Virtualization - Container
Virtualization - Container
basic

Traditional
- deploy an application on its own physical computer.
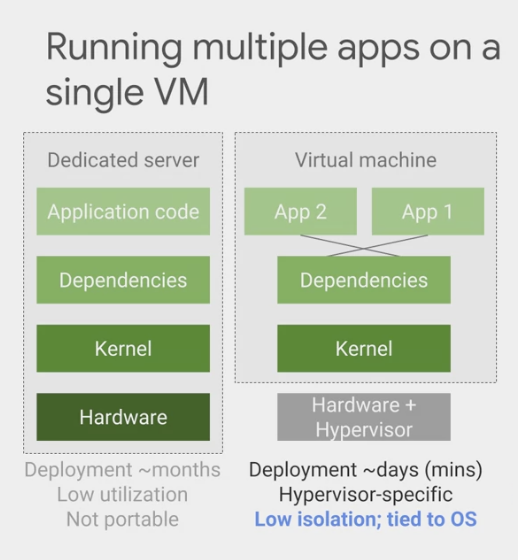
Virtualization
- takes less time to deploy new solutions
- waste less of the resources on those physical computers
- get some improved portability because virtual machines can be imaged and then moved around.


Containers
- more efficient way to resolve the dependency problem
- Implement abstraction at the level of the application and its dependencies.
- not virtualize the entire machine /OS,
- but just the user space.
- the user space is all the code that resides above the kernel, and includes the applications and their dependencies.
- An application and its dependencies are called an image.
- A container is simply a running instance of an image.
- building software into Container images
- and easily package and ship an application without worrying about the system it will be running on
VM-based vs container-based deployment


Container


- a method of operating system virtualization
- give the environment independent scalability of workloads like PaaS
- and an abstraction layer of the operating system and hardware, like IaaS
- fast, portable, and infrastructure-agnostic execution environment.
- next step in the evolution of managing code
- containers as delivery vehicles for application code,
- lightweight, stand-alone, resource efficient, portable execution packages.
- an application-centric way to deliver high performance and scalable applications
- containers share a virtualized operating system
- run as resource-isolated processes
- smaller than virtual machines,
- do not contain an entire operating system.
- starts as quickly as a new process.
- it visualize the os rather than the hardware.
- run as resource-isolated processes
isolated user spaces per running application code.
ensure quick, reliable, and consistent deployments of applications
- quick
- lightweight because they don’t carry a full operating system,
- can be scheduled or packed tightly onto the underlying system, which is very efficient.
- can be created and shut down very quickly
- because just start/stop the processes that make up the application
- not booting up an entire VM or initializing an OS for each application.
- container images are usually an order of magnitude smaller than virtual machines.
- Spinning up a container happens in hundreds of milliseconds.
- lightweight because they don’t carry a full operating system,
- deliver environmental consistency
- regardless of deployment environment.
- makes the code very portable.
- treat the os and hardware as a black box.
- can move the code from development, to staging, to production, or from the laptop to the Cloud without changing or rebuilding anything.
- all application's code, configurations, and dependencies are packaged into a single object.
- a easy-to-use building blocks
- Containers hold everything that the software needs to run,
- such as libraries, system tools, code, and the runtime
- the container’s the same and runs the same anywhere.
- quick
- operational efficiency,
- give more granular control over resources, which gives your infrastructure improved efficiency.
- developer productivity, and version control.
- You make incremental changes to a container based on a production image, you can deploy it very quickly with a single file copy, this speeds up your development process.
- execute your code on VMs without worrying about software dependencies
- like application run times, system tools, system libraries, and other settings.
- package your code with all the dependencies it needs, and the engine that executes your container, is responsible for making them available at runtime.
- Microservices
- application are created using independent stateless components or microservices runningn in containers
- loosely coupled, fine-grained components.
- allows the operating system to scale and also upgrade components of an application without affecting the application as a whole.
use case:
- to scale a web server
- can do so in seconds
- and deploy dozens or hundreds of them depending on the size of the workload on a single host.
- to build the applications using lots of Containers,
- each performing their own function, using the micro-services pattern.
- The units of code running in these Containers can communicate with each other over a network fabric.
build and run containers
Google Cloud offers Cloud Build a managed service for building Containers.
Docker
- to bundle an application and its dependencies into a Container.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# a Python web application
# uses the very popular Flask framework.
app.py
from flask import Flask
app = Flask(__name__)
# - Whenever a web browser go to its top-most document, it replies "hello world".
@app.route("/")
def hello():
return "Hello World!\n"
# - Or if the browser instead appends/version to the request, the application replies with its version.
@app.route("/version")
def hello():
return "Hello World!\n"
if __name__ == "__main__":
app.run(host='0.0.0.0')
- deploy this application
1
2
3
4
requirements.txt
# It needs a specific version of Python and a specific version of Flask, which we control using Python's requirements.txt file, together with its other dependencies too.
Flask==0.12
uwsgi==2.0.15
- use a Docker file to specify how the code gets packaged into a Container.
From ubuntu:18.10
RUN apt-get update -y
COPY requirement.txt /app/requirement.txt
WORKDIR /app
RUN pip3 install - r requirement.txt
COPY . /app
ENTRYPOINT ["python3", "app.py"]
- use the Docker build command to build the Container.
1
2
3
4
5
# - builds the Container and stores it on the local system as a runnable image.
docker build -t py-server .
# - to run the image.
docker run -d py-server
containers component
Containers power to isolate workloads is derived from the composition of several technologies.
- Linux process.
- One foundation is the Linux process.
- Each Linux process has its own virtual memory address phase, separate from all others.
- Linux processes are rapidly created and destroyed.
- Linux namespaces
- Containers use Linux namespaces to control what an application can see,
- process ID numbers, directory trees, IP addresses, and more.
- not the same thing as Kubernetes Namespaces
- Containers use Linux namespaces to control what an application can see,
- Linux cgroups
- Containers use Linux cgroups to control what an application can use,
- its maximum consumption of CPU time, memory, IO bandwidth, other resources.
- Containers use Linux cgroups to control what an application can use,
- Union File Systems
- Containers use Union File Systems to efficiently encapsulate applications and their dependencies into a set of clean minimal layers.
container image
- An application and its dependencies are called an image.
A container is simply a running instance of an image.
By building software into container images,
easily package and ship an applicationwithout worrying about the system it will be running on.Containers are not an intrinsic, primitive feature of Linux. Instead, their power to isolate workloads is derived from the composition of several technologies.
- One foundation is the Linux
process.- Each Linux process has its own virtual memory address space , separate from all others, and Linux processes are rapidly created and destroyed.
- Containers use Linux
namespaces:- use Linux
namespacesto control what an application can see: process ID numbers, directory trees, IP addresses, and more. - Linux namespaces are not the same thing as Kubernetes namespaces
- use Linux
Containers use
cgroupsto control what an application can use: its maximum consumption of CPU time, memory, I/O bandwidth, and other resources.- containers use
union file systemsto efficiently encapsulate applications and their dependencies into a set of clean, minimal layers.
- One foundation is the Linux

- A container image is structured in layers.
- The tool you use to build the image reads instructions from a file called the “container manifest”
- The Container manifest:
- The file, tool to build the image reads instructions
- Dockerfile
- Docker formatted Container Image
- Each instruction in the Dockerfile specifies a layer inside the container image.
- Each layer is,
Read onlyWhen a Container runs from this image - have a writable ephemeral top-most layer.
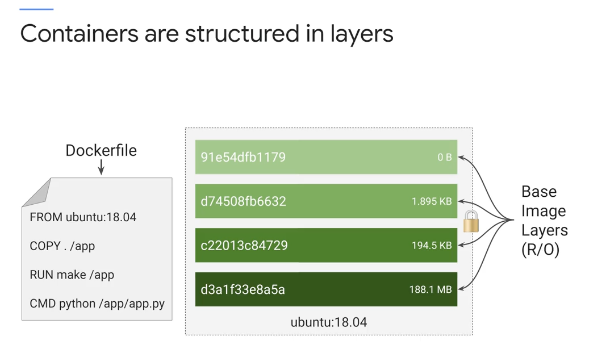
- This Dockerfile will contain four commands, each of which creates a layer.
- The
FROMstatement starts out by creating a base layer, pulled from a public repository. This one happens to be the Ubuntu Linux runtime environment of a specific version. - The
COPYcommand adds a new layer, containing some files copied in from your build tool’s current directory. - The
RUNcommand builds your application using the “make” command and puts the results of the build into a third layer. - The last layer specifies what command to run within the container when it is launched.
- The
- Each layer is only a set of differences from the layer before it. When you write a Dockerfile
- organize from the layers likely to change, through to the layers most likely to change.
oversimplified
- These days, the best practice is not to build your application in the very same container that you ship and run.
- your build tools are at best just clutter in a deployed container, and at worst they are an additional attack surface.
Today, application packaging relies on a multi-stage build process, in which one container builds the final executable image, and a separate container receives only what is needed to run the application.
- Fortunately for us, the tools we use support this practice. When you launch a new container from an image, the container runtime adds a new writable layer on top of the underlying layers. This layer is often called the
container layer.- All changes made to the running container, such as writing new files, modifying existing files, and deleting files, are written to this thin writable container layer.
- And they’re ephemeral: When the container is deleted, the contents of this writable layer are lost forever. The underlying container image remains unchanged.
- This fact about containers has an implication for your application design: whenever you want to store data permanently, you must do so somewhere other than a running container image.

- Because each container has its own writable container layer, and all changes are stored in this layer, multiple containers can share access to the same underlying image and yet have their own data state.
- The diagram shows multiple containers sharing the same Ubuntu image. Because each layer is only a set of differences from the layer before it, you get smaller images.
- For example, your base application image may be 200 MB, but the difference to the next point release might only be 200 KB. When you build a container, instead of copying the whole image, it creates a layer with just the difference. When you run a container, the container runtime pulls down the layers it needs. When you update, you only need to copy the difference. This is much faster than running a new virtual machine.
It’s very common to use publicly available open-source container images as the base for your own images, or for unmodified use.
- “ubuntu” container image, which provides a Ubuntu Linux environment inside a container.
- “Alpine” is a popular Linux environment in a container, noted for being very small.
- The nginx web server is frequently used in its container packaging.
- Artifact Registry is the single place to store container images as well as language and OS packages. You can use Artifact Registry with other Google Cloud services namely IAM for access control, KMS for customer managed encryption keys, Cloud Build for CI/CD and scan for container vulnerabilities with Container Analysis.
- You can also find container images in other public repositories: Docker Hub Registry, GitLab, and others.
- Cloud Build can retrieve the source code for your builds from many code repositories, including Cloud Source Repositories, or git-compatible repositories like GitHub and Bitbucket. To generate a build with Cloud Build, you define a series of steps. For example, you can configure build steps to fetch dependencies, compile source code, run integration tests, or use tools such as Docker, Gradle, and Maven. Each build step in Cloud Build runs in a Docker container. Then Cloud Build can deliver your newly built images to various execution environments: not only GKE, but also App Engine and Cloud Functions.
Docker file

- The From statement
- create a base layer pulled from a public repository.
- The Copy command
- adds a new layer
- containing some files copied in from your build tools current directory.
- The Run command
- builds your application using the make command
- and puts the result of the build into a third layer.
- CMD
- specifies what command to run within the container when it’s launched.
the best practice is not to build your application in the very same container that you ship and run.
- After all, your build tools are at best just cluttered and deployed Container and at worst, are an additional attack service.
- Today, Application Packaging relies on a multi-stage build process and one Container builds the final executable image.
- A separate container receives only what’s needed to actually run the application.
Container layer
- When you launch a new container from an image, the Container Runtime adds a new writable layer on the top of the underlying layers.
- All changes made to the running container,
- such as writing new files, modifying existing files, and deleting files are written to this thin writable Container layer in their ephemeral
- All changes made to the running container,
- when the Containers deleted the contents of this writeable layer are lost forever.
- The underlying Container Image itself remains unchanged.
- to store data permanently
- do so somewhere other than a running container image.
- Because each Container has its own writable Container layer and all changes are stored in this layer.
- Multiple Containers can share access to the same underlying image and yet have their own data state.
- Because each layer is only a set of differences from the layer before it, you get smaller images.
- When you build a container
- instead of copying the whole image, it creates a layer with just the differences.
- When you run a container
- that Container Runtime pulls down the layers it needs.
- When you update
- only need to copy the difference
- much faster than running a new virtual machine.
- When you build a container
Container Registry
- download containerized software from a container registry
- use publicly available open source Container images as a base for images or for unmodified use.
- Google maintains a Container Registry,
gcr.Io.- contains many public, open source images
- find Container images and other public repositories, Docker Hub Registry, GitLab and others.
- Google Container Registry is integrated with Cloud IAM.
- can use it to store your images that aren’t public.
- Instead, they’re private to your project.
- contains many public, open source images
- build your own container using docker
- downside
- whoever building Containers with a Docker is that you must trust the computer that you do your builds on.
- it doesn’t offer a way to orchestrate those applications at scale like Kubernetes does.
- downside
- build your own container using Cloud Build
- a managed service
- for building Containers that’s also integrated with Cloud IAM.
- Cloud build can retrieve the source code for your builds from a variety of different storage locations.
- Cloud Source Repositories, Cloud Storage, which is GCP is Object Storage service or git compatible repositories like GitHub and Bitbucket to generate a buildup Cloud Build, you define as series of steps.
- example
- configure build steps to fetch dependencies, compile source code, run integration tests, or use tools such as Docker, Gradle, and Maven.
- Each build step and Cloud build runs in a Docker container.
- Then Cloud build can deliver your newly built images to various execution environments, not only GKE, but also App Engine and Cloud Functions.

software for container
software to build Container images and to run them.
- Docker for linux.
- open source technology
- create and run applications in containers
Windows Containers for win workloads.
- Kubernetes
- make applications modular.
- They deploy it easily and scale independently across a group of hosts.
The host can scale up and down, and start and stop Containers as demand for the application changes, or even as hosts fail and are replaced.
- A tool that helps you do this well is Kubernetes.
- Kubernetes makes it easy to orchestrate many Containers on many hosts.
- Scale them,
- roll out new versions of them, and even roll back to the old version if things go wrong.
- make applications modular.
Best Practices for Securing AWS ECS
- Understand the AWS Shared Responsibility Model
- Enforce a Zero-Trust Identity and Access Management (IAM) Policy
- Ensure End-to-End Encryption for Secure Network Channels
- Inject Secrets into Containers in Runtime
- Follow a zero-trust security policy in managing the Secrets definition parameters for AWS containers.
- Secrets include login credentials, certificates and API keys used by applications and services to access other system components.
- For example, use AWS Secrets manager for secure storage of Secrets credentials instead of baking them into the container.
- Regulatory Compliance as the Bare Minimum not target Security
- Follow the guidelines of the applicable security regulations in your country and industry, but treat them as a bare minimum and not an end-goal of your ECS security plan.
- AWS helps deploy compliance-focused baseline environments especially focused on the following guidelines across most of the popular regulations such as HIPAA, PCI-DSS and GDPR, among others (some already mentioned) including understanding the shared responsibility model, enforcing strong IAM policy controls, leveraging the built-in tools / visibility provided by the cloud service provider and having the processes and technology in place to investigate and respond to incidents that may impact your ECS workloads.
- Gather the Right Data
- Configure your container environments to communicate relevant security data and log data to the built-in AWS monitoring tools such as CloudWatch and CloudTrail.
- These tools can be used to collect data insights at the hardware, service, and cluster level.
- Best Practices for AWS Fargate:
- a serverless service that provides the option of fully managed and abstracted infrastructure for containerized applications managed using AWS ECS. The AWS Fargate service performs tasks such as provisioning, management, and security of the underlying container infrastructure while users simply specify the resource requirements for their containers.
- The fully managed nature of Fargate is fantastic to reduce time and money spent worrying about failing drives or configuring operating systems, but this lack of infrastructure management comes with an equal lack of access. And this lack of access can add frustrations when it comes to security. Since AWS Fargate is a managed service, it offers no visibility and control into the underlying infrastructure. Due to this, it’s important that you leverage a third-party solution to allow for data collection from running containers should you need to investigate one.
- Construct Secure Container Images
- Container images consist of multiple layers, each defining the configurations, dependencies and libraries required to run a containerized application.
- Security of container images should be seen as your first line of defense against cyberattacks or infringements facing your containerized applications. Constructing secure container images is critical to enforce container bounds and prevent adversaries from accessing the Host OS and Kernel.
- A few ECS container image security best practices that should be considered include
- using minimal or distroless images,
- image scanning for vulnerabilities,
- and avoiding running containers as privileged.
Incident Readiness for Containers
- When investigating an environment which utilizes containers, data collection needs to happen quickly before automatic cluster scaling destroys valuable evidence.
- Additionally, you may have thousands of containers so the collection, processing, and enrichment of container data needs to be automated. Some of the key things to consider are:
- Automated Data Collection
- Cloud scaling allows you to scale your investigation resources too, not just your applications. Collect and process container data in parallel triggered by an analyst or other detection or orchestration tool (e.g., SOAR) to get valuable information to analysts more quickly and reduce your time to incident containment and resolution.
- Level of Visibility
- While the visibility provided by built-in CSP tools (e.g. AWS CloudWatch and CloudTrail) is important, these data sources alone are not sufficient to perform an in-depth investigation.
- Leveraging third-party incident and threat intelligence capabilities prove vital to gain a deeper level of visibility across container assets.
- In this context, the useful data to include as part of your investigation are
- the system logs and files from within the container,
- the containers running processes and active network connections,
- the container host system and container runtime logs (if accessible),
- the container host memory (if accessible) and the AWS VPC flow logs for the VPC the container is attached to.
- If data collection wasn’t baked into the container declaration before the need to investigate arose, you need to rely on data you can actively interrogate out of the container. Or if you’re using ECS on Fargate, taking an image of the running container or the container host isn’t an option as the underlying AWS infrastructure is shared with no access to the end customers.
- In this case, the /proc directory gives us a snapshot of the volatile state of the container, much like a memory dump. Using this ‘snapshot’ we can build a basic picture of what is going on in the container at that time, such as running processes, active network connections, open files etc. This data provides a foundation of what you need to correlate with other data sources such as firewall logs, network subnet flows etc during an investigation to understand the actions carried out by an attacker.
- Container Asset Discovery
- Since containers operate as virtualized environments within a shared host kernel OS, it’s often challenging to keep track of
asset workloadsrunning across all containerized machines in a scaled environment. - An agentless discovery process that can efficiently discover and track container assets can be used to enforce appropriate security protocols across all container apps.
- Since containers operate as virtualized environments within a shared host kernel OS, it’s often challenging to keep track of
- Dedicated Investigation Tools and Environment
- Have a dedicated toolset or environment which automates as much of the investigative process as possible in place ahead of time so that you are ready to respond at a moment’s notice.
- Ability to Quickly Isolate
- In the event a container is compromised, it’s critical that you have the ability to quickly isolate it in order to stop the active attack and prevent further spread and damage. In some cases, isolation can be a good first step to take following initial detection. This will allow you to perform a more thorough investigation in the background and ensure proper remediation and containment steps are taken after you have a better understanding of the true scope and impact of the incident.
.
Comments powered by Disqus.