(5, "mohit");
}
}
Java Array Error
JVM throws ArrayIndexOutOfBoundsException to indicate that the array has been accessed with an illegal index. The index is either negative or greater than or equal to the size of an array.
1
2
Runtime error:
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 2 at GFG.main(File.java:12)
Class Objects for Arrays
Every array has an associated Class object, shared with all other arrays with the same component type.
1
2
3
4
5
6
7
8
9
10
11
class Test {
public static void main(String args[]) {
int intArray[] = new int[3];
byte byteArray[] =new byte[3];
short shortsArray[] =new short[3];
String[] strArray =new String[3];
System.out.println(intArray.getClass());
System.out.println(intArray.getClass().getSuperclass());
}
}
Explanation:
- The string “[I” is the run-time type signature for the class object “array with component type int.”
- The only direct superclass of an array type is java.lang.Object.
- The string “[B” is the run-time type signature for the class object “array with component type byte.”
- The string “[S” is the run-time type signature for the class object “array with component type short.”
- The string “[L” is the run-time type signature for the class object “array with component type of a Class.” The Class name is then followed.
Array Members
Now, as you know that arrays are objects of a class, and a direct superclass of arrays is a class Object. The members of an array type are all of the following:
- The public final field length, which contains the number of components of the array. Length may be positive or zero.
- All the members inherited from class Object; the only method of Object that is not inherited is its clone method.
- The public method clone(), which overrides the clone method in class Object and throws no checked exceptions.
Arrays Types, Allowed Element Types
Array Types
- Primitive Type Arrays: Any type which can be implicitly promoted to declared type.
- Object Type Arrays: Either declared type objects or it’s child class objects.
- Abstract Class Type Arrays: Its child-class objects are allowed.
- Interface Type Arrays: Its implementation class objects are allowed.
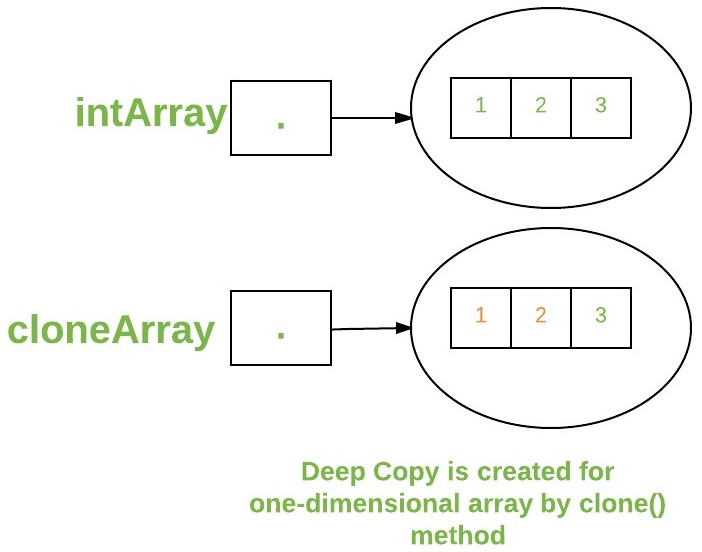
Cloning of arrays
single-dimensional array clone a single-dimensional array, such as Object[],
- a “deep copy” is performed with the new array containing copies of the original array’s elements as opposed to references.
1
2
3
int intArray[] = {1, 2, 3};
int cloneArray[] = intArray.clone();
System.out.println(intArray == cloneArray) // false
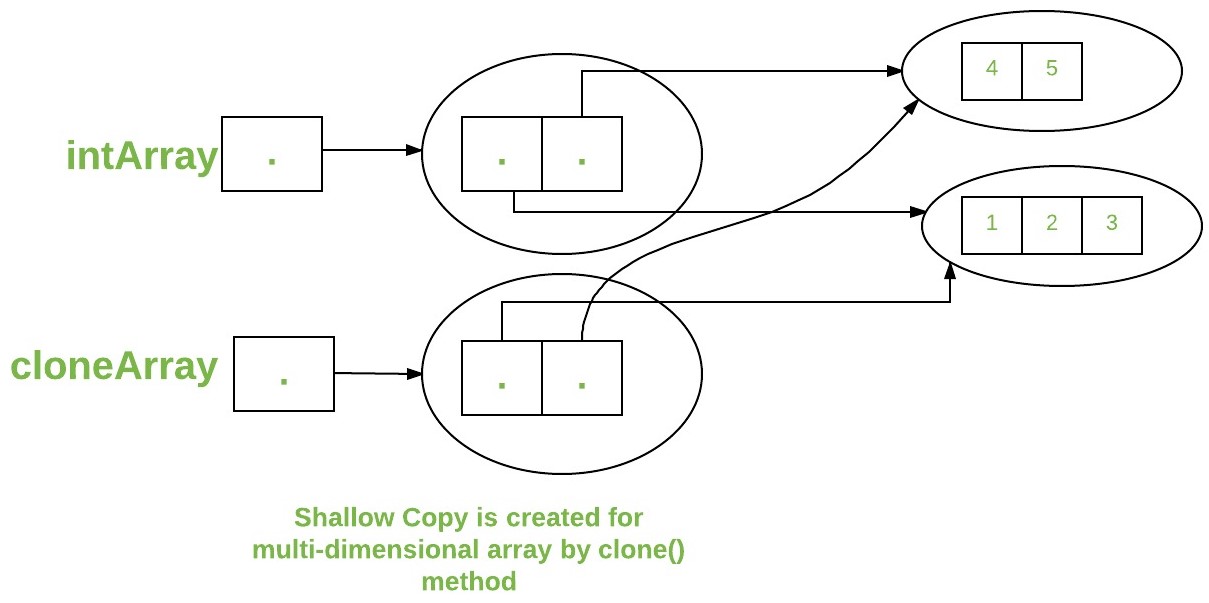
multi-dimensional array A clone of a multi-dimensional array (like Object[])
- a “shallow copy,”
- it creates only a single new array with each element array a reference to an original element array
- subarrays are shared.
1
2
3
4
int intArray[][] = {4,5};
int cloneArray[][] = intArray.clone();
System.out.println(intArray == cloneArray); // false
System.out.println(intArray[0] == cloneArray[0]); // true
List Interface
designing a single abstraction that is well suited for efficient implementation with either an array or a linked list is challenging, given the very different nature of these two fundamental data structures.
Locations within an array are easily described with an integer
index.- The notion of an element’s index is well defined for a linked list as well,
but it is not as convenient of a notion, as there is no way to efficiently access an element at a given index without traversing a portion of the linked list that depends upon the magnitude of the index.
- With that said, Java defines a general interface, java.util.List, that includes the following index-based methods (and more):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
size():
isEmpty():
get(i):
set(i,e):
add(i, e):
remove(i)
public interface List<E> {
int size();
boolean isEmpty();
E get(int i) throws IndexOutOfBoundsException;
E set(int i, E e) throws IndexOutOfBoundsException;
void add(int i, E e) throws IndexOutOfBoundsException;
E remove(int i) throws IndexOutOfBoundsException;
}
differences between ArrayList and LinkedList in Java
ArrayList
This class uses a dynamic array to store the elements in it. With the introduction of
generics, this class supports the storage of all types of objects.Manipulating ArrayList takes more time due to the internal implementation. Whenever remove an element, internally, the array is traversed and the memory bits are shifted.
This class implements a
Listinterface. Therefore, this acts as a list.This class works better when the application demands storing the data and accessing it.
LinkedList
This class uses a doubly linked list to store the elements in it. Similar to the ArrayList, this class also supports the storage of all types of objects.
Manipulating LinkedList takes less time compared to ArrayList because, in a doubly-linked list, there is no concept of shifting the memory bits. The list is traversed and the reference link is changed.
This class implements both the
Listinterface and theDequeinterface. Therefore, it can act as a list and a deque.This class works better when the application demands manipulation of the stored data.
ArrayList and LinkedList
ArrayListuses the Array data structureLinkedListuses the DoublyLinkedList data structure.
compare similar operations on ArrayList and LinkedList and see which is more efficient in terms of performance and why.
- Insert Value at Last Index
- ArrayList has to:
- Check whether the underlying array is already full or not.
- If the array is full then it copies the data from the old array to new array(size double than an old array),
- Then
add the value at the last index.
- LinkedList
- simply
adds that value at the tailof the underlying DoublyLinkedList.
- simply
- compare
- Both have time complexity
O(1) - but due to ArrayList added steps of creating a new array, and copying the existing values to the new index, its worst-case complexity reaches to O(N), prefer using LinkedList where multiple inserts are required.
- Both have time complexity
- ArrayList has to:
- Insert Value at Given Index
- ArrayList has to:
- Check whether the underlying array is already full or not.
- If the array is full then it copies the data from the old array to a new array(size double than an old array).
- After that, starting from the given index, shift values by one index to create space for the new value.
- Then
add the value at the given index.
- LinkedList
- simply
finds the index and adds that valueat a given index by rearranging pointers of underlying DoublyLinkedList.
- simply
- compare
- Both have time complexity
O(N) - but due to ArrayList added steps of creating a new array, and copying the existing values to the new index, prefer using LinkedList where multiple inserts are required.
- Both have time complexity
- ArrayList has to:
- Search by Value
- When search any value in ArrayList or LinkedList, have to iterate through all elements.
- Compare
- This operation has
O(N)time complexity. - array (underlying data structure of ArrayList) stores all values in a
continuous memory location, - DoublyLinkedList store each node at a
random memory location. - Iterating through continuous memory location is more performance efficient than random memory location, prefer ArrayList over LinkedList when searching by value.
- This operation has
- Get Element by Index
- ArrayList
- can give any element in
O(1)complexity as the array has random access property. - access any index directly without iterating through the whole array.
- can give any element in
- LinkedList
- time complexity to get a value by index from LinkedList is
O(N). - has a sequential access property, needs to iterate through each element to reach a given index
- time complexity to get a value by index from LinkedList is
- compare
- When get an element by Index then ArrayList is a clear winner.
- ArrayList
- Remove by Value
- To remove an element by value in ArrayList and LinkedList need to iterate through each element to reach that index and then remove that value.
- This operation is of
O(N)complexity. - compare
- LinkedList: just need to modify pointers, which is
O(1)complexity, - ArrayList: need to shift all elements after the index of the removed value to fill the gap created.
- as shifting is costly operation then modifying pointers, so even after the same overall complexity O(N), prefer LinkedList where more delete by value operation is required.
- LinkedList: just need to modify pointers, which is
- Remove by Index
- ArrayList
- find that index using random access in
O(1)complexity, - but after removing the element, shifting the rest of the elements causes overall
O(N)time complexity.
- find that index using random access in
- LinkedList
- takes O(N) time to find the index using sequential access,
- but to remove the element, just need to modify pointers.
- compare
- As shifting is costly operation than iterating, so LinkedList is more efficient if want to delete element by index.
- ArrayList
ArrayList class
- An obvious choice for implementing the list ADT is to use an array A
A[i]stores (a reference to) the element with index i.- a more advanced technique effectively allows an array-based list to have unbounded capacity.
- Array list in Java
- or a vector in C++ and in the earliest versions of Java
ArrayList (Simple array-based list) (fixed-capacity)

- With a representation based on an array A, the
get(i)andset(i, e)methods are easy to implement by accessingA[i](assuming i is a legitimate index). - Methods
add(i, e)andremove(i)are more time consuming, as they require shifting elements up or down to maintain our rule of always storing an element whose list index is i at index i of the array.
Method
size( ): O(1)isEmpty( ): O(1)get(i): O(1)set(i, e): O(1)add(i, e): O(n)remove(i): O(n)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
ArrayList<Integer> al = new ArrayList<Integer>();
package list;
public class ArrayList<E> implements List<E> { // instance variables {
// default array capacity
public static final int CAPACITY=16;
// generic array used for storage
private E[] data;
private int size = 0;
// constructors
public ArrayList() { this(CAPACITY); }
// constructs list with given capacity
public ArrayList(int capacity) {
data = (E[]) new Object[capacity];
}
// public methods
public int size() { return size; }
public boolean isEmpty() { return size == 0; }
// utility method
// /* Checks whether the given index is in the range [0, n-1]. */
protected void checkIndex(int i, int n) throws IndexOutOfBoundsException {
if (i < 0 || i >= n) throw new IndexOutOfBoundsException("Illegal index: " + i);
}
public E get(int i) throws IndexOutOfBoundsException {
checkIndex(i, size);
return data[i];
}
// /** Replaces the element at index i with e, and returns the replaced element. */
public E set(int i, E e) throws IndexOutOfBoundsException {
checkIndex(i, size);
E temp = data[i];
data[i] = e;
return temp;
}
// /** Inserts element e to be at index i, shifting all subsequent elements later. */
public void add(int i, E e) throws IndexOutOfBoundsException, IllegalStateException {
checkIndex(i, size + 1);
// not enough capacity
if (size == data.length) throw new IllegalStateException("Array is full");
// start by shifting rightmost
for (int k=size - 1; k >= i; k--) {
data[k+1] = data[k];
}
// ready to place the new element
data[i] = e;
size++;
}
// /** Removes/returns the element at index i, shifting subsequent elements earlier. */
public E remove(int i) throws IndexOutOfBoundsException {
checkIndex(i, size);
E temp = data[i];
for (int k=i; k < size-1; k++){
data[k] = data[k+1];
}
data[size-1] = null;
size--;
return temp;
}
}
Dynamic Arrays (fixed-capacity)
ArrayList:- has a serious limitation; it
requires that a fixed maximum capacitybe declared, throwing an exception if attempting to add an element once full. - if a user is unsure of the maximum size that will be reached for a collection, there is risk that
- either too large of an array will be requested, causing an inefficient waste of memory,
- or too small of an array will be requested, causing a fatal error when exhausting that capacity.
- has a serious limitation; it
Java’s ArrayList class provides a more robust abstraction, allowing a user to add elements to the list, with no apparent limit on the overall capacity.
- To provide this abstraction, Java relies on an algorithmic sleight of hand that is known as a dynamic array.
dynamic array
In reality, elements of an ArrayList are stored in a traditional array, and the precise size of that traditional array must be internally declared in order for the system to properly allocate a consecutive piece of memory for its storage.
Because
the system may allocate neighboring memory locations to store other data, the capacity of an array cannot be increased by expanding into subsequent cells.- The first key to providing the semantics of an unbounded array is that an array list instance maintains an internal array that often has greater capacity than the current length of the list.
- For example, while a user may have created a list with five elements, the system may have reserved an underlying array capable of storing eight object references (rather than only five).
This extra capacity makes it easy to add a new element to the end of the list by using the next available cell of the array.
If a user continues to add elements to a list, all reserved capacity in the underlying array will eventually be exhausted.
- In that case, the class requests a
new, larger array from the system, and copies all references from the smaller array into the beginning of the new array.- A commonly used rule is for the new array to have twice the capacity of the existing array that has been filled.
- At that point in time, the old array is no longer needed, so it can be reclaimed by the system.
when a call to add a new element risks overflowing the current array, perform the following additional steps:
- Allocate a new array B with larger capacity.
SetB[k]=A[k],for k=0,...,n−1,where n denotes current number of items.Set A = B, henceforth use the new array to support the list.- Insert the new element in the new array.
1
2
3
4
5
6
7
8
9
10
11
12
13
public void add(int i, E e) throws IndexOutOfBoundsException, IllegalStateException {
checkIndex(i, size + 1);
if (size == data.length) resize(size*2);
for (int k=size - 1; k >= i; k--) data[k+1] = data[k];
data[i] = e;
size++;
}
protected void resize(int capacity) {
E[] temp = (E[]) new Object[capacity];
for(int k=0; k<size; k++) temp[k] = data[k];
data = temp;
}
- the original implementation of the ArrayList class includes two constructors:
- a default constructor that uses an initial capacity of 16,
- and a parameterized constructor that allows the caller to specify a capacity value.
- With the use of dynamic arrays,
- that capacity is no longer a fixed limit.
- greater efficiency is achieved when a user selects an initial capacity that matches the actual size of a data set, as this can avoid time spent on intermediate array reallocations and potential space that is wasted by having too large of an array.
LinkedList (array-based structure) (without fixed size) class
an alternative to an array-based structure.
A linked list, in its simplest form, is a collection of nodes that collectively form a linear sequence.
- An important property of a linked list is that
it does not have a predetermined fixed size; - it uses space proportional to its current number of elements.
basicc
- a collection of items
- each item holds a relative position with respect to the others.
- More specifically, will refer to this type of list as an
unordered list. - [54, 26, 93, 17, 77, 31].
- a linear collection of data elements
nodes, each pointing to the next node by means of apointer. - It is a data structure consisting of
a group of nodeswhich together represent a sequence.
linked list
- Singly-linked list:
- linked list
- each node points to the next node
- and the last node points to
null
- Doubly-linked list:
- linked list
- each node has two pointers,
pandn, - p points to the previous node
- n points to the next node;
- the last node’s
n pointerpoints tonull
- Circular-linked list:
- linked list
- each node points to the next node
- and the last node points back to the
first node
Time Complexity
- Access:
O(n) - Search:
O(n) - Insert:
O(1) - Remove:
O(1)
Abstract Data Type
Functions:
- size(): Returns the number of elements in the list.
- isEmpty(): Returns a boolean indicating whether the list is empty.
- get(i):
- Returns the element of the list having index i;
- an error condition occurs if i is not in range [0, size( ) − 1].
- set(i,e):
- Replaces th eelementat indexi with e, and returns the old element that was replaced;
- an error condition occurs if i is not in range [0, size( ) − 1].
- add(i, e):
- Inserts a new element
einto the list so that it has indexi, - moving all subsequent elements one index later in the list;
- an error condition occurs if i is not in
range[0,size()].
- Inserts a new element
- remove(i):
- Removes and returns the element at index i,
- moving all subsequent elements one index earlier in the list;
- an error condition occurs if i is not in range [0, size( ) − 1].
Unordered List - Abstract Data Type
List()- creates a new list that is empty.
- It needs no parameters and returns an empty list.
add(item)- adds a new item to the list.
- It needs the item and returns nothing.
- Assume the item is not already in the list.
remove(item)- removes the item from the list.
- It needs the item and modifies the list.
- Raise an error if the item is not present in the list.
search(item)- searches for the item in the list.
- It needs the item and returns a boolean value.
is_empty()- tests to see whether the list is empty.
- It needs no parameters and returns a boolean value.
size()- returns the number of items in the list.
- It needs no parameters and returns an integer.
append(item)- adds a new item to the end of the list making it the last item in the collection.
- It needs the item and returns nothing.
index(item)- returns the position of item in the list.
- It needs the item and returns the index.
insert(pos, item)- adds a new item to the list at position pos.
- It needs the item and returns nothing.
pop()- removes and returns the last item in the list.
- It needs nothing and returns an item.
pop(pos)- removes and returns the item at position pos.
- It needs the position and returns the item.
singly linked list
- In a singly linked list,
- each node stores a reference to an object that is an element of the sequence,
- as well as a reference to the next node of the list
head- Minimally, the linked list instance must keep a reference to the first node of the list
- Without an
explicit referenceto the head, there would be no way to locate that node (or indirectly, any others).
tail- The last node of the list
- can be found by traversing the linked list—starting at the head and moving from one node to another by following each node’s next reference. link/pointer hopping
- identify the tail as the node having null as its next reference.
- storing an
explicit referenceto the tail node is a common efficiency to avoid such a traversal. In similar regard, it is common for a linked list instance to keep a count of the total number of nodes that comprise the list (also known as the size of the list), to avoid traversing the list to count the nodes.

Inserting an Element at the Head of a Singly Linked List
1
2
3
4
5
Algorithm addFirst(e):
newest=Node(e);
newest.next = head;
head = newest;
size = size + 1;
Inserting an Element at the Tail of a Singly Linked List
1
2
3
4
5
6
Algorithm addLast(e):
newest=Node(e);
newest.next = null;
tail.next = newest;
tail = newest;
size = size + 1;
Removing an Element from a Singly Linked List
1
2
3
4
5
Algorithm removeFirst():
if head == null:
the list is empty;
head = head.next;
size = size - 1;
other
- Unfortunately, cannot easily delete the last node of a singly linked list.
- must be able to access the node before the last node in order to remove the last node.
- The only way to access this node is to start from the head of the list and search all the way through the list.
- to support such an operation efficiently, will need to make our list doubly linked
Circularly Linked Lists
there are many applications in which data can be more naturally viewed as having a cyclic order, with well-defined neighboring relationships, but no fixed beginning or end.
essentially a singularly linked list, the
next reference of the tail nodeis set to refer back to the head of the list (rather than null),

Round-Robin Scheduling
- One of the most important roles of an operating system is in managing the many processes that are currently active on a computer, including the scheduling of those processes on one or more central processing units (CPUs).
- In order to support the responsiveness of an arbitrary number of concurrent processes, most operating systems allow processes to effectively share use of the CPUs, using some form of an algorithm known as
round-robin scheduling.- A process is given a short turn to execute, known as a
time slice, - it is interrupted when the slice ends, even if its job is not yet complete.
- Each active process is given its own time slice, taking turns in a cyclic order.
- New processes can be added to the system, and processes that complete their work can be removed.
- A process is given a short turn to execute, known as a
- traditional linked list
- by repeatedly performing the following steps on linked list L
- process p = L.removeFirst( )
- Give a time slice to process p
- L.addLast(p)
- drawbacks: unnecessarily inefficient to repeatedly throw away a node from one end of the list, only to create a new node for the same element when reinserting it, not to mention the various updates that are performed to decrement and increment the list’s size and to unlink and relink nodes.
- by repeatedly performing the following steps on linked list L
- Circularly Linked List
- on a circularly linked list C:
- Give a time slice to process C.first()
- C.rotate()
- Implementing the new rotate method is quite trivial.
- do not move any nodes or elements
- simply advance the tail reference to point to the node that follows it (the implicit head of the list).
- on a circularly linked list C:
doubly linked list
- there are limitations that stem from the asymmetry of a singly linked list.
- can efficiently insert a node at either end of a singly linked list, and can delete a node at the head of a list,
- cannot efficiently delete a node at the tail of the list.
- cannot efficiently delete an arbitrary node from an interior position of the list if only given a reference to that node, because cannot determine the node that immediately precedes the node to be deleted (yet, that node needs to have its next reference updated).

doubly linked list
- a linked list, each node keeps an explicit reference to the node before it and a reference to the node after it.
- These lists allow a greater variety of O(1)-time update operations, including insertions and deletions at arbitrary positions within the list.
- continue to use the term “next” for the reference to the node that follows another, and introduce the term “prev” for the reference to the node that precedes it.
Header and Trailer Sentinels
- to avoid some special cases when operating near the boundaries of a doubly linked list, it helps to add special nodes at both ends of the list: a
headernode at the beginning of the list, and atrailernode at the end of the list. - These “dummy” nodes are known as
sentinels/guards, and they do not store elements of the primary sequence. - When using sentinel nodes, an empty list is initialized so that the
next field of the header points to the trailer, and theprev field of the trailer points to the header; the remaining fields of the sentinels are irrelevant (presumably null, in Java). - For a nonempty list, the header’s next will refer to a node containing the first real element of a sequence, just as the trailer’s prev references the node containing the last element of a sequence.
Advantage of Using Sentinels
- Although could implement a doubly linked list without sentinel nodes, slight extra memory devoted to the
sentinels greatly simplifies the logic of the operations.- the header and trailer nodes never change — only the nodes between them change.
- treat all insertions in a unified manner, because a new node will always be placed between a pair of existing nodes.
- every element that is to be deleted is guaranteed to be stored in a node that has neighbors on each side.
- contrast
- SinglyLinkedList implementation addLast method required a conditional to manage the special case of inserting into an empty list.
- In the general case, the new node was linked after the existing tail.
- But when adding to an empty list, there is no existing tail; instead it is necessary to reassign head to reference the new node.
- The use of a sentinel node in that implementation would eliminate the special case, as there would always be an existing node (possibly the header) before a new node.
general method
Equivalence Testing
- At the lowest level, if a and b are reference variables, then
expression a == b tests whether a and b refer to the same object(or if both are set to the null value). - higher-level notion of two variables being considered “equivalent” even if they do not actually refer to the same instance of the class. For example, typically want to consider two String instances to be equivalent to each other if they represent the identical sequence of characters.
- To support a broader notion of equivalence, all object types support a method named equals.
The author of each class has a responsibility to provide an implementation of the equals method, which overrides the one inherited from Object, if there is a more relevant definition for the equivalence of two instances
- Great care must be taken when overriding the notion of equality, as the consistency of Java’s libraries depends upon the equals method defining what is known as an equivalence relation in mathematics, satisfying the following properties:
Treatment of null:- For any nonnull reference variable x,
x.equals(null) == false(nothing equals null except null).
- For any nonnull reference variable x,
Reflexivity:- For any nonnull reference variablex,
x.equals(x) == true(object should equal itself).
- For any nonnull reference variablex,
Symmetry:- For any nonnull reference variablesxandy,
x.equals(y) == y.equals(x), should return the same value.
- For any nonnull reference variablesxandy,
Transitivity:- For any nonnull reference variables x, y, and z, if
x.equals(y) == y.equals(z) == true, thenx.equals(z) == trueas well.
- For any nonnull reference variables x, y, and z, if
- Equivalence Testing with Arrays
- a == b:
- Tests if a and b refer to the same underlying array instance.
- a.equals(b):
- identical to a == b. Arrays are not a true class type and do not override the Object.equals method.
- Arrays.equals(a,b):
- This provides a more intuitive notion of equivalence, returning true if the arrays have the same length and all pairs of corresponding elements are “equal” to each other.
- More specifically, if the array elements are primitives, then it uses the standard == to compare values.
- If elements of the arrays are a reference type, then it makes pairwise
comparisons a[k].equals(b[k])in evaluating the equivalence.
- a == b:
- compound objects
- two-dimensional arrays in Java are really one-dimensional arrays nested inside a common one-dimensional array raises an interesting issue with respect to how think about compound objects
- two-dimensional array, b, that has the same entries as a
- But the one-dimensional arrays, the rows of a and b are stored in different memory locations, even though they have the same internal content.
- Therefore
java.util.Arrays.equals(a,b) == falseArrays.deepEquals(a,b) == true
Cloning Data Structures
- abstraction allows for a data structure to be treated as a single object, even though the encapsulated implementation of the structure might rely on a more complex combination of many objects.
each class in Java is responsible for defining whether its instances can be copied, and if so, precisely how the copy is constructed.
- The universal
Object superclassdefines a method namedclone- can be used to produce shallow copy of an object.
- This uses the standard assignment semantics to assign the value of
each field of the new objectequal to thecorresponding field of the existing objectthat is being copied. - The reason this is known as a shallow copy is because if the field is a reference type, then an initialization of the form
duplicate.field = original.fieldcauses the field of the new object to refer to the same underlying instance as the field of the original object.
- A
shallow copyis not always appropriate for all classes- therefore, Java intentionally disables use of the clone() method by
- declaring it as protected,
- having it throw a CloneNotSupportedException when called.
- The author of a class must explicitly declare support for cloning by
- formally declaring that the class implements the
Cloneable interface, - and by declaring a public version of the clone() method.
- formally declaring that the class implements the
- That public method can simply call the protected one to do the field-by-field assignment that results in a shallow copy, if appropriate. However, for many classes, the class may choose to implement a deeper version of cloning, in which some of the referenced objects are themselves cloned.
- therefore, Java intentionally disables use of the clone() method by


1
2
3
4
5
int[] data = {2, 3, 5, 7, 11, 13, 17, 19};
int[] backup;
backup = data; // warning; not a copy
backup = data.clone(); // copy
shallow copy
- considerations when copying an array that stores
reference typesrather thanprimitive types.- The
clone()method produces a shallow copy of the array - producing a new array whose cells refer to the same objects referenced by the first array.
- The

deep copy
- A deep copy of the contact list can be created by iteratively cloning the individual elements, as follows, but only if the Person class is declared as Cloneable.
1
2
3
Person[] guests = new Person[contacts.length];
for (int k=0; k < contacts.length; k++)
guests[k] = (Person) contacts[k].clone(); // returns Object type
clone on 2D Arrays
- two-dimensional array is really a one-dimensional array storing other one-dimensional arrays, the same distinction between a shallow and deep copy exists.
- Unfortunately, the java.util.Arrays class does not provide any “deepClone” method.
1
2
3
4
5
6
7
8
// A method for creating a deep copy of a two-dimensional array of integers.
public static int[][] deepClone(int[][] original){
int[][] backup = new int[original.length][];
for(int k=0;k<original.length;k++){
backup[k] = original[k].clone();
}
return backup;
}
Cloning Linked Lists
- to making a class cloneable in Java
- declaring that it
implements the Cloneable interface. - implementing a
public version of the clone() methodof the class - By convention, that method should begin by creating a new instance using a call to
super.clone(), which in our case invokes the method from the Object class
- declaring that it
While the assignment of the size variable is correct, cannot allow the new list to share the same head value (unless it is null). For a nonempty list to have an independent state, it must have an entirely new chain of nodes, each storing a reference to the corresponding element from the original list. therefore create a new head node, and then perform a walk through the remainder of the original list while creating and linking new nodes for the new list.
Node Class
the constructor that a node is initially created with next set to None.
- sometimes referred to as “grounding the node,”
- use the standard ground symbol to denote a reference that is referring to
None


1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Node:
def __init__(self, node_data):
self._data = node_data
self._next = None
def get_data(self): return self._data
def set_data(self, node_data): self._data = node_data
def get_next(self): return self._next
def set_next(self, node_next): self._next = node_next
def __str__(self): return str(self._data)
## create Node objects in the usual way.
>>> temp = Node(93)
>>> temp.data
93
unordered Linked Lists: Unordered List

无序表: unordered list
- 一种数据按照相对位置存放的数据集
- (for easy, assume that no repeat)
- 无序存放,但是在数据相之间建立
链接指向, 就可以保持其前后相对位置。- 显示标记
headend
- 显示标记
- 每个节点
node包含2信息:- 数据本身,指向下一个节点的引用信息
next next=None没有下一个节点了
- 数据本身,指向下一个节点的引用信息
A linked list
nothing more than a single chain of nodes with a few well defined properties and methods such as:
- Head Pointer:
- pointer to the origin, or first node in a linked list.
- Only when the list has a length of 1 will it’s value be None.
- Tail Pointer:
- pointer to the last node in a list.
- When a list has a length of 1, the Head and the Tail refer to the same node.
- By definition, the Tail will have a next value of None.
- Count*:
- also be keeping track of the number of nodes have in our linked list. Though this is not strictly necessary, I find it to be more efficient and convenient than iterating through the entire linked list when polling for size.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
class UnorderedList:
def __init__(self):
self.head = None
self.tail = None # add the tail point
self.count = 0
def __str__(self):
list_str = "head"
current = self.head
while current != None:
list_str = list_str + "->" + str(current.get_data())
current = current.get_next()
list_str = list_str + "->" + str(None)
return list_str
def is_empty(self): return self.head == None
# """
# Add node to start of list
# (Head) [2] -> [3] -> (Tail)
# (Head) [1] -> [2] -> [3] -> (Tail)
# """
def add_to_start(self, item):
temp = Node(item)
temp.set_next(self.head)
self.head = temp
self.count += 1
if self.count == 1:
self.tail = self.head
# 只有从头来 会设定tail
# """
# Add node to end of list
# (Head)1 -> 2(Tail)
# (Head)1 -> 2 -> 3(Tail)
# """
def add_to_end(self, item):
temp = Node(item)
if self.count == 0:
self.head = new_node
else:
self.tail.next = new_node
self.tail = new_node
self.count += 1
def size(self): return self.count
def search(self, item):
current = self.head
while current is not None:
if current.data == item:
return True
current = current.next
return False
# """
# Remove node from start of list
# (Head)[1] -> [2] -> [3](Tail)
# (Head)[2] -> [3](Tail)
# """
def remove_first(self):
if self.count > 0:
self.head = self.head.next
self.count -= 1
if self.count == 0:
self.tail = None
# """
# Remove node from end of list
# (Head)1 -> 2 -> 3(Tail)
# (Head)1 -> 2(Tail)
# """
def remove_last(self):
if self.count > 0:
if self.count == 1:
self.head = None
self.tail = None
else:
current = self.head
while current.next != self.tail:
current = current.next
current.next = None
self.tail = current
self.count -= 1
# """
# Remove node by value
# (Head)[1] -> [2] -> [3](Tail)
# (Head)[1] --------> [3](Tail)
# """
def remove_by_value(self, item):
current = self.head
previous = None
while current is not None:
if current.data == item:
break
previous = current
current = current.next
if current is None:
raise ValueError("{} is not in the list".format(item))
if previous is None:
self.head = current.next
else:
previous.next = current.next
def append(self, item):
temp = Node(item)
# print(temp)
# print(self.tail)
# print(self.tail.next)
temp.next = self.tail.next
self.tail.next = temp
self.tail=temp
my_list = UnorderedList()
my_list.add_to_start(31)
my_list.add_to_start(77)
my_list.add_to_start(17)
my_list.add_to_start(93)
my_list.add_to_start(26)
my_list.add_to_start(54)
my_list.append(123)
print(my_list)
Unordered List Class <- unordered linked list (new) (!!!!!!!!!!!!!)
- 无序表必须要有对第一个节点的引用信息
- 设立属性head,保存对第一个节点的引用空表的head为None
- the unordered list will be built from a collection of nodes, each linked to the next by explicit references.
- As long as know where to find the first node (containing the first item), each item after that can be found by successively following the next links.
- the UnorderedList class must maintain a reference to the first node.
- each
listobject will maintain a single reference to the head of the list.
1
2
3
4
5
6
7
8
class UnorderedList:
def __init__(self):
self.head = None
## Initially when construct a list, there are no items.
mylist = UnorderedList()
print(mylist.head)
## None
####### is_empty()
- the special reference
Nonewill again be used to state that the head of the list does not refer to anything. - Eventually, the example list given earlier will be represented by a linked list as below

1
2
3
4
## checks to see if the head of the list is a reference to None.
## The result of the boolean expression self.head == None will only be true if there are no nodes in the linked list.
def is_empty(self):
return self.head == None

- The
headof the list refers to thefirst nodewhich contains thefirst item of the list. - In turn, that node holds a reference to the next node (the next item) and so on.
- the list class itself does not contain any node objects.
- Instead it contains
a single reference to the first node in the linked structure.
####### add()
- The new item can go anywhere
- item added to the list will be the last node on the linked list
1
2
3
4
def add(self, item):
temp = Node(item)
temp.set_next(self.head)
self.head = temp


####### size, search, and remove
- all based on a technique known as linked list traversal
- Traversal refers to the process of systematically visiting each node.
######## size()
- use an external reference that starts at the first node in the list.
- visit each node, move the reference to the next node by “traversing” the next reference.
- traverse the linked list and keep a count of the number of nodes that occurred.

1
2
3
4
5
6
7
def size(self):
current = self.head
count = 0
while current is not None:
count = count + 1
current = current.next
return count
######## search(item):
- Searching for a value in a linked list implementation of an unordered list also uses the traversal technique.
- visit each node in the linked list, ask whether the data matches the item
- may not have to traverse all the way to the end of the list.
- if get to the end of the list, that means that the item are looking for must not be present.
- if do find the item, there is no need to continue.

1
2
3
4
5
6
7
def search(self, item):
current = self.head
while current is not None:
if current.data == item:
return True
current = current.next
return False
######## remove()
- requires two logical steps.
- traverse the list for the item to remove.
- Once find the item , must remove it.
- If item is not in the list, raise a ValueError.
- The first step is very similar to search.
- Starting with an external reference set to the head of the list,
- traverse the links until discover the item
- When the item is found, break out of the loop
- use two external references as traverse down the linked list.
current, marking the current location of the traverse.previous, always travel one node behind current.


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def remove(self, item):
current = self.head
previous = None
while current is not None:
if current.data == item:
break
previous = current
current = current.next
if current is None:
raise ValueError("{} is not in the list".format(item))
if previous is None: # remove the first item
self.head = current.next
else:
previous.next = current.next
####### pop()
1
2
def pop(self, index):
self.remove(self.getItem(index))
####### append()
1
2
3
4
5
6
7
8
9
10
11
12
## 1. 𝑂(𝑛)
def append(self, item):
current = self.head
while current.set_next() is not None:
current = current.set_next()
temp = Node(item)
temp.set_next(current.set_next())
current.set_next(temp)
## 2. 𝑂(1)
## use tail point & head point
####### insert()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def insert(self, index, item):
current = self.head
# count = 0
# while current is not None:
# if count == index:
# temp = Node(item)
# temp.set_next(current.set_next())
# current.set_next(temp)
# break
# current = current.set_next()
# count += 1
for i in range(index):
current = current.set_next()
if current != None:
temp = Node(item)
temp.set_next(current.set_next())
current.set_next(temp)
else:
raise("index out of range")
####### index()
1
2
3
4
5
6
7
8
def index(self, index):
current = self.head
for i in range(index):
current = current.set_next()
if current != None:
return current.get_data()
else:
raise("index out of range")
Ordered List - Abstract Data Type
ordered list
a collection of items where each item holds a
relative position that is based upon some underlying characteristic of the item.The ordering is typically either ascending or descending and assume that list items have a meaningful comparison operation that is already defined.
Many of the ordered list operations are the same as those of the unordered list.
For example
- the list of integers were an ordered list (ascending order),
- then it could be written as
17, 26, 31, 54, 77, and 93. - Since 17 is the smallest item, it occupies the first position in the list.
- Likewise, since 93 is the largest, it occupies the last position.
Ordered List in py (!!!!!!!!!!!!!)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class OrderedList:
def __init__(self):
self.head = None
self.count = 0
# 𝑂(1)
def is_empty(self): return self.head == None
# 𝑂(1)
def size(self): return self.count
# 𝑂(n)
# require the traversal process. Although on average they may need to traverse only half of the nodes, these methods are all 𝑂(𝑛) since in the worst case each will process every node in the list.
def remove(self, item):
current = self.head
previous = None
# find the item
while current is not None:
if current.data == item:
break
previous = current
current = current.next
# if current == None (tail)
if current is None:
raise ValueError("{} is not in the list".format(item))
# if current is the head
if previous is None: # remove the first item
self.head = current.next
else:
previous.next = current.next

1
2
3
4
5
6
7
8
9
# 𝑂(n)
# require the traversal process. Although on average they may need to traverse only half of the nodes, these methods are all 𝑂(𝑛) since in the worst case each will process every node in the list.
def search(self, item):
current = self.head
while (current is not None):
if current.data > item: return False
if current.data == item: return True
current = current.next
return False

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 𝑂(n)
# require the traversal process. Although on average they may need to traverse only half of the nodes, these methods are all 𝑂(𝑛) since in the worst case each will process every node in the list.
def add(self, item):
temp = Node(item)
current = self.head
previous = None
self.count += 1
# keep finding
while (current is not None) and current.data < item:
previous = current
current = current.next
# current.data > item
# current is head
if previous is None:
temp.next = self.head
self.head = temp
else:
temp.next = current
previous.next = temp
1
2
3
4
5
6
7
8
9
10
11
my_list = OrderedList()
my_list.add(31)
my_list.add(77)
my_list.add(17)
my_list.add(93)
my_list.add(26)
my_list.add(54)
print(my_list.size())
print(my_list.search(93))
print(my_list.search(100))
Positional Lists Interface
Integer/Numeric indices
- When working with array-based sequences,
- integer indices provide an excellent means for describing the location of an element, or the location at which an insertion or deletion should take place.
- However, not a good choice for describing positions within a linked list because:
- knowing only an element’s index,
the only way to reach it is to traverse the listincrementally from its beginning or end, counting elements along the way. - not a good abstraction for describing a more local view of a position in a sequence, because the
index of an entry changes over time due to insertions or deletionsthat happen earlier in the sequence.
- knowing only an element’s index,
Positional
- to design an abstract data type that provides a way to refer to elements anywhere in a sequence, and to perform arbitrary insertions and deletions.
- it efficiently describe actions:
- such as a person deciding to leave the line before reaching the front, or allowing a friend to “cut” into line right behind him or her.
- a text document can be viewed as a long sequence of characters. A word processor uses the abstraction of a cursor to describe a position within the document without explicit use of an integer index, allowing operations such as “delete the character at the cursor” or “insert a new character just after the cursor.”
- refer to an inherent position within a document, such as the beginning of a particular chapter, without relying on a character index (or even a chapter number) that may change as the document evolves.
- it efficiently describe actions:
- to achieve
constant time insertions and deletionsat arbitrary locations, effectively need areferenceto the node at which an element is stored.- develop an ADT in which a node reference serves as the mechanism for describing a position.
- DoublyLinkedList has methods addBetween and remove that accept node references as parameters; however, intentionally declared those methods as private.
Unfortunately, the public use of nodes in the ADT would violate the object-oriented design principles of abstraction and encapsulation,
- There are several reasons to prefer that encapsulate the nodes of a linked list, for both our sake and for the benefit of users of our abstraction:
- It will be simpler for users of our data structure if they are not bothered with unnecessary details of our implementation, such as low-level manipulation of nodes, or our reliance on the use of sentinel nodes. Notice that to use the addBetween method of our DoublyLinkedList class to add a node at the beginning of a sequence, the header sentinel must be sent as a parameter.
- can provide a more robust data structure if do not permit users to directly access or manipulate the nodes. can then ensure that users do not invalidate the consistency of a list by mismanaging the linking of nodes. A more subtle problem arises if a user were allowed to call the addBetween or remove method of our DoublyLinkedList class, sending a node that does not belong to the given list as a parameter. (Go back and look at that code and see why it causes a problem!)
- By better encapsulating the internal details of our implementation, have greater flexibility to redesign the data structure and improve its performance. In fact, with a well-designed abstraction, can provide a notion of a nonnu- meric position, even if using an array-based sequence
position
- in defining the positional list ADT, introduce the concept of a position
- formalizes the intuitive notion of the “location” of an element relative to others in the list.
- A position acts as a marker or token within a broader positional list.
A position p, associated with some element e in a list L, does not change, even if the index of e changes in L due to insertions or deletions elsewhere in the list. Nor does position p change if replace the element e stored at p with another element.
- The only way in which a position becomes invalid is if that position (and its element) are explicitly removed from the list.
Abstract Data Type
java
1
2
3
4
5
6
7
8
9
10
11
12
first( ):
last():
before(p):
after(p):
isEmpty():
size():
addFirst(e):
addLast(e):
addBefore(p, e):
addAfter(p, e):
set(p, e): remove(p):
a demonstration of a typical traversal of a positional list,
- traverses a list, named guests, that stores string elements, and prints each element while traversing from the beginning of the list to the end.
1
2
3
4
5
Position<String> cursor = guset.first();
while(cursor!=null){
System.out.println(cursor.getElement( ));
cursor = guset.after(cursor);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public interface Position<E> {
/**
* Returns the element stored at this position.
*
* @return the stored element
* @throws IllegalStateException if position no longer valid
*/
E getElement()throws IllegalArgumentException;
}
/** An interface for positional lists. */
public interface PositionList<E> {
int size( );
boolean isEmpty( );
Position<E> first( );
Position<E> last( );
Position<E> before(Position<E> p) throws IllegalArgumentException;
Position<E> after(Position<E> p) throws IllegalArgumentException;
Position<E> addFirst(E e);
Position<E> addLast(E e);
Position<E> addBefore(Position<E> p, E e) throws IllegalArgumentException;
Position<E> addAfter(Position<E> p, E e) throws IllegalArgumentException;
E set(Position<E> p, E e) throws IllegalArgumentException;
E remove(Position<E> p) throws IllegalArgumentException;
}
LinkedPositionalList class (Doubly Linked List for Position)
develop a concrete implementation of the PositionalList interface using a doubly linked list.
- The obvious way to identify locations within a linked list are
nodereferences. - declare the nested Node class of linked list so as to implement the Position interface, supporting the required getElement method.
- So the nodes are the positions.
- the Node class is declared as private, to maintain proper encapsulation.
- All of the public methods of the positional list rely on the
Positiontype, so although know are sending and receiving nodes, these are only known to be positions from the outside; as a result, users of our class cannot call any method other than getElement().
Method: Running Time
size( ): O(1)isEmpty( ): O(1)first(), last(): O(1)before(p), after(p): O(1)addFirst(e), addLast(e): O(1)addBefore(p, e), addAfter(p, e): O(1)set(p, e): O(1)remove( p): O(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
package list;
// public class LinkedPositionalList<E> implements PositionalList<E> {
// private static class Node<E> implements Position<E>{ }
// private Node<E> header;
// private Node<E> trailer;
// private int size = 0;
// public LinkedPositionalList(){}
// private Node<E> validate(Position<E> p) throws IllegalArgumentException {}
// }
public class LinkedPositionalList<E> implements PositionalList<E> {
private static class Node<E> implements Position<E>{
private E element;
private Node<E> prev;
private Node<E> next;
public Node(E e, Node<E> p, Node<E> n){
element = e;
prev = p;
next = n;
}
public E getElement() throws IllegalStateException {
if(next==null) throw new IllegalStateException("Position no longer valid");
return element;
}
public Node<E> getPrev() {
return prev;
}
public Node<E> getNext() {
return next;
}
public void setElement(E e) {
element = e;
}
public void setPrev(Node<E> p) {
prev = p;
}
public void setNext(Node<E> n) {
next = n;
}
}
// ----------- end of nested Node class ----------
private Node<E> header;
private Node<E> trailer;
private int size = 0;
/** Constructs a new empty list. */
public LinkedPositionalList(){
header = new Node<>(null,null,null);
trailer = new Node<>(null,header,null);
header.setNext(trailer);
}
// private utilities
// ** Validates the position and returns it as a node. */
private Node<E> validate(Position<E> p) throws IllegalArgumentException {
if (!(p instanceof Node)) throw new IllegalArgumentException("Invalid p");
Node<E> node = (Node<E>) p; // safe cast
// convention for defunct node
if (node.getNext() == null) throw new IllegalArgumentException("p is no longer in the list");
return node;
}
// ** Returns the given node as a Position (or null, if it is a sentinel). */
private Position<E> position(Node<E> node){
if(node == header || node == trailer) return null;
return node;
}
// public accessor methods
public int size() {return size;}
public boolean isEmpty() {return size==0;}
public Position<E> first() {return header.getNext();}
public Position<E> last() {return trailer.getPrev();}
public Position<E> before(Position<E> p) throws IllegalStateException {
Node<E> node = validate(p);
return node.getPrev();
}
public Position<E> after(Position<E> p) throws IllegalStateException {
Node<E> node = validate(p);
return node.getNext();
}
// private utilities
public Position<E> addBetween(E e, Node<E> prev, Node<E> succ) throws IllegalStateException {
Node<E> node = new Node<>(e, prev, succ);
prev.setNext(node);
succ.setPrev(node);
size++;
return node;
}
public Position<E> addLast(E e) {
return addBetween(e, trailer.getPrev(), trailer);
}
public Position<E> addFirst(E e) {
return addBetween(e, header, header.getNext());
}
public Position<E> addBefore(Node<E> p , E e) throws IllegalStateException {
Node<E> node = validate(p);
return addBetween(e, node.getPrev(), node);
}
public Position<E> addAfter(Node<E> p , E e) throws IllegalStateException {
Node<E> node = validate(p);
return addBetween(e, node, node.getNext());
}
public E set(Node<E> p , E e) throws IllegalStateException {
Node<E> node = validate(p);
E ans = node.getElement();
node.setElement(e);
return ans;
}
public E remove(Position<E> p) throws IllegalStateException {
Node<E> node = validate(p);
Node<E> prev = node.getPrev();
Node<E> next = node.getNext();
E ans = node.getElement();
prev.setNext(next);
next.setPrev(prev);
node.setElement(null);
node.setNext(null);
node.setPrev(null);
size--;
return ans;
}
}
LinkedPositionalList class (Array for Position)
- if are going to implement a positional list with an array, need a different approach.
- Instead of storing the elements of L directly in array A, store a new kind of position object in each cell of A.
- A position p stores the element e as well as the current index i of that element within the list.

- With this representation,
- can determine the index currently associated with a position,
- and can determine the position currently associated with a specific index.
- can therefore implement an accessor, such as before(p), by finding the index of the given position and using the array to find the neighboring position.
- When an element is inserted or deleted somewhere in the list, can loop through the array to update the index variable stored in all later positions in the list that are shifted during the update.
Efficiency Trade-Offs with an Array-Based Sequence
- the addFirst, addBefore, addAfter, and remove methods take O(n) time, because have to shift position objects to make room for the new position or to fill in the hole created by the removal of the old position (just as in the insert and remove methods based on index).
- All the other position-based methods take O(1) time.
Case Study: Maintaining Access Frequencies - Favorites list
The positional list ADT is useful in a number of settings.
example
- a program that simulates a game of cards could model each person’s hand as a positional list
- Since most people keep cards of the same suit together, inserting and
removing cards from a person’s handcould be implemented using the methods of the positional list ADT,- the positions being determined by a natural order of the suits.
- Likewise, a simple text editor embeds the notion of positional insertion and deletion, since such editors typically perform all updates relative to a cursor, which represents the current position in the list of characters of text being edited.
- consider
maintaining a collection of elementswhile keeping track ofthe number of times each element is accessed.- Keeping such access counts allows us to know which elements are among the most popular.
- Examples of such scenarios include
- a Web browser that keeps track of a user’s most accessed pages,
- or a music collection that maintains a list of the most frequently played songs for a user.
- model this with a new favorites list ADT that supports:
sizeandisEmptymethodsaccess(e): Accesses the element e, adding it to the favorites list if it is not already present, and increments its access count.remove(e): Removes element e from the favorites list, if present.getFavorites(k): Returns an iterable collection of the k most accessed elements.
Using a Sorted List
approach for managing a list of favorites
- store elements in a linked list, keeping them in nonincreasing order of access counts.
- access or remove an element by searching the list from the most frequently accessed to the least frequently accessed.
- Reporting the k most accessed elements is easy, as they are the first k entries of the list.
- The accessed element’s count increases by one, and so it may become larger than one or more of its preceding neighbors in the list, thereby violating the invariant.
- reestablish the sorted invariant using a technique similar to a single pass of the insertion-sort algorithm
- perform a backward traversal of the list, starting at the position of the element whose access count has increased, until locate a valid position after which the element can be relocated.
Using the Composition Pattern
- define a nonpublic nested class,
Item, that stores the element and its access count as a single instance. - maintain our
favorites listas aPositionalListof item instances, so that the access count for a user’s element is embedded alongside it in our representation. (An Item is never exposed to a user of a FavoritesList.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
package list;
/** Maintains a list of elements ordered according to access frequency. */
public class FavoritesList<E> {
// ---------------- nested Item class ----------------
protected static class Item<E> {
private E value;
private int count = 0;
// /∗∗ Constructs new item with initial count of zero. ∗/
public Item(E val) {value = val;}
public int getCount() {return count;}
public E getValue() {return value;}
public void increment() {count++;}
}
PositionalList<Item<E>> list = new LinkedPositionalList<>(); // list of Items
public FavoritesList() {} // constructs initially empty favorites list
// nonpublic utilities
/** Provides shorthand notation to retrieve user's element stored at Position p. */
protected E value(Position<Item<E>> p) {return p.getElement().getValue();}
/** Provides shorthand notation to retrieve count of item stored at Position p. */
protected int count(Position<Item<E>> p) {return p.getElement().getCount();}
/** Returns Position having element equal to e (or null if not found). */
protected Position<Item<E>> findPosition(E e) {
Position<Item<E>> walk = list.first();
while(walk!=null && e.equals((walk))) walk = list.after(walk);
return walk;
}
// /∗∗ Moves item at Position p earlier in the list based on access count. ∗/
protected void moveUp(Position<Item<E>> p) {
int cnt = count(p);
Position<Item<E>> walk = p;
while(walk!=null && count(list.before(walk))<cnt) walk = list.before(walk);
if(walk != p) list.addBefore(walk, list.remove(p));
}
// public methods
public int size(){return list.size();}
public Boolean isEmpty(){return list.isEmpty();}
// /∗∗ Accesses element e (possibly new), increasing its access count. ∗/
public void access(E e){
Position<Item<E>> p = findPosition(e);
if (p == null) list.addLast(new Item<E>(e));
p.getElement().increment();
moveUp(p);
}
// /∗∗ Removes element equal to e from the list of favorites (if found). ∗/
public void remove(E e){
Position<Item<E>> p = findPosition(e);
if (p != null) {
list.remove(p);
}
}
// /∗∗ Returns an iterable collection of the k most frequently accessed elements. ∗/
public Iterable<E> getFavorites(int k) throws IllegalArgumentException {
if (k < 0 || k > size()) throw new IllegalArgumentException("Invalid k");
PositionalList<E> result = new LinkedPositionalList<>();
Iterator<Item<E>> iter = list.iterator();
for (int j=0; j < k; j++) result.addLast(iter.next().getValue());
return result;
}
}
Using a List with the Move-to-Front Heuristic
favorites list performs the access(e) method in time proportional to the index of e in the favorites list.
- if e is the k th most popular element in the favorites list, then accessing it takes O(k) time.
locality of reference
- In many real-life access sequences (e.g., Web pages visited by a user),
- once an element is accessed it is more likely to be accessed again in the near future. Such scenarios are said to possess locality of reference.
move-to-front heuristic
- A heuristic that attempts to take advantage of the locality of reference that is present in an access sequence is the move-to-front heuristic.
- each time access an element move it all the way to the front of the list.
- Our hope, of course, is that this element will be accessed again in the near future.
example
- a scenario in which have n elements and the following series of n^2 accesses:
- element 1 is accessed n times
- element 2 is accessed n times
- ···
- element n is accessed n times.
- store the elements sorted by their access counts
- inserting each element the first time it is accessed, then
- each access to element 1 runs in O(1) time.
- each access to element 2 runs in O(2) time.
- ···
- each access to element n runs in O(n) time.
- use the move-to-front heuristic, inserting each element the first time it is accessed, then
- each subsequent access to element 1 takes O(1) time.
- each subsequent access to element 2 takes O(1) time.
- ···
- each subsequent access to element n runs in O(1) time.
- So the running time for performing all the accesses in this case is O(n2).
Trade-Offs with the Move-to-Front Heuristic
no longer maintain the elements of the favorites list ordered by their access counts -> when asked to find the k most accessed elements, need to search for them.
- will implement the getFavorites(k) method as follows:
- copy all entries of our favorites list into another list, named temp.
- scan the temp list k times.
- In each scan, find the entry with the largest access count, remove this entry from temp, and add it to the results.
- This implementation of method getFavorites(k) takes O(kn) time.
- when k is a constant, method getFavorites(k) runs in O(n) time, example, get the “top ten” list.
- if k is proportional to n, then the method getFavorites(k) runs in O(n^2) time. This occurs, for example, “top 25%” list.
introduce a data structure
- implement getFavorites in O(n + k log n) time
- more advanced techniques could be used to perform
getFavoritesinO(n + k log k)time. - achieve O(n log n) time if use a standard sorting algorithm to
reorder the temporary list before reporting the top k - this approach would be preferred to the original in the case that k is Ω(log n).
- (Recall the big-Omega notation introduced in Section 4.3.1 to give an asymptotic lower bound on the running time of an algorithm.)
- There is a specialized sorting algorithm that can take advantage of the fact that access counts are integers in order to achieve O(n) time for getFavorites, for any value of k.
Implementing the Move-to-Front Heuristic in Java
Iterators Interface
- a software design pattern that abstracts
the process of scanning through a sequence of elements, one element at a time. The underlying elements might be stored in a container class, streaming through a network, or generated by a series of computations.
- to unify the treatment and syntax for iterating objects in a way that is independent from a specific organization, Java defines the java.util.Iterator interface with the following two methods:
hasNext(): Returns true if there is at least one additional element in the sequence, and false otherwise.next(): Returns the next element in the sequence.- If the next( ) method of an iterator is called when no further elements are available, a
NoSuchElementExceptionis thrown.
- If the next( ) method of an iterator is called when no further elements are available, a
remove(): Removes from the collection the element returned by the most recent call to next(). Throws an IllegalStateException if next has not yet been called, or if remove was already called since the most recent call to next.
- The combination of these two methods allows a general loop construct for processing elements of the iterator.
Iterable Interface
Iterators
- A single iterator instance supports only one pass through a collection;
- calls to next can be made until all elements have been reported,
- but there is no way to “reset” the iterator back to the beginning of the sequence.
Iterable
- The Iterable Interface and Java’s For-Each Loop
- for a data structure that wishes to allow repeated iterations can support a method that returns a new iterator, each time it is called.
- Java defines another parameterized interface, named Iterable, that includes the following single method:
iterator(): Returns an iterator of the elements in the collection.
example
- An instance of a typical collection class in Java, such as an ArrayList, is iterable (but not itself an iterator);
- it produces an iterator for its collection as the return value of the
iterator()method. - Each call to iterator() returns a new iterator instance, thereby allowing multiple (even simultaneous) traversals of a collection.
“for-each” loop syntax
- Java’s Iterable class also plays a fundamental role in support of the “for-each” loop syntax
- The loop is supported for any instance, collection, of an iterable class.
- ElementType must be the type of object returned by its iterator,
- and variable will take on element values within the loopBody.
1
2
3
4
5
6
7
8
9
10
for (ElementType variable : collection) {
loopBody // may refer to ”variable”
}
// Essentially, this syntax is shorthand for the following:
Iterator<ElementType> iter = collection.iterator();
while (iter.hasNext()) {
ElementType variable = iter.next();
loopBody // may refer to ”variable”
}
iterator’s remove method
- the iterator’s remove method cannot be invoked when using the for-each loop syntax.
- Instead, must explicitly use an iterator.
- example
- the following loop can be used to remove all negative numbers from an ArrayList of floating-point values.
1
2
3
4
ArrayList<Double> data; // populate with random numbers (not shown)
Iterator<Double> walk = data.iterator();
while (walk.hasNext())
if (walk.next() < 0.0) walk.remove( );
Implementing Iterators
There are two general styles for implementing iterators that differ in terms of
what work is done when the iterator instance is first created, andwhat work is done each time the iterator is advanced with a call to next().- snapshot iterator
- snapshot iterator maintains its own private copy of the sequence of elements, which is constructed at the time the iterator object is created.
- It effectively records a “snapshot” of the sequence of elements at the time the iterator is created
- is therefore unaffected by any subsequent changes to the primary collection that may occur.
- Implementing snapshot iterators tends to be very easy, as it requires a simple traversal of the primary structure.
- The downside of this style of iterator is that it requires O(n) time and O(n) auxiliary space, upon construction, to copy and store a collection of n elements.
- lazy iterator
- lazy iterator is one that does not make an upfront copy, instead performing a piecewise traversal of the primary structure only when the next() method is called to request another element.
- The advantage of this style of iterator is that it can typically be implemented so the iterator requires only
O(1)space andO(1)construction time. - One downside (or feature) of a lazy iterator is that
its behavior is affected if the primary structure is modified(by means other than by the iterator’s own remove method) before the iteration completes. - Many of the iterators in Java’s libraries implement a “fail-fast” behavior that immediately invalidates such an iterator if its underlying collection is modified unexpectedly.
iterators for ArrayList
iteration for the
ArrayList<E> class.- have it implement the
Iterable<E> interface - must add an
iterator() methodto that class definition, which returns an instance of an object that implements theIterator<E> interface.- define a new class,
ArrayIterator, as a nonstatic nested class of ArrayList
- define a new class,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public class ArrayList<E> implements List<E> { // instance variables {
...
public Iterator<E> iterator(){
return new ArrayIterator();
}
//---------------- nested ArrayIterator class ----------------
/**
* A (nonstatic) inner class. Note well that each instance contains an implicit
* reference to the containing list, allowing it to access the list's members.
*/
private class ArrayIterator implements Iterator<E> {
private int j=0;
private boolean removable = false;
/**
* Tests whether the iterator has a next object.
* @return true if there are further objects, false otherwise
*/
public boolean hasNext() {return j<size;}
public E next() throws NoSuchElementException{
if(j==size) throw new NoSuchElementException("No next element.");
removable=true;
return data[j++];
}
public void remove() throws IllegalStateException{
if(!removable) throw new IllegalStateException("nothing to remove");
ArrayList.this.remove(j-1);
j--;
removable = false;
}
}
}
iterators for LinkedPositionalList
- a first question is whether to support iteration of the
elementsof the list or thepositionsof the list.- iterate through all positions of the list, those positions could be used to access the underlying elements, so support for position iteration is more general.
- it is more standard for a container class to support iteration of the core elements, by default, so that the for-each loop syntax could be used to write code such as the following,
for (String guest : waitlist)
- assuming that variable waitlist has type
LinkedPositionalList<String> - For maximum convenience, will support both forms of iteration.
- have the standard
iterator() method- return an iterator of the elements of the list
- so that list class formally implements the Iterable interface for the declared element type.
- provide a new
method, positions()- to iterate through the positions of a list
- At first glance, it would seem a natural choice for such a method to return an Iterator.
- However, prefer for the return type of that method to be an instance that is Iterable (and hence, has its own iterator() method that returns an iterator of positions).
- Our reason for the extra layer of complexity is that wish for users of our class to be able to use a for-each loop with a simple syntax such as the following:
for (Position<String> p : waitlist.positions())
- have the standard
new support for the iteration of positions and elements of a LinkedPositionalList.
- define three new inner classes.
PositionIterator- providing the core functionality of our list iterations.
- Whereas the array list iterator maintained the index of the next element to be returned as a field,
- this class maintains the position of the next element to be returned (as well as the position of the most recently returned element, to support removal).
- define a trivial
PositionIterableinner class,- To support our goal of the positions() method returning an Iterable object
- which simply constructs and returns a new
PositionIteratorobject each time itsiterator() methodis called. - The positions() method of the top-level class returns a new
PositionIterableinstance. - Our framework relies heavily on these being inner classes, not static nested classes.
iterator() method- the top-level iterator() method return an iterator of elements (not positions).
- Rather than reinvent the wheel, trivially adapt the PositionIterator class to define a new ElementIterator class, which lazily manages a position iterator instance, while returning the element stored at each position when next() is called.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
public class LinkedPositionalList<E> implements PositionalList<E> {
private static class Node<E> implements Position<E>{}
// ----------- end of nested Node class ----------
private Node<E> header;
private Node<E> trailer;
private int size = 0;
/** Constructs a new empty list. */
public LinkedPositionalList(){}
/** Returns an iterable representation of the list's positions. */
public Iterable<Position<E>> positions( ) {
return new PositionIterable(); // create a new instance of the inner class
}
//---------------- nested PositionIterable class ----------------
private class PositionIterable implements Iterable<Position<E>> {
public Iterator<Position<E>> iterator() {return new PositionIterator();}
}
//---------------- nested PositionIterator class ----------------
private class PositionIterator implements Iterator<Position<E>> {
private Position<E> cursor = first(); // position of the next element to report
private Position<E> recent = null; // position of last reported element
public boolean hasNext(){return cursor!=null;}
public Position<E> next() throws NoSuchElementException{
if(cursor==null) throw new NoSuchElementException("nothing left");
recent = cursor;
cursor = after(cursor);
return recent;
}
public void remove() throws NoSuchElementException{
if(recent==null) throw new NoSuchElementException("nothing to remove");
LinkedPositionalList.this.remove(recent); // remove from outer list
recent = null; // do not allow remove again until next is called
}
}
/** Returns an iterator of the elements stored in the list. */
public Iterator<E> iterator( ) {
return new ElementIterator( );
}
//---------------- nested ElementIterator class ----------------
private class ElementIterator implements Iterator<E> {
Iterator<Position<E>> posIterator = new PositionIterator();
public boolean hasNext(){return posIterator.hasNext();}
public E next() {return posIterator.next().getElement();}
public void remove() {posIterator.remove();}
}
}
Collection Interface
- The root interface in the Java collections framework is named Collection.
a general interface for any data structure, such as a list, that represents
a collection of elements.The Collection interface includes many methods
- It is a superinterface for other interfaces in the Java Collections Framework that can hold elements, including the java.util interfaces Deque, List, and Queue, and other subinterfaces discussed later in this book, including Set and Map.

List Iterators in Java
The
java.util.LinkedListclass does not expose a position concept to users in its API, as do in our positional list ADT.Instead, the preferred way to access and update a
LinkedListobject in Java, without using indices, is to use aListIteratorthat is returned by the list’slistIterator()method.- Such an iterator provides forward and backward traversal methods as well as local update methods.
- It views its current position as being before the first element, between two elements, or after the last element.
- That is, it uses a list cursor, being located between two characters on a screen.
the java.util.ListIterator interface includes the following methods:
- add(e):
- hasNext():
- hasPrevious():
- previous():
- next():
- nextIndex():
- previousIndex():
- remove():
set(e):
It is risky to use multiple iterators over the same list while modifying its contents. If insertions, deletions, or replacements are required at multiple “places” in a list, it is safer to use positions to specify these locations.
- But the java.util.LinkedList class does not expose its position objects to the user.
- to avoid the risks of modifying a list that has created multiple iterators, the
iteratorshave a “fail-fast” feature that invalidates such an iterator if its underlying collection is modified unexpectedly. - For example,
- if a java.util.LinkedList object L has returned five different
iteratorsand one of them modifies L, aConcurrentModificationExceptionis thrown if any of the other four is subsequently used.
- to avoid the risks of modifying a list that has created multiple iterators, the
- Java allows many list
iteratorsto be traversing a linked list L at the same time,- but if one of them modifies L (using an add, set, or remove method),
- then all the other iterators for L become invalid.
- Likewise, if L is modified by one of its own update methods, then all existing iterators for L immediately become invalid.
Comparison to Our Positional List ADT
corresponding methods between our (array and positional) list ADTs and the java.util interfaces List and ListIterator interfaces,

List-Based Algorithms in the Java Collections Framework
copy(Ldest , Lsrc): Copies all elements of the Lsrc list into corresponding in- dices of the Ldest list.disjoint(C, D): Returns a boolean value indicating whether the collections C and D are disjoint.fill(L, e): Replaces each element of the list L with element e.frequency(C, e): Returns the number of elements in the collection C that are equal to e.max(C): Returns the maximum element in the collection C, based on the natural ordering of its elements.min(C): Returns the minimum element in the collection C, based on the natural ordering of its elements.replaceAll(L, e, f ):- Replaces each element in L that is equal to e with element f .
reverse(L): Reverses the ordering of elements in the list L.rotate(L, d): Rotates the elements in the list L by the distance d (which can be negative), in a circular fashion.shuffle(L): Pseudorandomly permutes the ordering of the elements in the list L.sort(L): Sorts the list L, using the natural ordering of its elements.swap(L, i, j): Swap the elements at indices i and j of list L.
Converting Lists into Arrays
Lists are a beautiful concept and they can be applied in a number of different contexts,
- but there are some instances where it would be useful if could treat a list like an array.
java.util.Collectioninterface includes the following helpful methods for generating an array that has the same elements as the given collection:toArray():- Returns an array of elements of type Object containing all the elements in this collection.
toArray(A):- Returns an array of elements of the same element type as A containing all the elements in this collection.
- If the collection is a list, then the returned array will have its elements stored in the same order as that of the original list.
Converting Arrays into Lists
- it is often useful to be able to convert an array into an equivalent list.
java.util.Arraysclass includes the following method:asList(A):- Returns a list representation of the array A, with the same element type as the elements of A.
- The list returned by this method
uses the array A as its internal representationfor the list.- So this list is guaranteed to be an array-based list
- any changes made to it will automatically be reflected in A.
- Because of these types of side effects, use of the
asListmethod should always be done with caution, so as to avoid unintended consequences. - But, used with care, this method can often save us a lot of work.
- For instance
- to randomly shuffle an array of Integer objects:
1
2
3
Integer[] arr = {1, 2, 3, 4, 5, 6, 7, 8}; // allowed by autoboxing
List<Integer> listArr = Arrays.asList(arr);
Collections.shuffle(listArr); // this has side effect of shuffling arr
Stack
- a collection of elements, with two principle operations:
push, which adds to the collection,pop, which removes the most recently added element
- “push-down stack”
- an
ordered collection of items - the addition and the removal always takes place at the same end.
- This end is commonly referred to as the “top” and “base”
Stack is a linear data structure
- Abstract Data Type
- follows a particular order in which the operations are performed.
- LIFO(Last In First Out), FILO(First In Last Out).
LIFO, last-in first-out
- items stored closer to the
base, been in the stack the longest. - The most recently added item, be removed first.
- It provides an ordering
based on length of timein the collection. - Newer items are near the top, while older items are near the base.
Stacks are fundamentally important, as they can be used to reverse the order of items.
- The order of insertion is the reverse of the order of removal.
- every web browser’s Back button. url in stack




java
1
2
3
4
5
push(e) // O(1)
pop() // O(1)
top() // O(1)
size() // O(1)
isEmpty() // O(1)
Time Complexity
- Access: O(n)
- Search: O(n)
- Insert: O(1)
- Remove: O(1)
space usage
- Performance of a stack realized by an array.
The space usage is O(N),
In order to formalize abstraction of a stack, define its
application programming interface (API)in the form of a Javainterface, which describes the names of the methods that the ADT supports and how they are to be declared and used.rely on Java’s generics framework, allowing the elements stored in the stack to belong to any object
type <E>. The formal type parameter is used as the parameter type for the push method, and the return type for both pop and top.- Because of the importance of the stack ADT, Java has included a concrete class named
java.util.Stackthat implements the LIFO semantics of a stack.- However, Java’s Stack class remains only for historic reasons, and its interface is not consistent with most other data structures in the Java library.
- the current documentation for the Stack class recommends that it not be used, as LIFO functionality (and more) is provided by a more general data structure double-ended queue

1
2
3
4
5
6
7
public interface Stack<E> {
int size();
boolean isEmpty();
viod push(E e);
E top();
E pop();
}
Array-Based Stack
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public class ArrayStack<E> implements Stack<E> {
public static final int CAPACITY = 1000;
private E[] data;
private int t = -1;
public ArrayStack() { this(CAPACITY); }
public ArrayStack(int capacity) {
data = (E[]) new Object[capacity];
}
public int size() {return (t+1);}
public boolean isEmpty() {return t==-1;}
public void push(E e) throws IllegalStateException {
if(size()==data.length) throw new IllegalStateException("Stack is full");
data[++t] = e;
}
public E top(){
return isEmpty()? null: data[t];
}
public E pop(){
if(isEmpty()) return null;
E ans = data[t];
data[t] = null;
t--;
return E;
}
}
Stack<Integer> S = new ArrayStack<>();
Garbage Collection in Java
- the implementation of the
popmethod, set a local variable, answer, to reference the element that is being popped, and then resetdata[t] to nullbefore decrementing t. The assignment to null was not technically required, as our stack would still operate correctly without it.
- Our reason for returning the cell to a null reference is to assist Java’s garbage collection mechanism,
- searches memory for objects that are no longer actively referenced and reclaims their space for future use.
- If continued to store a reference to the popped element in our array, the stack class would ignore it (eventually overwriting the reference if more elements get added to the stack).
- But, if there were no other active references to the element in the user’s application, that spurious reference in the stack’s array would stop Java’s garbage collector from reclaiming the element.
Drawback of Array-Based Stack
Drawback of This Array-Based Stack Implementation
- one negative aspect
it relies on a fixed-capacity array, which limits the ultimate size of the stack.
- where a user has a good estimate on the number of items needing to go in the stack, the array-based implementation is hard to beat.
two approaches for implementing a stack without such a size limitation and with space always proportional to the actual number of elements stored in the stack.
- One approach, singly linked list for storage;
- more advanced array-based approach that overcomes the limit of a fixed capacity.
Singly Linked List
Unlike our array-based implementation, the linked-list approach
has memory usage that is always proportional to the number of actual elementscurrently in the stack, andwithout an arbitrary capacity limit.since can insert and delete elements in constant time only at the front. With the top of the stack stored at the front of the list, all methods execute in constant time.
The Adapter Pattern
The adapter design pattern applies to any context where effectively want to modify
an existing class so that its methodsmatch those of a related, but different, class or interface.One general way to apply the adapter pattern is to define a new class in such a way that it contains an instance of the existing class as a hidden field, and then to implement each method of the new class using methods of this hidden instance variable.
- By applying the adapter pattern in this way, have created a new class that performs some of the same functions as an existing class, but repackaged in a more convenient way.
- In the context of the stack ADT, adapt our SinglyLinkedList class to define a new LinkedStack class
- This class declares a SinglyLinkedList named list as a private field

1
2
3
4
5
6
7
8
9
10
public class LinkedStack<E> implements Stack<E> {
private SinglyLinkedList<E> list = new SinglyLinkedList<>(); // an empty list
public LinkedStack() { } // new stack relies on the initially empty list
public int size() { return list.size(); }
public boolean isEmpty() { return list.isEmpty(); }
public void push(E element) { list.addFirst(element); }
public E top() { return list.first(); }
public E pop() { return list.removeFirst(); }
}
Python
Stack()- creates a new stack that is empty.
- It needs no parameters and returns an empty stack.
push(item):- adds a new item to the top of the stack
- It needs the item and returns nothing.
- If the stack is full, Overflow condition.
pop():- removes the top item from the stack
- It needs no parameters and returns the item
- The stack is modified.
- If the stack is empty, Underflow condition.
peek()orTop:- Returns top element of stack, but does not remove it
- It needs no parameters.
- The stack is not modified.
is_empty():- Returns true if stack is empty, else false.
- It needs no parameters and returns a boolean value.
size()- returns the number of items on the stack.
- It needs no parameters and returns an integer
code
Stack <- list (!!!!!!!!!!!!!)
consider the performance of the two implementations, there is definitely a difference.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
## Stack implementation as a list
## the end is at the beginning
class Stack:
"""Stack implementation as a list"""
def __init__(self): self.items = []
def is_empty(self): return not bool(self.items)
def push(self, item): self.items.append(item)
def pop(self): return self.items.pop()
# append() and pop() operations were both O(1)
def peek(self): return self.items[-1]
def size(self): return len(self.items)
## the top is at the beginning
class Stack:
def __init__(self): self.items = []
def isEmpty(self): return self.items == []
def push(self, item): self.items.insert(0,item)
def pop(self): return self.items.pop(0)
# will both require O(n) for a stack of size n.
def peek(self): return self.items[0]
def size(self): return len(self.items)
from pythonds3.basic import Stack
s = Stack()
stack in java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
class Stack {
static final int MAX = 1000;
int top;
int a[] = new int[MAX]; // Maximum size of Stack
boolean isEmpty() {
return (top < 0);
}
Stack() {
top = -1; // empty: top is -1
}
// add item
boolean push(int x) {
if (top >= (MAX - 1)) {
System.out.println("Stack Overflow");
return false;
}
else {
a[++top] = x;
System.out.println(x + " pushed into stack");
return true;
}
}
int pop() {
if (top < 0) {
System.out.println("Stack Underflow");
return 0;
}
else {
int x = a[top--];
return x;
}
}
int peek() {
if (top < 0) {
System.out.println("Stack Underflow");
return 0;
}
else {
int x = a[top];
return x;
}
}
}
// Driver code
class Main {
public static void main(String args[]) {
Stack s = new Stack();
s.push(10);
s.push(20);
s.push(30);
System.out.println(s.pop() + " Popped from stack");
}
}
Stack <- Linked List
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
public class StackAsLinkedList {
StackNode root;
static class StackNode {
int data;
StackNode next;
StackNode(int data) {
this.data = data;
}
}
public boolean isEmpty() {
if (root == null) {
return true;
}
else
return false;
}
public void push(int data) {
StackNode newNode = new StackNode(data);
if (root == null) {
root = newNode;
}
else {
StackNode temp = root;
root = newNode;
newNode.next = temp;
}
System.out.println(data + " pushed to stack");
}
public int pop() {
int popped = Integer.MIN_VALUE;
if (root == null) {
System.out.println("Stack is Empty");
}
else {
popped = root.data;
root = root.next;
}
return popped;
}
public int peek() {
if (root == null) {
System.out.println("Stack is empty");
return Integer.MIN_VALUE;
}
else {
return root.data;
}
}
public static void main(String[] args) {
StackAsLinkedList sll = new StackAsLinkedList();
sll.push(10);
sll.push(20);
sll.push(30);
System.out.println(sll.pop() + " popped from stack");
System.out.println("Top element is " + sll.peek());
}
}
Stack Class in Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// Java code for stack implementation
import java.io.*;
import java.util.*;
class Test {
// Pushing element on the top of the stack
static void stack_push(Stack<Integer> stack) {
for(int i = 0; i < 5; i++) {
stack.push(i);
}
}
// Popping element from the top of the stack
static void stack_pop(Stack<Integer> stack) {
System.out.println("Pop :");
for(int i = 0; i < 5; i++) {
Integer y = (Integer) stack.pop();
System.out.println(y);
}
}
// Displaying element on the top of the stack
static void stack_peek(Stack<Integer> stack) {
Integer element = (Integer) stack.peek();
System.out.println("Element on stack top : " + element);
}
// Searching element in the stack
static void stack_search(Stack<Integer> stack, int element) {
Integer pos = (Integer) stack.search(element);
if(pos == -1)
System.out.println("Element not found");
else
System.out.println("Element is found at position " + pos);
}
}
reverse char in string
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from test import testEqual
from pythonds.basic.stack import Stack
def rev_string(my_str):
s = Stack()
revstr=''
for char in my_str:
s.push(char)
while not s.is_empty():
revstr += s.pop()
return revstr
print(rev_string('apple'))
testEqual(rev_string('x'), 'x')
testEqual(rev_string('abc'), 'cba')
1
2
3
4
5
6
7
8
9
public class Reversestring {
public String reverseString(String s){
String result = "";
for(int i = 0; i < s.length(); i++){
result = s.charAt(i) + result;
}
return result;
}
}
simple Balanced Parentheses

Balanced Symbols (A General Case)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from pythonds.basic import Stack
def parChecker(symbolString):
s = Stack()
balanced = True
index = 0
while index < len(symbolString) and balanced:
symbol = symbolString[index]
if symbol in "([{":
s.push(symbol)
else:
if s.isEmpty():
balanced = False
else:
top = s.pop()
if not matches(top,symbol):
balanced = False
index = index + 1
if balanced and s.isEmpty():
return True
else:
return False
def matches(open,close):
opens = "([{"
closers = ")]}"
return opens.index(open) == closers.index(close)
convert-integer-into-different-base

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
## The decimal number 233(10) and its corresponding binary equivalent 11101001(2) are interpreted respectively as
## 2×10^2+3×10^1+3×10^0
## and
## 1×2^7+1×2^6+1×25+0×24+1×23+0×22+0×21+1×20
## convert-integer-into-base(16)
## Class solution1: stack, put num%16 in stack
def divide_by_base(num, base):
digits = "0123456789ABCDEF"
s = Stack()
while num > 0:
rem = num % base
s.push(rem)
num = num // base
ans_string = ""
while not s.is_empty():
ans_string += str(digits[s.pop()])
return ans_string
print(divide_by_base(25,2))
print(divide_by_base(25,16))
print(divide_by_base(25,8))
print(divide_by_base(256,16))
print(divide_by_base(26,26))
## convert-integer-into-binary
## Class solution1: stack, put num%2 in stack
def divide_by_2(decimal_num):
s = Stack()
while decimal_num > 0:
rem = decimal_num % 2
s.push(rem)
decimal_num = decimal_num // 2
bin_string = ""
while not s.is_empty():
bin_string += str(s.pop())
return bin_string
## print(divide_by_2(42))
## print(divide_by_2(31))
Infix, Prefix, and Postfix Expressions
computers need to know exactly what operators to perform and in what order.
- infix:
- 中缀
(A+B)*C - the operator is in between the two operands that it is working on.
- 中缀
- Prefix:
- 前缀
(*+ABC) - all operators precede the two operands that they work on.
- 前缀
- Postfix:
- 后缀
(AB+C*) - operators come after the corresponding operands.
- 后缀

fully parenthesized expression: uses one pair of parentheses for each operator.
A + B * C + D->((A + (B * C)) + D)A + B + C + D->(((A + B) + C) + D)
- Conversion of Infix to Prefix and Postfix

- Infix-to-Postfix Conversion

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
## use stack
## (A+B+D)*C -> (AB+D+)C*
## A*B+C*D -> AB*+CD*
def infixToPostfix(infixexpr):
# Assume the infix expression is a string of tokens delimited by spaces.
# The operator tokens are *, /, +, and -, along with the left and right parentheses, ( and ).
# The operand tokens are the single-tokenacter identifiers A, B, C, and so on.
# The following steps will produce a string of tokens in postfix order.
prec = {'*':3, '/':3, '+':2, '-':2, '(':1}
operand_tokens = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
# Create an empty stack called opStack for keeping operators. Create an empty list for output.
opStack = Stack()
postfixList = []
# Convert the input infix string to a list by using the string method split.
token_list =infixexpr.split()
# Scan the token list from left to right.
for token in token_list:
# If the token is an operand, append it to the end of the output list.
if token in operand_tokens:
postfixList.append(token)
print("postfixList.append:", token, "add operand")
# If the token is a left parenthesis, push it on the opStack.
elif token == '(':
opStack.push(token)
print("opStack.push:", token)
# If the token is a right parenthesis,
# pop the opStack until the corresponding left parenthesis is removed.
# Append each operator to the end of the output list.
elif token == ')':
topToken = opStack.pop()
print("opStack.pop:", token)
while topToken != '(':
postfixList.append(topToken)
print("postfixList.append:", token, postfixList)
topToken = opStack.pop()
# If the token is an operator, *, /, +, or -, push it on the opStack.
# However, first remove any operators already on the opStack that have higher or equal precedence and append them to the output list.
else:
while (not opStack.isEmpty()) and (prec[opStack.peek()] >= prec[token]):
postfixList.append(opStack.pop())
print("postfixList.append:", token, postfixList)
opStack.push(token)
print("opStack.push:", token)
# When the input expression has been completely processed, check the opStack. Any operators still on the stack can be removed and appended to the end of the output list.
while not opStack.isEmpty():
out = opStack.pop()
postfixList.append(out)
print("postfixList.append:", out, postfixList)
return " ".join(postfixList)
print(infixToPostfix("( A + B ) * C"))
print(infixToPostfix("A * B + C * D"))
print(infixToPostfix("( A + B ) * C - ( D - E ) * ( F + G )"))
- Postfix Evaluation


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
## use stack -> calculate Postfix
def postfixEval(postfixExpr):
# Create an empty stack called operandStack.
operandStack = Stack()
# Convert the string to a list by using the string method split.
token_list = postfixExpr.split()
# Scan the token list from left to right.
for token in token_list:
# If the token is an operand, convert it from a string to an integer and push the value onto the operandStack.
if token in "0123456789":
operandStack.push(int(token))
# If the token is an operator, *, /, +, or -, it will need two operands. Pop the operandStack twice.
# The first pop is the second operand and the second pop is the first operand.
# Perform the arithmetic operation.
# Push the result back on the operandStack.
else:
second_ope = operandStack.pop()
first_ope = operandStack.pop()
result = doMath(token, first_ope, second_ope)
print(first_ope, token, second_ope, result)
operandStack.push(result)
# When the input expression has been completely processed, the result is on the stack. Pop the operandStack and return the value.
return operandStack.pop()
def doMath(op, op1, op2):
if op == "*": return op1 * op2
elif op == "/": return op1 / op2
elif op == "+": return op1 + op2
else: return op1 - op2
## print(postfixEval('7 8 + 3 2 + /'))
## print(postfixEval('17 10 + 3 * 9 /'))
Queue

Queue
- FIFO: first in first out.
- only change from 2 side. no insert!!
- front : rear
- used when
things don’t have to be processed immediatly, buthave to be processed in First In First Out orderlike Breadth First Search. - This property of Queue makes it useful in following kind of scenarios.
- printing queues,
- operating systems use different queues to control processes
- keystrokes are being placed in a queue-like buffer so that they can eventually be displayed on the screen in the proper order.
- When a resource is shared among multiple consumers.
- Examples include CPU scheduling, Disk Scheduling.
- When data is transferred asynchronously (data not necessarily received at same rate as sent) between two processes.
- Examples include IO Buffers, pipes, file IO, etc.

- a collection of elements,
- supporting two principle operations:
- enqueue, which inserts an element into the queue,
- dequeue, which removes an element from the queue
Time Complexity:
- Access: O(n)
- Search: O(n)
- Insert: O(1)
Remove: O(1)
Queue()- creates a new queue that is empty.
- It needs no parameters and returns an empty queue.
enqueue(item)𝑂(𝑛)- adds a new item to the rear of the queue.
- It needs the item and returns nothing.
dequeue()𝑂(1)- removes the front item from the queue.
- It needs no parameters and returns the item.
- The queue is modified.
first():- Returns the first element of the queue, without removing it (or null if the queue is empty).
size():- Returns the number of elements in the queue.
isEmpty():- Returns a boolean indicating whether the queue is empty.
is_empty()- tests to see whether the queue is empty.
- It needs no parameters and returns a boolean value.
size()- returns the number of items in the queue.
- It needs no parameters and returns an integer.
Java
1
2
3
4
5
6
7
public interface Queue<E> {
int size();
boolean isEmpty();
void enqueue(E e);
E first();
E dequeue();
}
The java.util.Queue Interface in Java
- Java provides a type of queue interface, java.util.Queue, which has functionality similar to the traditional queue ADT, given above, but the documentation for the java.util.Queue interface does not insist that it support only the FIFO principle.
When supporting the FIFO principle, the methods of the java.util.Queue interface have the equivalences with the queue ADT shown in Table 6.3.
The java.util.Queue interface supports two styles for most operations, which vary in the way that they treat exceptional cases.
When a queue is empty, the remove() and element() methods throw a NoSuchElementException, while the corresponding methods poll() and peek() return null.
- For implementations with a bounded capacity, the add method will throw an IllegalStateException when full, while the offer method ignores the new element and returns false to signal that the element was not accepted.
Array-Based Queue
implemented the LIFO semantics of the Stack ADT using an array (albeit, with a fixed capacity), such that every operation executes in constant time.
enqueue: as elements are inserted into a queue, store them in an array such that the first element is at index 0, the second element at index 1, and so on.dequeue: implement the dequeue operation. The element to be removed is stored at index 0 of the array.- One strategy is to execute a loop to shift all other elements of the queue one cell to the left, so that the front of the queue is again aligned with cell 0 of the array. Unfortunately, the use of such a loop would result in an O(n) running time for the dequeue method.
- avoiding the loop entirely. replace a dequeued element in the array with a null reference, and maintain an explicit variable f to represent the index of the element that is currently at the front of the queue. Such an algorithm for dequeue would run in O(1) time. However, there remains a challenge with the revised approach. With an array of capacity N, should be able to store up to N elements before reaching any exceptional case. If repeatedly let the front of the queue drift rightward over time, the back of the queue would reach the end of the underlying array even when there are fewer than N elements currently in the queue. must decide how to store additional elements in such a configuration.
Circularly Array-Based Queue
Implementing such a circular view is relatively easy with the modulo operator, denoted with the symbol % in Java.
The modulo operator is ideal for treating an array circularly.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public class ArrayQueue<E> implements Queue<E> {
private E[] data;
private int f=0;
private int sz=0;
// constructors
public ArrayQueue(){ this(CAPACITY); }
public ArrayQueue(int capacity){
data = new Object[capacity];
}
public int size() {return sz;}
public boolean isEmpty() {return sz==0;}
public void enqueue(E e) throws IllegalStateException {
if(sz==data.length) throw new IllegalStateException("Queue is full");
int avail = (f+sz)%data.length;
data[avail] = e;
sz++;
}
public E first() {
return isEmpty()? null: data[f];
}
// /** Removes and returns the first element of the queue (null if empty). */
public E dequeue() {
if(isEmpty()) return null;
E ans = data[f];
data[f] = null;
f = (f+1)% data.length;
sz--;
return ans;
}
}
Analyzing the Efficiency of an Array-Based Queue
- size: O(1)
- isEmpty: O(1)
- first: O(1)
- enqueue: O(1)
- dequeue: O(1)
Singly Linked List for Queue
1
2
3
4
5
6
7
8
9
10
public class LinkedQueue implements Queue<E> {
private SinglyLinkedList<E> list = new SinglyLinkedList<>();
public LinkedQueue(){}
public int size(){return list.size();}
public boolean isEmpty(){return list.isEmpty();}
public void enqueue(E e){list.addLast(e);}
public E first(){return list.first();}
public E dequeue(){return list.removeFirst();}
}
Analyzing the Efficiency of an Singly Linked List-Based Queue
adapt a singly linked list to implement the queue ADT while supporting worst-case O(1)-time for all operations, and without any artificial limit on the capacity.
each method of that class runs in O(1) worst-case time. Therefore, each method of our LinkedQueue adaptation also runs in O(1) worst-case time.
- also
avoid the need to specify a maximum size for the queue, as was done in the array-based queue implementation. However, this benefit comes with some expense.
Because each node stores a next reference, in addition to the element reference, a linked list uses more space per element than a properly sized array of references.
Also, although all methods execute in constant time for both implementations, it seems clear that the operations involving linked lists have a large number of primitive operations per call.
- For example,
- adding an element to an array-based queue consists primarily of calculating an index with modular arithmetic, storing the element in the array cell, and incrementing the size counter.
- For a linked list, an insertion includes the instantiation and initialization of a new node, relinking an existing node to the new node, and incrementing the size counter.
- In practice, this makes the linked-list method more expensive than the array-based method.
circularly linked list for Queue
circularly linked list class that supports all behaviors of a singly linked list, and an additional rotate() method that efficiently moves the first element to the end of the list.
generalize the Queue interface to define a new CircularQueue interface with such a behavior
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public interface CircularQueue<E> extends Queue<E> {
void rotate();
}
public class LinkedCircularQueue implements CircularQueue<E> {
private SinglyLinkedList<E> list = new SinglyLinkedList<>();
public LinkedCircularQueue(){}
public int size(){return list.size();}
public boolean isEmpty(){return list.isEmpty();}
public void enqueue(E e){list.addLast(e);}
public E first(){return list.first();}
public E dequeue(){return list.removeFirst();}
public void rotate(){list.}
}
- This interface can easily be implemented by adapting the CircularlyLinkedList class of Section 3.3 to produce a new LinkedCircularQueue class.
This class has an advantage over the traditional LinkedQueue, because a call to Q.rotate() is implemented more efficiently than the combination of calls, Q.enqueue(Q.dequeue()), because no nodes are created, destroyed, or relinked by the implementation of a rotate operation on a circularly linked list.
- A circular queue is an excellent abstraction for applications in which elements are cyclically arranged, such as for multiplayer, turn-based games, or round-robin scheduling of computing processes. In the remainder of this section, provide a demonstration of the use of a circular queue.
python
queue as a list (!!!!!!!!!!!!!)
1
2
3
4
5
6
class Queue:
def __init__(self): self.items = []
def is_empty(self): return not bool(self.items)
def enqueue(self, item): self.items.insert(0, item)
def dequeue(self): return self.items.pop()
def size(self): return len(self.items)
queue in java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
// A class to represent a queue
class Queue {
int front, rear, size;
int capacity;
int array[];
public Queue(int capacity) {
this.capacity = capacity;
front = this.size = 0;
rear = capacity - 1;
array = new int[this.capacity];
}
// Queue is full when size becomes equal to the capacity
boolean isFull(Queue queue) {
return (queue.size == queue.capacity);
}
// Queue is empty when size is 0
boolean isEmpty(Queue queue) {
return (queue.size == 0);
}
// Method to add an item to the queue.
// It changes rear and size
void enqueue(int item) {
if (isFull(this))
return;
this.rear = (this.rear + 1) % this.capacity;
this.array[this.rear] = item;
this.size = this.size + 1;
System.out.println(item + " enqueued to queue");
}
// Method to remove an item from queue.
// It changes front and size
int dequeue() {
if (isEmpty(this))
return Integer.MIN_VALUE;
int item = this.array[this.front];
this.front = (this.front + 1) % this.capacity;
this.size = this.size - 1;
return item;
}
// Method to get front of queue
int front() {
if (isEmpty(this))
return Integer.MIN_VALUE;
return this.array[this.front];
}
// Method to get rear of queue
int rear() {
if (isEmpty(this))
return Integer.MIN_VALUE;
return this.array[this.rear];
}
}
// Driver class
public class Test {
public static void main(String[] args) {
Queue queue = new Queue(1000);
queue.enqueue(10);
queue.enqueue(20);
queue.enqueue(30);
queue.enqueue(40);
System.out.println(queue.dequeue() + " dequeued from queue\n");
System.out.println("Front item is " + queue.front());
System.out.println("Rear item is " + queue.rear());
}
}
// Output:
// 10 enqueued to queue
// 20 enqueued to queue
// 30 enqueued to queue
// 40 enqueued to queue
// 10 dequeued from queue
// Front item is 20
// Rear item is 40
Simulation: Printing Tasks

- students send printing tasks to the shared printer,
- the tasks are placed in a queue to be processed in a first-come first-served manner.
- Many questions arise with this configuration. The most important of these might be whether the printer is capable of handling a certain amount of work. If it cannot, students will be waiting too long for printing and may miss their next class.
- On any average day about 10 students are working in the lab at any given hour.
- These students typically print up to twice during that time, and the length of these tasks ranges from 1 to 20 pages.
- The printer in the lab is older, capable of processing
10 pages per minuteof draft quality.five pages per minuteof better quality.
- The slower printing speed could make students wait too long. What page rate should be used?
building a simulation that models the laboratory.
- construct representations for students, printing tasks, and the printer (Figure 4).
- As students submit printing tasks, will add them to a waiting list, a queue of print tasks attached to the printer.
- When the printer completes a task, it will look at the queue to see if there are any remaining tasks to process.
- Of interest for us is the
average amount of time students will waitfor their papers to be printed. This is equal to theaverage amount of time a task waits in the queue.
use some probabilities. For example,
- students may print a paper from 1 to 20 pages in length.
- If each length from 1 to 20 is equally likely, the actual length for a print task can be simulated by using a random number between 1 and 20 inclusive.
- This means that there is equal chance of any length from 1 to 20 appearing.
If there are 10 students in the lab and each prints twice, then there are 20 print tasks per hour on average.
- What is the chance that at any given second, a print task is going to be created? The way to answer this is to consider the ratio of tasks to time.
- Twenty tasks per hour means that on average there will be one task every 180 seconds:
- For every second can simulate the chance that a print task occurs by generating a random number between 1 and 180 inclusive.
- If the number is 180, say a task has been created.
- Note that it is possible that many tasks could be created in a row or may wait quite a while for a task to appear. That is the nature of simulation. You want to simulate the real situation as closely as possible given that you know general parameters.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
## Create a queue of print tasks. Each task will be given a timestamp upon its arrival. The queue is empty to start.
## For each second (currentSecond):
## Does a new print task get created? If so, add it to the queue with the currentSecond as the timestamp.
## If the printer is not busy and if a task is waiting,
## Remove the next task from the print queue and assign it to the printer.
## Subtract the timestamp from the currentSecond to compute the waiting time for that task.
## Append the waiting time for that task to a list for later processing.
## Based on the number of pages in the print task, figure out how much time will be required.
## The printer now does one second of printing if necessary. It also subtracts one second from the time required for that task.
## If the task has been completed, in other words the time required has reached zero, the printer is no longer busy.
## After the simulation is complete, compute the average waiting time from the list of waiting times generated.
## create classes for the three real-world objects described above: Printer, Task, and PrintQueue.
class Printer:
def __init__(self, ppm):
self.pagerate = ppm
self.currentTask = None
self.timeRemaining = 0
def tick(self):
if self.currentTask != None:
self.timeRemaining = self.timeRemaining - 1
if self.timeRemaining <= 0:
self.currentTask = None
def busy(self):
if self.currentTask != None: return True
else: return False
def startNext(self, newtask):
self.currentTask = newtask
self.timeRemaining = newtask.getPages() * 60/self.pagerate
# the amount of time needed can be computed from the number of pages in the task.
import random
class Task:
def __init__(self,time):
self.timestamp = time
# Each task need to keep a timestamp to compute waiting time.
# This timestamp will represent the time that the task was created and placed in the printer queue.
self.pages = random.randrange(1,21)
def getStamp(self): return self.timestamp
def getPages(self): return self.pages
# The waitTime method can then be used to
# retrieve the amount of time spent in the queue before printing begins.
def waitTime(self, currenttime): return currenttime - self.timestamp
from pythonds.basic.queue Queue
import random
def newPrintTask():
num = random.randrange(1,181)
if num == 180: return True
else: return False
## newPrintTask, decides whether a new printing task has been created.
## return a random integer between 1 and 180.
## Print tasks arrive once every 180 seconds. By arbitrarily choosing 180 from the range of random integers (line 32), can simulate this random event.
## The simulation function
## set the total time and the pages per minute for the printer.
def simulation(numSeconds, pagesPerMinute):
labprinter = Printer(pagesPerMinute)
printQueue = Queue()
waitingtimes = []
for currentSecond in range(numSeconds):
if newPrintTask():
task = Task(currentSecond)
printQueue.enqueue(task)
if (not labprinter.busy()) and (not printQueue.isEmpty()):
nexttask = printQueue.dequeue()
waitingtimes.append(nexttask.waitTime(currentSecond))
labprinter.startNext(nexttask)
labprinter.tick()
averageWait=sum(waitingtimes)/len(waitingtimes)
print("Average Wait %6.2f secs %3d tasks remaining."%(averageWait,printQueue.size()))
for i in range(10):
simulation(3600,5)
Deque (Double-Ended Queues)
usually pronounced “deck” to avoid confusion with the dequeue method of the regular queue ADT, which is pronounced like the abbreviation “D.Q.”
- double-ended queue
- an ordered collection of items similar to the queue.
- It has two ends,
- a front and a rear,
- and the items remain positioned in the collection.
What makes a deque different is the unrestrictive nature of adding and removing items.
- New items can be added at either the front or the rear.
- Likewise, existing items can be removed from either end.
- provides the capabilities of stacks and queues in a single data structure.
- 可以模拟stack或者queue
it does not require the LIFO and FIFO orderings that are enforced by those data structures.
- It is up to you to make consistent use of the addition and removal operations.

Abstract Data Type
Method
- size, isEmpty : O(1)
- first, last : O(1)
- addFirst, addLast : O(1)
- removeFirst, removeLast : O(1)
Java
- The deque abstract data type is richer than both the stack and the queue ADTs.
To provide a symmetrical abstraction, the deque ADT is defined to support the following update methods:
- addFirst(e): Insert a new element e at the front of the deque.
- addLast(e): Insert a new element e at the back of the deque.
- removeFirst(): Remove and return the first element of the deque (or null if the deque is empty).
removeLast(): Remove and return the last element of the deque (or null if the deque is empty).
- first(): Returns the first element of the deque, without removing it (or null if the deque is empty).
- last(): Returns the last element of the deque, without removing it (or null if the deque is empty).
- size(): Returns the number of elements in the deque.
- isEmpty(): Returns a boolean indicating whether the deque is empty.
1
2
3
4
5
6
7
8
9
10
11
12
package queue;
public interface Deque<E> {
int size();
boolean isEmpty();
E first();
E last();
void addFirst(E e);
void addLast(E e);
E removeFirst();
E removeLast();
}
Circular Array for Deque
Doubly Linked List for Deque
- Because the deque requires insertion and removal at both ends, a doubly linked list is most appropriate for implementing all operations efficiently.
- In fact, the DoublyLinkedList class from Section 3.4.1 already implements the entire Deque interface; simply need to add the declaration “implements Deque
” to that class definition in order to use it as a deque.
1
2
3
public class Dequeue implements Deque<E> {
}
python


Deque()- creates a new deque that is empty.
- It needs no parameters and returns an empty deque.
add_front(item)- adds a new item to the front of the deque.
- It needs the item and returns nothing.
add_rear(item)- adds a new item to the rear of the deque.
- It needs the item and returns nothing.
remove_front()- removes the front item from the deque.
- It needs no parameters and returns the item.
- The deque is modified.
remove_rear()- removes the rear item from the deque.
- It needs no parameters and returns the item.
- The deque is modified.
is_empty()- tests to see whether the deque is empty.
- It needs no parameters and returns a boolean value.
size()- returns the number of items in the deque.
- It needs no parameters and returns an integer.
dequeue as a list in py (!!!!!!!!!!!!!)
1
2
3
4
5
6
7
8
class Deque:
def __init__(self): self.items = []
def is_empty(self): return not bool(self.items)
def add_front(self, item): self.items.append(item)
def add_rear(self, item): self.items.insert(0, item)
def remove_front(self): return self.items.pop()
def remove_rear(self): return self.items.pop(0)
def size(self): return len(self.items)
Palindrome-Checker 回文 对称的单词

1
2
3
4
5
6
7
8
9
10
11
12
13
14
def pal_checker(input_string):
char_deque = Deque()
for ch in input_string:
char_deque.add_rear(ch)
while char_deque.size() > 1:
first = char_deque.remove_front()
last = char_deque.remove_rear()
if first != last: return False
return True
palchecker("lsdkjfhd")
palchecker("radar")
Priority Queues
Maps, Hash Tables, and Skip Lists
Maps
- A map is an abstract data type
- designed to
efficiently store and retrieve valuesbased upon a uniquely identifying search key for each.- a map stores key-value pairs (k, v), entries
- k is the key and v is its corresponding value.
- Keys are required to be unique, so that the association of keys to values defines a mapping.
- Maps are also known as associative arrays, because the entry’s key serves somewhat like an index into the map, in that it assists the map in efficiently locating the associated entry.
- However, unlike a standard array, a key of a map need not be numeric,
- and is does not directly designate a position within the structure.
- Common applications of maps include the following:
- A university’s information system relies on some form of a student ID as a key that is mapped to that student’s associated record (such as the student’s name, address, and course grades) serving as the value.
- Thedomain-namesystem(DNS)mapsahostname,suchaswww.wiley.com, to an Internet-Protocol (IP) address, such as 208.215.179.146.
- A social media site typically relies on a (nonnumeric) username as a key that can be efficiently mapped to a particular user’s associated information.
- A company’s customer base may be stored as a map, with a customer’s account number or unique user ID as a key, and a record with the customer’s information as a value. The map would allow a service representative to quickly access a customer’s record, given the key.
- A computer graphics system may map a color name, such as ‘turquoise’, to the triple of numbers that describes the color’s RGB (red-green-blue) rep- resentation, such as (64, 224, 208).
The Map ADT
- Since a map stores a collection of objects, it should be viewed as a collection of key-value pairs.
- As an ADT, a map M supports the following methods:
- size(): Returns the number of entries in M.
- isEmpty(): Returns a boolean indicating whether M is empty.
- get(k): Returns the value v associated with key k,if such an entry exists; otherwise returns null.
- put(k, v): If M does not have an entry with key equal to k, then adds entry (k,v) to M and
returns null; else, replaces with v the existing value of the entry with key equal to k andreturns the old value. - remove(k): Removes from M the entry with key equal to k, and returns its value; if M has no such entry, then
returns null - keySet(): all the keys
- values(): all the values
- entrySet(): Returns an iterable collection containing all the key-value en- tries in M.
Java
- Map Interface
- AbstractMap Base Class
- UnSortedTableMap Class
- AbstractHashMap Class
- ChainHashMap Class
- ProbeHashMap Class
- AbstractMap Base Class
- SortedMap Interface
- AbstractSortedMap Base Class
- SortedTableMap Class
- TreeMap Class
- AbstractSortedMap Base Class
Maps in the java.util Package
A Java Interface for the Map ADT
A formal definition of a Java interface for our version of the map ADT is given in Code Fragment 10.1. It uses the generics framework (Section 2.5.2), with K designating the key type and V designating the value type.
1
2
3
4
5
6
7
8
9
10
public interface Map<K,V> {
int size();
boolean isEmpty();
V get(K key);
V put(K key, V value);
V remove(K key);
Iterable<K> keySet();
Iterable<V> values();
Iterable<Entry<K,V>> entrySet();
}
AbstractMap Abstract/Base Class
AbstractMap base class
- provides functionality that is shared by all of our map implementations.
- the base class provides the following support:
- An implementation of the isEmpty method, based upon the presumed imple- mentation of the size method.
- A nested MapEntry class that implements the public Entry interface, while providing a composite for storing key-value entries in a map data structure.
- Concrete implementations of the keySet and values methods, based upon an adaption to the entrySet method. In this way, concrete map classes need only implement the entrySet method to provide all three forms of iteration.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
package map;
import pq.*;
public abstract class AbstractMap implements Map<K,V>{
// /---------------- nested MapEntry class ----------------
protected static class MapEntry<K,V> implements Entry<K,V> {
private K k;
private V v;
public MapEntry(K key, V value){
k=key;
v=value;
}
// public methods of the Entry interface
public getKey() {return k;}
public getValue() {return v;}
// utilities not exposed as part of the Entry interface
protected void setKey(K key) {k=key;}
protected V setValue(V value) {
V old = v;
v = value;
return old;
}
}
public boolean isEmpty() {return size()==0;}
// // Support for public keySet method...
private class KeyIterator implements Iterator<K> {
private Iterator<Entry<K,V>> entries = entrySet().iterator(); // reuse entrySet
public boolean hasNext(){return entries.hasNext();}
public K next(){return entries.next().getKey();} // return key
public void remove(){throw new UnsupportedOperationException();}
}
private class KeyIterable implements Iterable<K> {
public Iterator<K> iterator() { return new KeyIterator(); }
}
public Iterable<K> keySet( ) { return new KeyIterable( ); }
// Support for public values method...
private class ValueIterator implements Iterator<V> {
private Iterator<Entry<K,V>> entries = entrySet().iterator(); // reuse entrySet
public boolean hasNext(){return entries.hasNext();}
public V next(){return entries.next().getKey();} // return key
public void remove(){throw new UnsupportedOperationException();}
}
private class ValueIterable implements Iterable<V> {
public Iterator<K> iterator() { return new ValueIterator(); }
}
public Iterable<V> values( ) { return new ValueIterable( ); }
}
- demonstrate the use of the AbstractMap class with a very simple concrete implementation of the map ADT that relies on storing key-value pairs in arbitrary order within a Java ArrayList.
UnsortedTableMap Class
Each of the fundamental methods
get(k), put(k, v), and remove(k)requires an initial scan of the array todetermine whether an entry with key equal to k exists. For this reason, provide a nonpublic utility, findIndex(key), that returns the index at which such an entry is found, or −1 if no such entry is found.remove an entry from the array list. Although could use the remove method of the ArrayList class, that would result in an unnecessary loop to shift all subsequent entries to the left. Because the map is unordered, prefer to fill the vacated cell of the array by relocating the last entry to that location. Such an update step runs in constant time.- the UnsortedTableMap class on the whole is not very efficient. On a map with n entries, each of the fundamental methods takes
O(n)time in the worst case because of the need to scan through the entire list when searching for an existing entry. - Fortunately, as discuss in the next section, there is a much faster strategy for implementing the map ADT.
Hashing
- Hashing is used to map data of an arbitrary size to data of a fixed size.
- The values returned by a hash function are called
hash values, hash codes, or simply hashes. - If two keys map to the same value, a
collisionoccurs
Hash Map
- a hash map is a structure that can
map keys to values. - A hash map uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
Collision Resolution
- Separate Chaining:
- each bucket is independent, and contains a list of entries for each index.
- The time for hash map operations is the time to find the bucket (constant time), plus the time to iterate through the list
- Open Addressing:
- when a new entry is inserted, the buckets are examined, starting with the hashed-to-slot and proceeding in some sequence, until an unoccupied slot is found.
- The name open addressing refers to the fact that the location of an item is not always determined by its hash value

Nonlinear data structures
Graph
- A Graph is an ordered pair of
G = (V, E)- comprising a set
V of vertices or nodestogether with aset E of edges or arcs, - which are 2-element subsets of V
- (i.e. an edge is associated with two vertices, and that association takes the form of the unordered pair comprising those two vertices)
- comprising a set
Undirected Graph:- a graph in which the 邻接关系 adjacency relation is symmetric.
- So if there exists an
edge from node u to node v (u -> v), - then it is also the case that there exists an
edge from node v to node u (v -> u)
Directed Graph:- a graph in which the 邻接关系 adjacency relation is not symmetric.
- So if there exists an edge from node u to node v (u -> v),
- this does not imply that there exists an edge from node v to node u (v -> u)

。
Comments powered by Disqus.