AWS
Amazon Web Services
- Amazon Web Services
By feature

Reservations
- services can reserve include: EC2, ElastiCache, DynamoDB, RDS, and RedShift.
Backup
- Amazon RDS
- Default automated backups, point in time recovery to any point within the retention period down to a second.
- full daily snapshot of data (during preferred backup window) and captures transaction logs (updates to DB Instance are made).
- data is stored on S3 and is equal to the size of the DB
- Amazon LightSail Databases
- automatically backs up the database and allows point in time restore from the past 7 days using the database restore tool
- EBS:
- Each EBS volume is automatically replicated within its Availability Zone
- back up data on EBS volumes to S3 by taking point-in-time snapshots. incremental backups
- EC2:
- EC2 instances using EBS volumes can be backed up by creating a snapshot of the EBS volume.
Scaling
- RDS
- can only scale up (compute and storage),
no decrease, scale vertically, have downtime. - push of a button.
- Automatic failover for Multi-AZ option: creates a replica in another AZ and synchronously replicates to it (DR only). IOPS storage
- enable Auto Scaling in AWS Management Console
- can only scale up (compute and storage),
- DynamoDB
- default
automatic scaling - Application auto scaling, replicated across 3 AZs in a region.
- Push button scaling: can scale the DB at any time without downtime.
- Cross-region replication allows you to replicate across regions
- default
- Lambda:
- scales automatically.
- Continuous scaling.
- S3:
- automatically scales to high request rates.
- enables automatic, asynchronous copying of objects across Amazon S3 buckets
- can copy objects between different AWS Regions or in same Region.
- Cross-Region replication (CRR): different AWS Regions.
Charge
- free to use
- Identity and Access Management (IAM)
- Virtual Private Cloud (VPC)
- Auto-Scaling
- Elastic Beanstalk
- CloudFormation
- Not free
- EC2, RDS, EBS, Route53, S3
- RDS:
- Charge for:
- the type and size of database, the uptime, DB instance hours, Storage GB/month., I/O requests/month – for magnetic storage
- Provisioned IOPS/month – for RDS provisioned IOPS SSD
- Backup storage (DB backups and manual snapshots), any additional storage of backup (above the DB size)
- requests
- deployment type (e.g. you pay for multi AZ)
- data transfer outbound. Egress data transfer
- Price model
- On-Demand or Reserved instance pricing
- Charge for:
- EC2:
- charged for
- uptime of the instance based on the family and type.
- EC2 instance on Linux 2 AMI is billed per second
- the amount of data provisioned
- pay for Amazon EBS on a per GB of provisioned storage basis.
- uptime of the instance based on the family and type.
- charged for
- Lambda:
- the compute time that use.
- Execution requests
- execution duration (when code is running).
- Amazon LightSail Databases
- affordable. billed on an on-demand hourly rate
- pay only for what use.
- fixed hourly price, up to the maximum monthly plan cost.
- affordable. billed on an on-demand hourly rate
- EBS:
- charged
- the amount of data provisioned (not consumed) per month.
- can have empty within a volume and still pay for it.
- With provisioned IOPS volumes, also charged for the amount provision in IOPS
- S3:
- Charges:
- Storage.
- Requests.
- Storage management pricing.
- Data transfer pricing. Data egress
- Transfer acceleration.
- the standard storage class: per GB/month storage fee, and data transfer out of S3.
Standard-IA and One Zone-IA: minimum capacity charge per object.Standard-IA, One Zone-IA, and Glacier: also have a retrieval fee.- No fee for data into S3 under any storage class.
- Charges:
AWS serviceless


AWS solutions
AWS solutions typically fall into one of two categories: unmanaged or managed.

Unmanaged services
- provisioned in discrete portions as specified by the user.
require the user to managehow the service responds to changes in load, errors, and situations where resources become unavailable.- When you run the own relational database, you are responsible for
- several administrative tasks (server maintenance and energy footprint, software, installation and patching, and database backups),
- ensuring high availability,
- planning for scalability,
- data security,
- and OS nstallation and patching.
Managed services
- require the user to configure them.
- Managed services still require the user to configure them (for example, creating an Amazon S3 bucket and setting permissions for it);
- however, managed services typically require far less configuration.
- The benefit to using an unmanaged service is that to have more fine tuned control over how the solution handles changes in load, errors, and situations where resources become unavailable
For instance
- launch a web server on an Amazon EC2 instance
- that web server will not scale to handle increased traffic load or replace unhealthy instances with healthy ones unless you specify it to use a scaling solution such as Auto Scaling, because Amazon EC2 is an “unmanaged” solution.
- have a static website hosting in a cloud based storage solution like Amazon S3 without a web server
- those features (scaling, fault tolerance, and availability) would be automatically handled internally by Amazon S3, because it is a managed solution.
Cloud deployment models
3 main cloud deployment models
- represent the cloud environments that the applications can be deployed in
All in Cloud
- A cloud-based application is fully deployed in the cloud, and all parts of the application run in the cloud.
- Applications can either been created in the cloud or migrated from an existing infrastructure.
- Cloud-based applications can be built on low-level infrastructure pieces or they can use higher-level services that provide abstraction from the management, architecting, and scaling requirements of core infrastructure.
Hybrid
- A hybrid deployment is a way to connect infrastructure/applications between
cloud-based resources and existing resources not in cloud. - The most common method of hybrid deployment is between the cloud and existing on-premises infrastructure.
- This model enables an organization to
extend and grow the infrastructure into the cloud while connecting cloud resources to internal systems.
Private / on-premises
- Deploying resources on-premises,
- using virtualization and resource management tools
- does not provide many of the benefits of cloud computing, it is sometimes sought for its ability to provide dedicated resources.
- In most cases, this deployment model is the same as legacy IT infrastructure, but it might also use application management and virtualization technologies to increase resource utilization.
Advantages of cloud computing
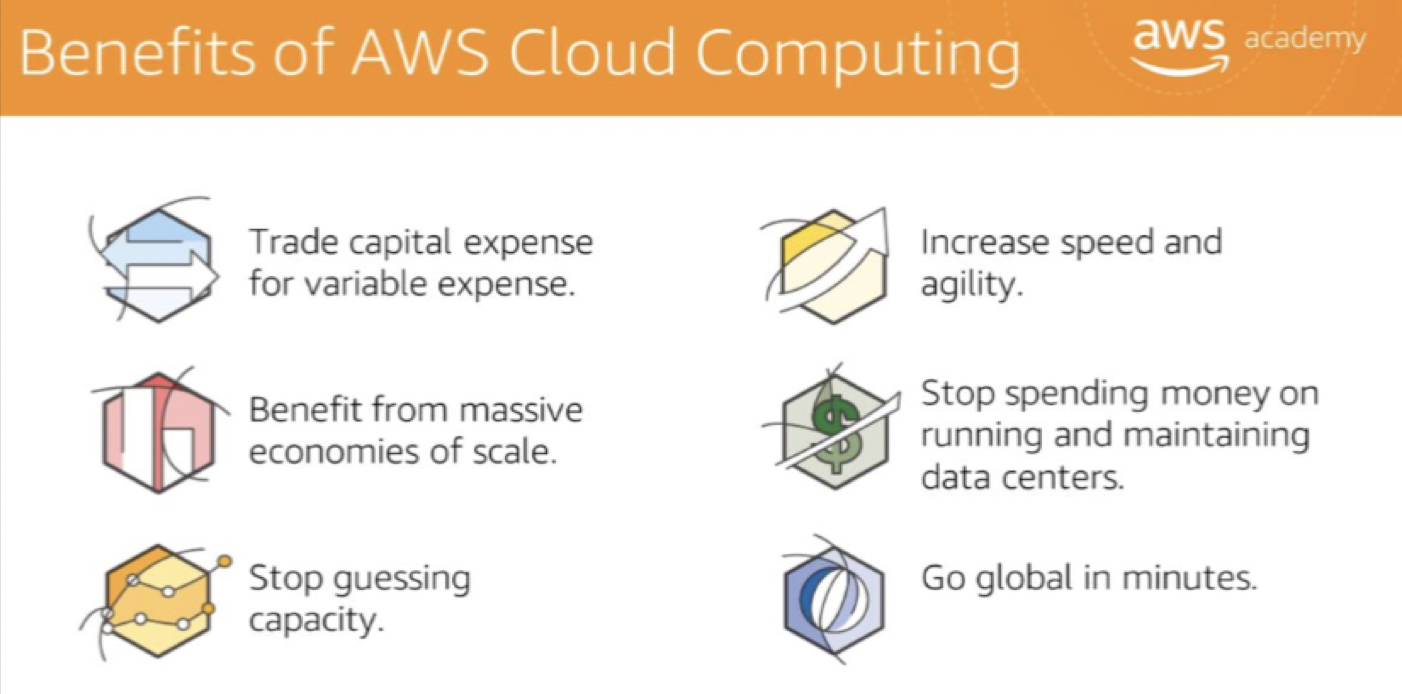
- Trade
capital expenseforvariable expense:- Capital expenses (capex): funds that a company uses to acquire, upgrade, and maintain physical assets such as property, industrial buildings, or equipment.
- variable expense (oppex): expense that the person who bears the cost can easily alter or avoid.
- Maintenance is reduced
- Cost savings
Benefit from massive economies of scale:- a lower variable cost than you can get on the own.
- as AWS can achieve higher economies of scale, lower pay-as-you-go prices.
Stop guessing capacity:- Eliminate guessing infrastructure capacity needs. When you make a capacity decision before you deploy an application, expensive idle resources / limited capacity. With cloud computing, these problems go away. You can access as much or as little as you need, and scale up and down as required with only a few minutes’ notice.
Elasticity弹力- avoid over-provision resources up front to handle peak levels of activity
- scale resources up or down to instantly to grow and shrink capacity as the business needs change.
Increase speed and agility 敏捷:- new IT resources with a click, reduce the time to make those resources available.
- dramatic increase agility for the organization because the cost and time that it takes to experiment and develop are significantly lower.
- easy access to a broad range of technologies to innovate faster and build nearly anything.
- quickly spin up resources as needed from infrastructure services, such as compute, storage, and databases, to IoT, machine learning, data lakes and analytics…
- deploy technology services in minutes, and get from idea to implementation several orders of magnitude faster than before.
- the freedom to experiment, test new ideas to differentiate customer experiences, and transform the business.
- new IT resources with a click, reduce the time to make those resources available.
- Stop spending money in
data centers:- Stop spending money on running and maintaining
- Focus on projects that differentiate the business instead of focusing on the infrastructure.
- Go
global in minutes:- deploy the application in multiple AWS Regions around the world with just a few clicks.
- provide a lower latency and better experience for the customers simply and at minimal cost.
- For example,
- AWS has infrastructure all over the world, so you can deploy the application in multiple physical locations with just a few clicks.
- Put applications closer to end users reduces latency and improves their experience.
other:
Test systems at production scale.non-cloud environment, it is usually cost-prohibitive to create a duplicate environment solely for testing. Consequently, most test environments are not tested at live levels of production demand.
create a duplicate environment on demand, complete the testing, and then decommission the resources
only pay for the test environment when it is running
Automateto make architectural experimentation easier.create and replicate systems at low cost or with no manual effort.
track changes to automation, audit the impact, and revert to previous parameters when necessary.
Allow for evolutionary architectures.the ability to automate and test on demand lowers the risk of impact from design changes
allows systems to evolve over time so that businesses can take advantage of new innovations as a standard practice
Drive architectures using data.collect data on how architectural choices affect the behavior of workload,
make fact-based decisions on how to improve workload.
use that data to inform the architectural choices and improvements over time
improve through game days
test how well architecture and processes perform by regularly scheduling game days to simulate events in production.
understand where to make improvements, and help organization develop experience in dealing with events.
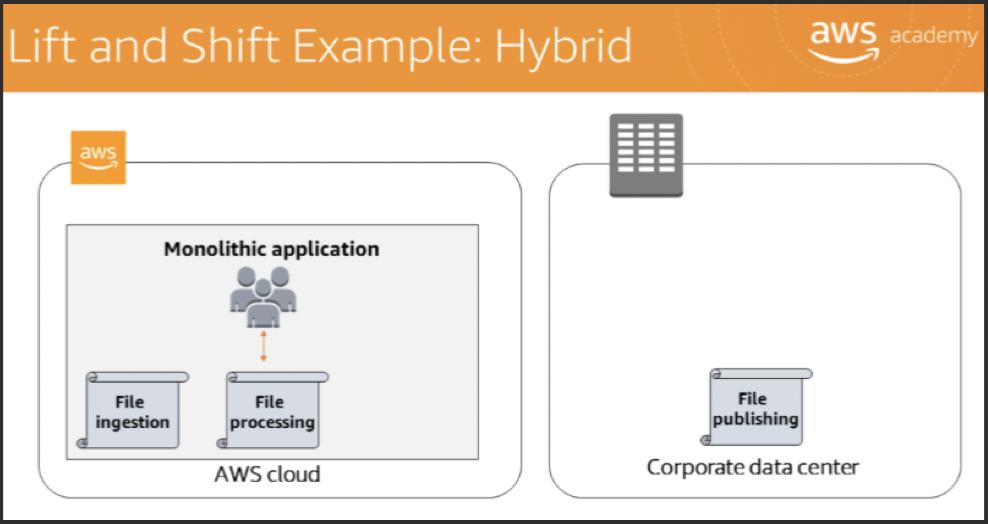
lift and shift example
rarely do the same parties easily agree on a common approach to the hundreds or thousands of existing applications that still reside in company data centers.
Teams responsible for effecting an enterprise’s transition to the cloud might initially find it easier to apply a one-size-fits-all approach and cut through devolving debates about risks and dependencies, but that approach could also jeopardize the trust and cooperation of the application owners they are asking to migrate.
Yet many enterprise cloud teams have been successful earning this trust and cooperation while also
delivering on aggressive timelines in so-called “lift-and-shift” cloud migrations
- move a specific set of applications to the cloud as fast as possible without changing their core architecture, functionality, or performance characteristics.
- This is no small challenge since some application development teams will have the opinion that their software will require substantial refactoring to run in the cloud, while others don’t want to bring their technical debt to a pristine new cloud environment.
- The fundamental notion of software refactoring is to change application code for the better.
All in Cloud
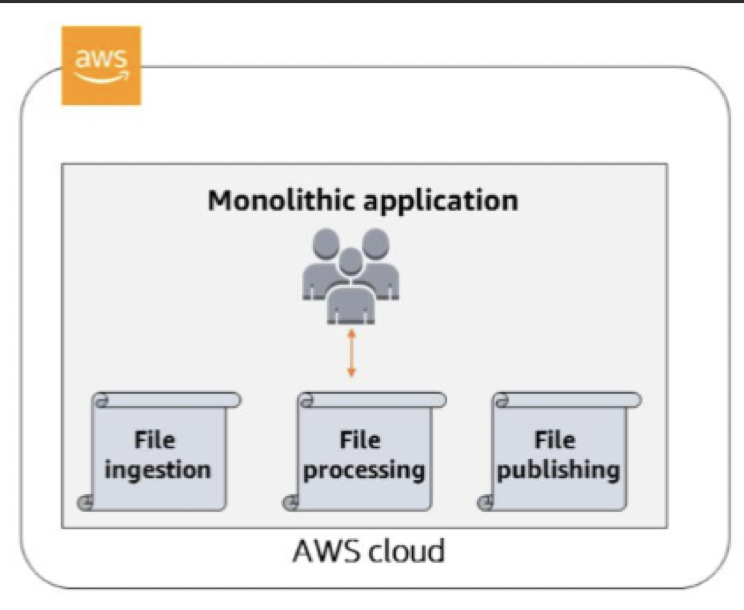
Hybrid
havincg data resides both on-premises and in the cloudThis is often done to economically store large data sets, utilize new cloud-native databases, move data closer to customers, or to create a backup and archive solution with cost-effective high availability.
In all cases, AWS offers a range of storage and database services that can work together with the on-premises applications to store data reliably and securely.
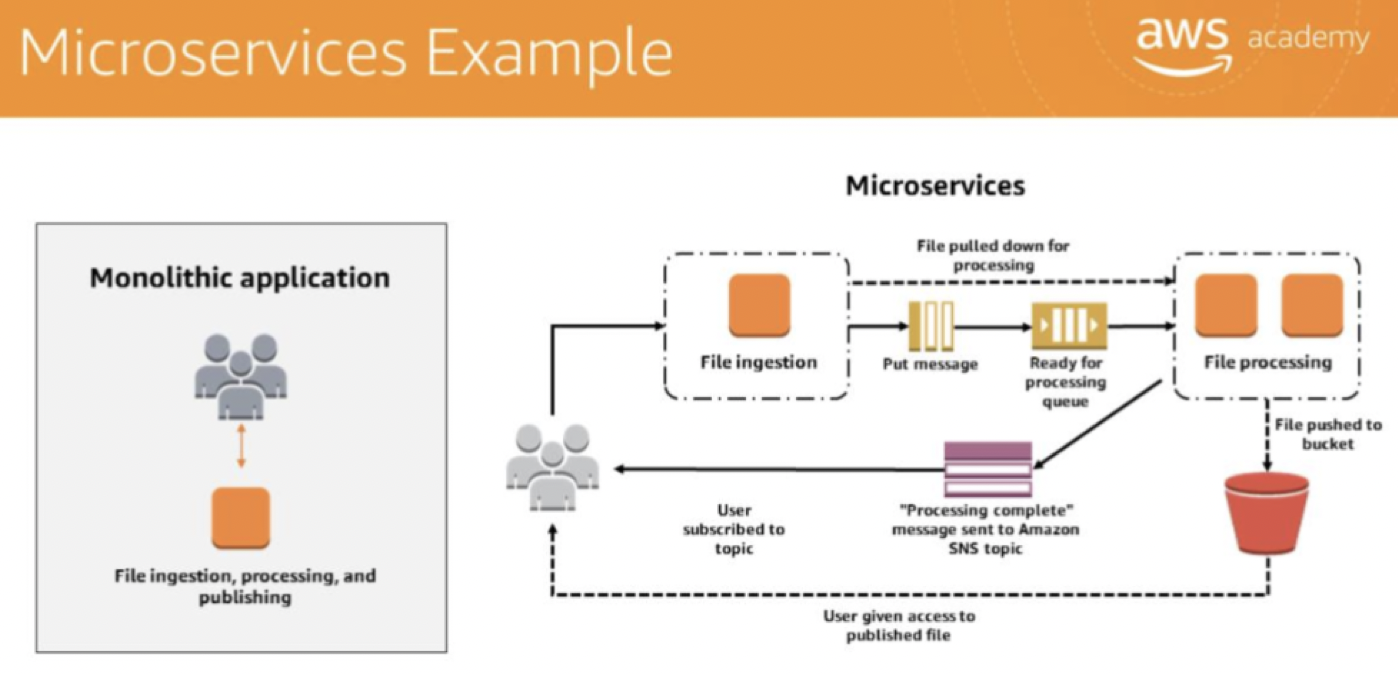
Traditional monolithic architectures
hard to scale.
As an application’s code base grows, it becomes complex to update and maintain. Introducing new features, languages, frameworks, and technologies becomes very hard, limiting innovation and new ideas.
microservices architecture
a design approach to build a single application as a set of small services.
Each application component / service runs in its own processandcommunicates with other services through a well-defined API interface(using a lightweight mechanism, typically an HTTP-based application programming interface (API). )- Microservices are built around business capabilities
- each service performs a single function.
- use different frameworks / programming languages to write microservices and deploy them independently, as a single service, or as a group of services.
Microservices can be written using different frameworks and programming languages, and you can deploy them independently, as a single service, or as a group of services.
Microservices allow you to choose the best technology for the workload.
- For example you might use in-memory cache such as Memcached or Redis for fast access to the data, but in another service you might be better served with a traditional relational database. Same goes for the chosen programming language and other technology choices: remaining flexible about them is both a benefit and a mandate.
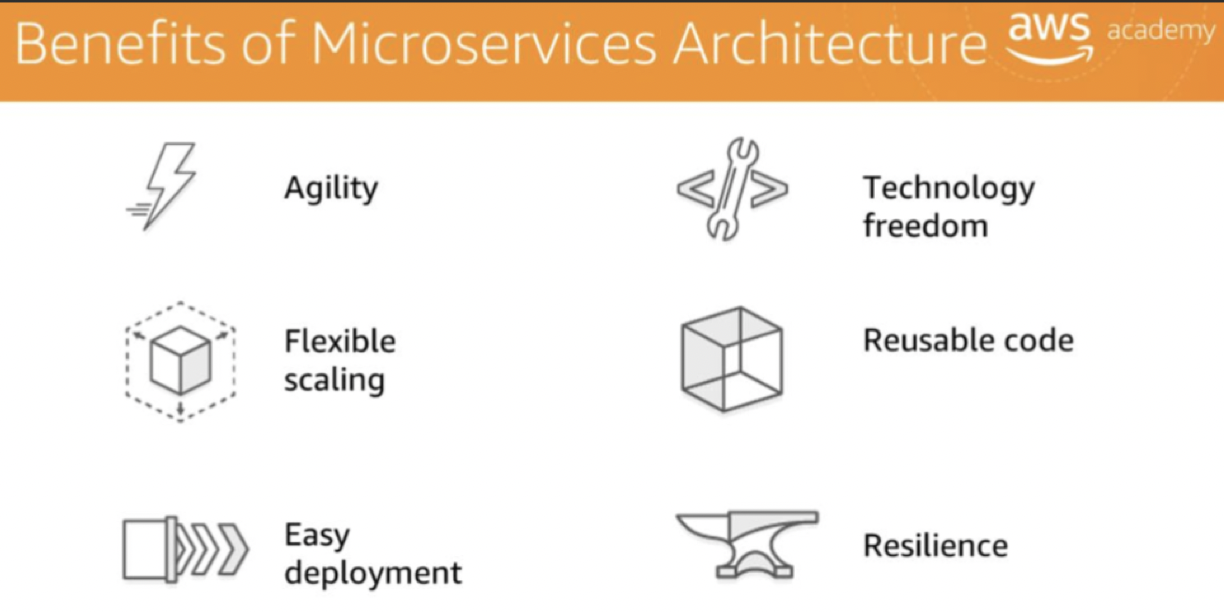
Agility
foster an organization of small, independent teams that take ownership of their services.
Teams act within a small and well understood context, empowered to work more independently and more quickly.This shortens development cycle times.
benefit significantly from the aggregate throughput of the organization.
Flexible scaling
Microservices allow each service to be
independently scaledto meet demand for the application feature it supports.enables teams to right-size infrastructure needs, accurately measure the cost of a feature, and maintain availability if a service experiences a spike in demand.
Easy deployment
Microservices
enable continuous integration and delivery, easy to try new ideas and roll back if doesn’t work.low cost of failure enables experimentation, easier to update code, and accelerates time-to-market for new features.
Technological freedom
Microservices architectures don’t follow a “one size fits all” approach.
Teams have the
freedom to choose the best toolto solve their specific problems.teams building microservices can choose the best tool for each job.
Reusable code
Dividing software into small, well-defined modules enables teams to use functions for multiple purposes.
A service written for a certain function can be used as a building block for another feature.
allows an application to bootstrap off itself, as developers can create new capabilities without writing code from scratch.
Resilience 弹回
Service independence
increases an application’s resistance to failureIn a monolithic architecture, if a single component fails, it can cause the entire application to fail.
With microservices, applications handle total service failure by degrading functionality and not crashing the entire application.
In order to replicate the business domain, integrate the services that have built
- iterate faster but not
break functionality in the process.- The interface is crucial. You need to be considerate of other teams that depend on the product.
- make the
API as simple as possible.- easier to maintain and change later.
- Because interfacing is so important, choosing a unified solution for all this inter-service communication to occur is tempting.
- Be careful to avoid integrating with smart, controlling, complex middleware which would force tighter coupling.
treat the servers as stateless.- Servers should be seen as interchangeable members of a group.
- Focus on determining if you have enough capacity to handle the workload.
- Keep in mind that adding and removing instances with Auto Scaling is much easier with a stateless approach.

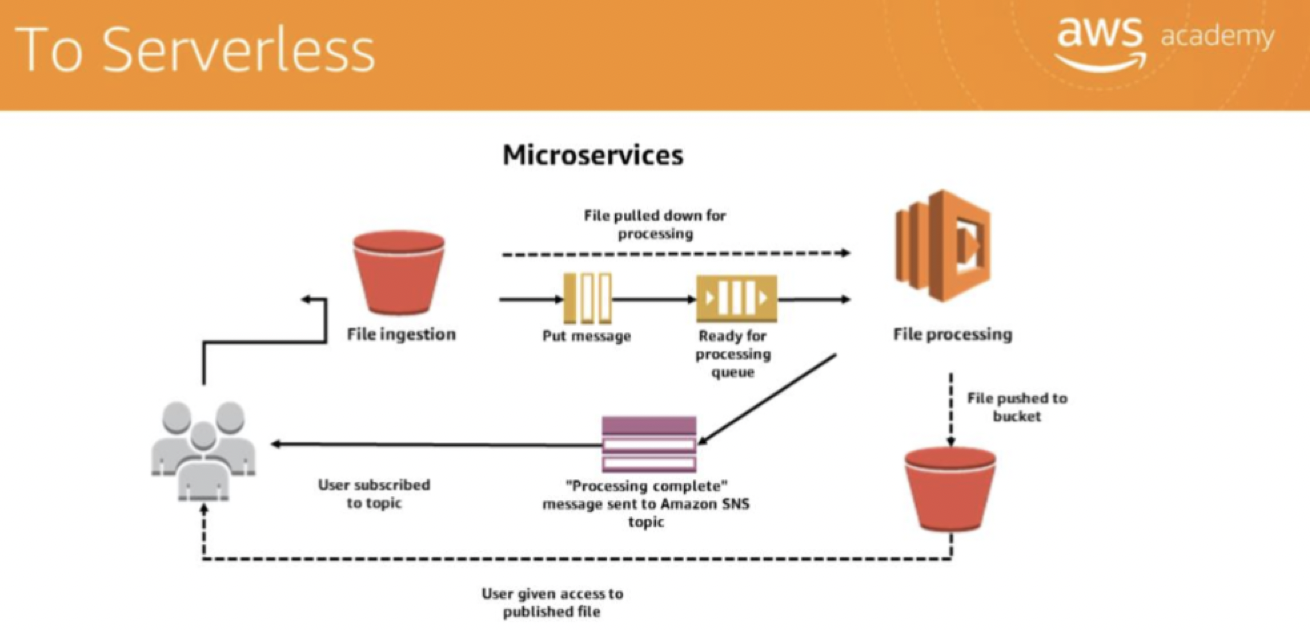
Serverless
most often refers to serverless applications.
- don’t require you to provision or manage any servers.
- responsibilities like operating system (OS) access control, OS patching, provisioning, right-sizing, scaling, and availability
- By building the application on a serverless platform, the platform manages these responsibilities for you.
- You can focus on the core product and business logic
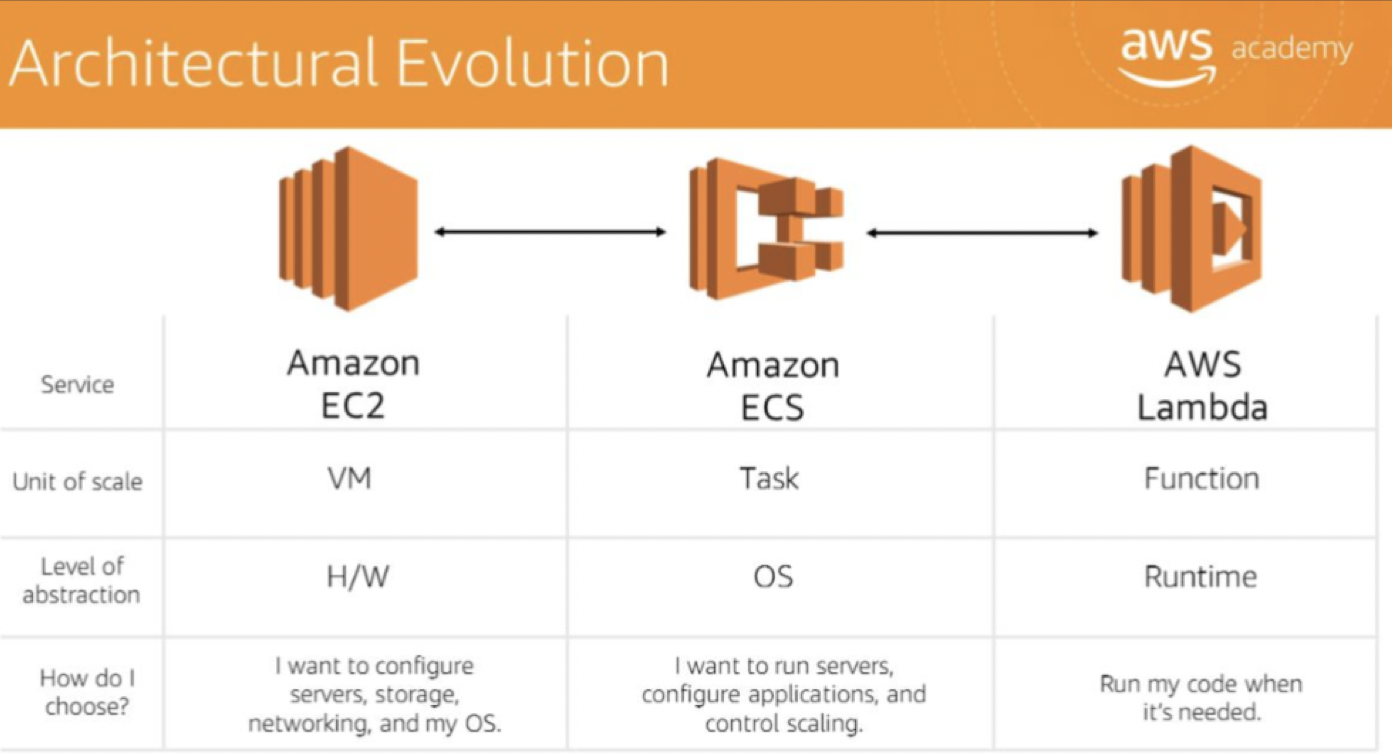
Architectural Evolution
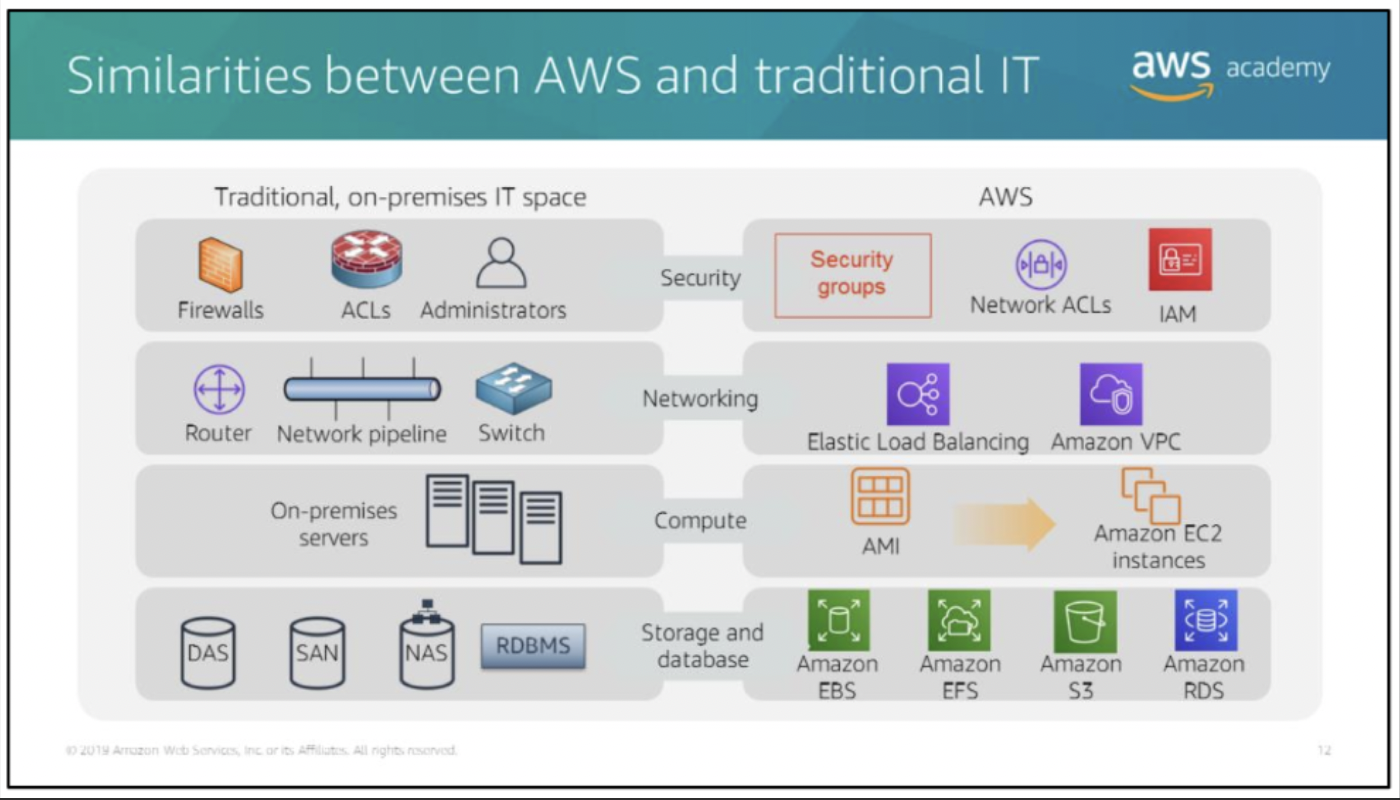
similarities between AWS and the traditional, on-premises IT space:
web service
is any piece of software that makes itself available over the internet or on private (intranet) networks.
uses a standardized format — such as Extensible Markup Language (XML) or JavaScript Object Notation (JSON)—for the request and the response of an application programming interface (API) interaction. It is not tied to any one operating system or programming language.It’s self-describing via an interface definition file and it is discoverable.
Amazon Web Services (AWS)
a secure cloud platform that offers a broad set of global cloud-based products.
Because these products are delivered over the internet, you have on-demand access to the compute, storage, network, database, and other IT resources and the tools to manage them. You can immediately provision and launch AWS resources. The resources are ready for you to use in minutes.
AWS offers flexibility. the AWS environment can be reconfigured and updated on demand, scaled up or down automatically to meet usage patterns and optimize spending, or shut down temporarily or permanently. The billing for AWS services becomes an operational expense instead of a capital expense.
AWS services are designed to work together to support virtually any type of application or workload. Think of these services like building blocks, which you can assemble quickly to build sophisticated, scalable solutions, and then adjust them as the needs change.
the main Amazon Web Services AWS service categories and core services

Which service depend on business goals and technology requirements.
Amazon EC2: complete control over the AWS computing resources.
AWS Lambda: to run the code and not manage or provision servers.
AWS Elastic Beanstalk: a service that deploys, manages, and scales the web applications for you.
Amazon Lightsail: a lightweight cloud platform for a simple web application.
AWS Batch: need to run hundreds of thousands of batch workloads.
AWS Outposts: to run AWS infrastructure in the on-premises data center.
Amazon Elastic Container Service(Amazon ECS), Amazon Elastic Kubernetes Service(Amazon EKS), or AWS Fargate: to implement a containers or microservices architecture.
VMware Cloud on AWS: You have an on-premises server virtualization platform that you want to migrate to AWS.
For example
a database application
customers might be sending data to Amazon Elastic Compute Cloud (Amazon EC2) instances, a service in the compute category.
These EC2 servers batch the data in one-minute increments and add an object per customer to Amazon Simple Storage Service (Amazon S3), the AWS storage service you’ve chosen to use.
then use a non relational database like Amazon DynamoDB to power the application, for example, to build an index so that you can find all the objects for a given customer that were collected over a certain period.
You might run these services inside an Amazon Virtual Private Cloud (Amazon VPC), which is a service in the networking category.
cloud architecture
Cloud architects:
- Engage with decision makers to identify the business goal and the capabilities that need improvement.
- Ensure alignment between technology deliverables of a solution and the business goals.
- Work with delivery teams that are implementing the solution to ensure that the technology features are appropriate. Having well-architected systems greatly increases the likelihood of business success.
WAF Well-Architected framework
AWS Well-Architected Framework
a guide, designed to help build the most secure, high-performing, resilient, and efficient infrastructure for cloud applications and workloads.
provides a set of foundational questions and best practices to evaluate and implement cloud architectures.
AWS developed the Well-Architected Framework after reviewing thousands of customer architectures on AWS.
increase awareness of architectural best practices
address foundational areas that are often neglected
evaluate architectures by using a consistent set of principles.
- does not provide:
- Strict implementation details
- Architectural patterns
- Or relevant case studies
- However, it does provide:
- Questions centered on critically understanding architectural decisions.
- Services and solutions that are relevant to each question.
- And references to relevant resources.
WAF pillars
The AWS Well-Architected Framework is organized into five pillars: operational excellence, security, reliability, performance efficiency, and cost optimization.
- Each pillar includes a set of
design principles and best practice areas. - A set of foundational questions is under each best practice area.
- context and a list of best practices areprovided for each question
the architecture of a fictitious company against the AWS Well-Architected Framework design principles for each of the pillars.
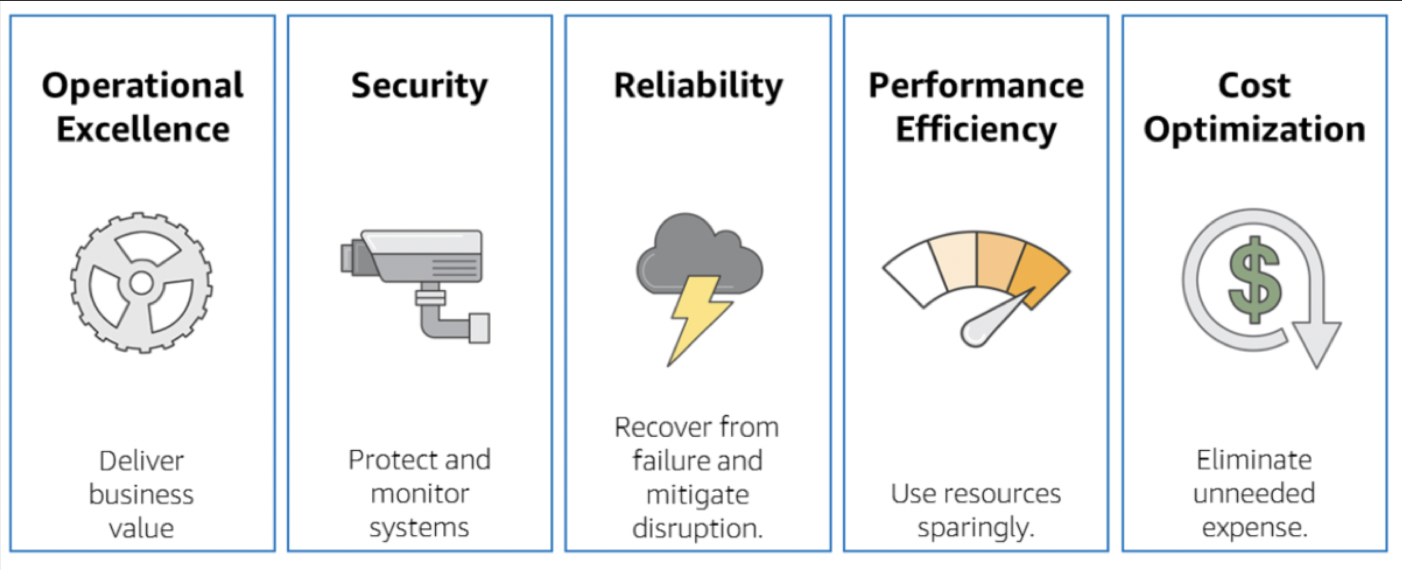
Operational excellence
- support development and run workloads effectively, gain insight into their operations
- delivers business value through
continuously improve supporting processes and procedures - Perform operations as code
- Annotate documentation
- Make frequent, small, reversible changes
- Refine operations procedures frequently
- Anticipate failure
- Learn from all operational failures
Security
the ability to protect data, systems, and assetsto take advantage of cloud technologies to improve the security.- delivers business value through
risk assessmentsandmitigation strategies. - Implement a strong identity foundation
- Enable traceability
- Apply security at all layers
- Automate security best practices
- Protect data in transit and at rest
- Keep people away from data
- Prepare for security events
- IAM, Detective Controls and Infrastructure Protection are key parts of the Security Pillar of the Well Archtiected Framework.
Reliability
- encompasses the ability of a workload to perform its intended function correctly and consistently when it’s expected to. This includes the ability to operate and test the workload through its total lifecycle. This paper provides in-depth, best practice guidance for implementing reliable workloads on AWS.
- Recover from infrastructure or service failures in the case of a catastrophic event
- Dynamically acquire computing resources to meet demand.
- And mitigate disruptions, such as
misconfigurationsandtransient network issues. - Test recovery procedures.
- Automatically recover from failure.
- Scale horizontally to increase aggregate system availability.
- Stop guessing capacity.
- Manage change in automation.
- AWS Config track the configuration state of the resources and how the state has changed over time.
- CloudTrail audit who made what API calls on what resources at what time.
- This can help with identifying changes that cause reliability issues.
Performance efficiency
- The ability to
use computing resources efficiently to meet system requirements, and tomaintain that efficiency as demand changes and technologies evolve. - Democratize advanced technologies.
- Go global in minutes.
- Use serverless architectures.
- Experiment more often.
- Mechanical sympathy.
Cost optimization
- The ability to run systems to deliver business value at the lowest price point.
- avoid or eliminate unneeded costs and suboptimal resources
- Adopt a consumption model:
- Measure overall efficiency:
- Stop spending on data center operations:
- Analyze and attribute expenditure:
- Use managed and application level services to reduce cost of ownership:
Operational excellence Pillar
The operational excellence pillar includes the ability to run, monitor, and gain insights into systems to deliver business value and to continually improve supporting processes and procedures.
Perform operations as code
Annotate documentation
Make frequent, small, reversible changes
Refine operations procedures frequently
Anticipate failure
Learn from all operational failures
Operational Excellence pillar
- the ability to run and monitor systems to deliver business value
- to continually improve supporting processes and procedures.
- Key topics include: managing and automating changes, responding to events, and defining standards to successfully manage daily operations.
- support development and run workloads effectively, gain insight into their operations
- delivers business value through
continuously improve supporting processes and procedures 6 design principles for operational excellence in the cloud:
Perform operations as code- Define entire workload (applications and infrastructure) as code and update it with code
- Implement operations procedures as code and configure them to automatically trigger in response to events.
- limit human error and enable consistent responses to events.
Annotate documentation- Automate the creation of annotated documentation after every build.
- can be used by people and systems.
- Use annotations as an input in operations code.
Make frequent, small, reversible changes- Design workloads to enable components to be updated regularly.
- Make changes in small increments that can be reversed if they fail (without affecting customers when possible).
精炼 Refine operations procedures frequently- opportunities to improve operations procedures.
- Evolve procedures appropriately as workloads evolve.
- Set up regular game days to review all procedures, validate their effectiveness, ensure teams are familiar with them.
预感 Anticipate failure, as it can happen- Perform “pre-mortem” exercises to identify potential sources of failure so that they can be removed or mitigated.
- Test failure scenarios and validate the understanding of their impact.
- Test response procedures to ensure effective and that teams are familiar with their execution.
- Set up regular game days to test workloads and team responses to simulated events.
Learn from all operational failures- Drive improvement through lessons learned from all operational events and failures. Share what is learned across teams and through the entire organization.
- 3 planes:
- The Control plane creates resources.
- The Data plane uses resources.
- And the management plane configures the service.
factors drive operational priorities
Business need:- Involving the business and development teams when you set operational priorities.
compliance requirements.- External factors might obligate the business to satisfy specific requirements.
- regulatory standards or industry standards
- Sarbanes-Oxley SOX regulatory compliance requirements versus payment card industry PCI
risk managementto balance the risk of decisions against their potential benefit.- AWS Support is the main AWS service that enables how you define operational priorities.
- It provides a combination of tools and expertise to help you define the organization’s goals on AWS.
- The following services and features are also important:
- AWS CloudFormation
- AWS Config
- Amazon CloudWatch
- Amazon Elasticsearch Service
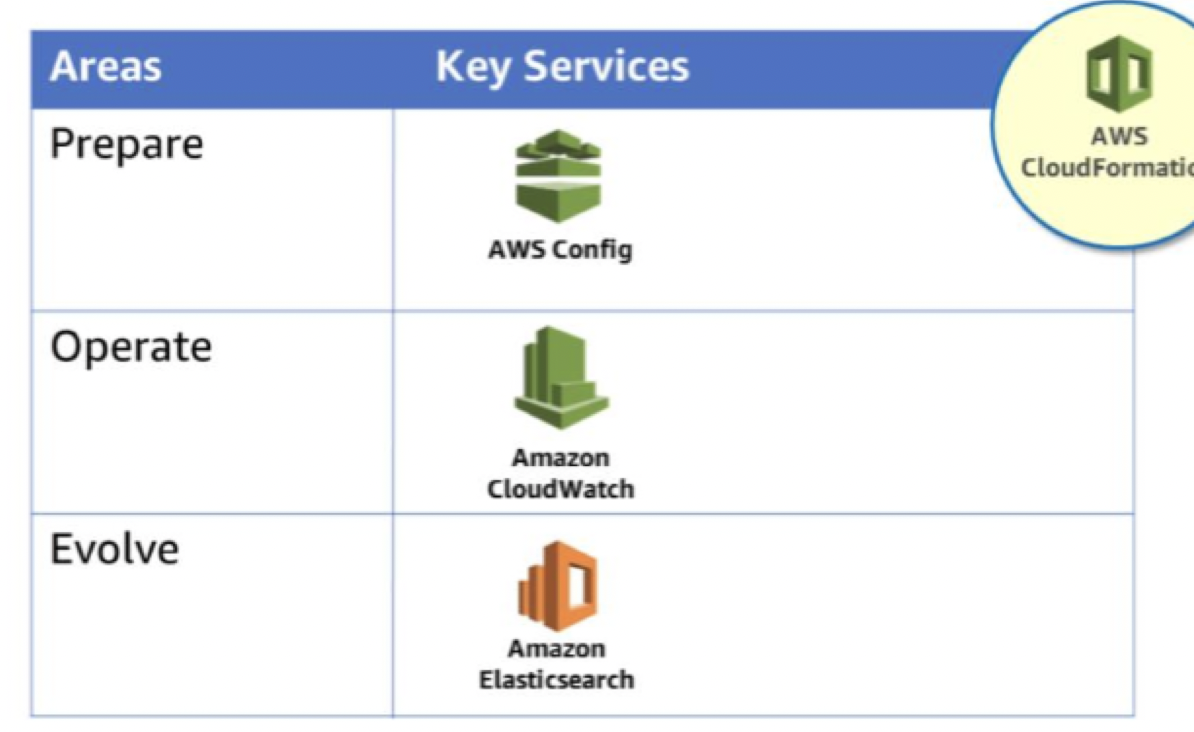
- The foundational questions for operational excellence
three best practice areas:
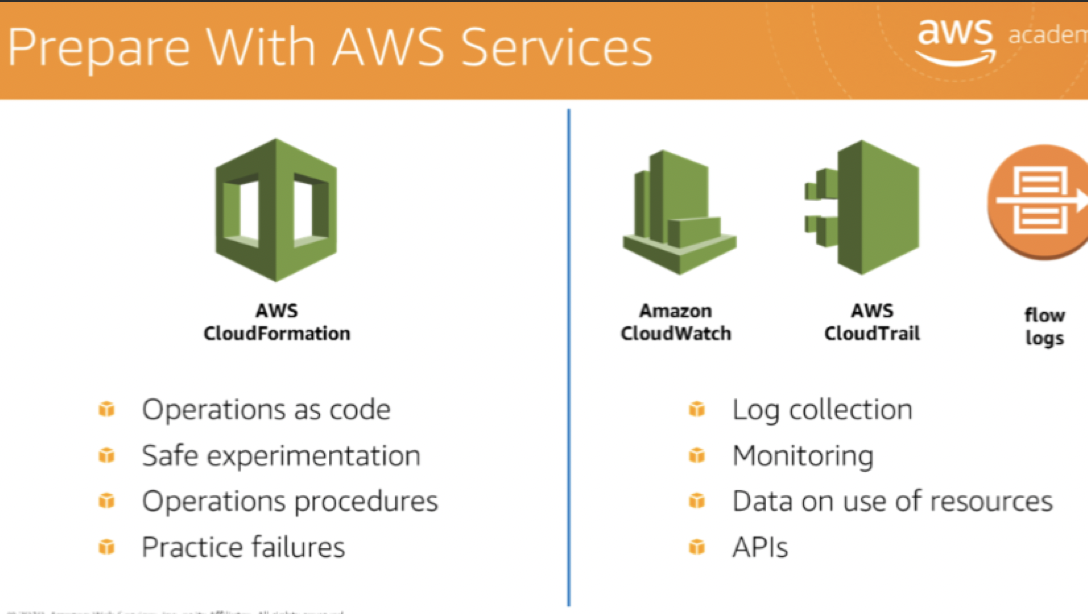
prepare, operate, and evolve.prepare
AWS Config and AWS Config Rulescan be used to create standards for workloads- to determine whether environments are compliant with those standards before they are put into production.
- monitor the application, platform, and infrastructure components.
- to understand the customer experience and customer behaviors.
- Required procedures should be adequately captured in runbooks and playbooks
- Perform cloud operations:
- Use
Checklistfor standard and required procedures- help ensure that everything that has happened on the system and that’s been tested, has been done.
- Use
Guidance. Check that required procedures are adequately captured in runbooksand playbooks.Validate trained personnelto make sure everyone is enabled.- test responses to operational events and failures
AWS CloudFormation: have consistent and templated sandbox environments for development, test, and production, with increasing levels of operations control.- use the
CloudWatch Logs agent, or the collected plugin, to aggregate information about the operating system into CloudWatch
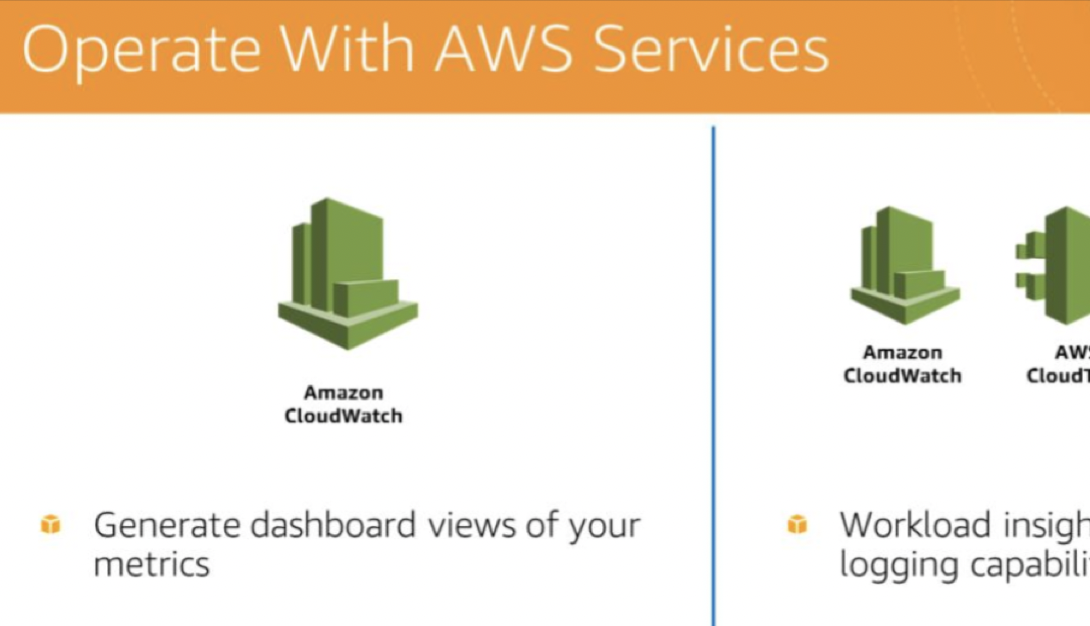
- operate
- achieve business and customer outcomes through the successful operation of a workload.
- Manage operational events with efficiency and effectiveness.
- establishing baselines to identify the improvement or degradation of operations, collecting and analyzing metrics, and then validating understanding of how define operational success and how it changes over time.
Communicate the operational status of workloads.- operational health: health of the workload, and the health and success of the operations that act upon the workload
- Use dashboards and notifications so information can be accessed automatically.
- more people have access to information about the health of the infrastructure
- determine the root cause of the outage of unplanned outage
mitigate future occurrences and unexpected effects from planned events.
- CloudWatch: monitor the operational health of a workload. generate dashboard views of metrics
- CloudWatch or third-party applications to aggregate and present business, workload, and operations-level views of operations activities.
- logging enable the identification of workload issues in support of root cause analysis and remediation
- evolve
- Dedicate work cycles to making continuous incremental improvements.
Regularly evaluate and prioritize opportunities- for improving procedures for both workloads and operations
- such as feature requests, issue remediation, and compliance requirements.
Identify areas for improvement, include feedback loopswithin procedures.Share “lessons learned”across team:- Analyze trends within the lessons learned,
- perform cross-team retrospective analysis of operations metrics
- identify opportunities and methods for improvement.
- Implement changes that are intended to bring about improvement, and evaluate the results to determine success
- With AWS developer tools, can implement
build, test, and deployment activities for continuous delivery.- can use the results of deployment activities to identify opportunities for improving both deployment and development.
- can perform analytics on the metrics data by integrating data from the operations and deployment activities, which enables you to analyze the impact of those activities against business and customer outcomes.
- This data can be used in cross-team retrospective analysis to identify opportunities and methods for improvement.
- Amazon
Elasticsearch Serviceallows to analyze the log data to gain actionable insights quickly and securely.
- Operations teams must understand business and customer needs so they can effectively and efficiently support business outcomes.
- Operations teams
create and use proceduresto respond to operational events andvalidate the effectivenessof procedures to support business needs. - Operations teams
collect metricsto measure the achievement of desired business outcomes. - As business context, business priorities, and customer needs, change over time, it’s important to
design operations that evolvein response to change and to incorporate lessons learned through their performance.
- Operations teams

Anti-patterns
Don’t commit
manual changesbecause mistakes can happen, and then these mistakes will be hard to reproduce.- don’t
focus on technology metrics alone.- the central processing unit—or CPU—and memory might be in good shape, but you might not be delivering value to the customer if you’re not paying attention to latency.
batch changes- getting changes approved and pushing them through can be cumbersome.
- Instead of making small, reversible changes, you might want to batch them.
- However, batching can make it difficult to troubleshoot if there are issues.
If a mistake is made, always take the time to understand what went wrong, to make sure it doesn’t happen again.
- Stale documentation
- Having outdated documentation or no documentation can create problems.
- Put a process in place to ensure all documentation is up-to-date.
support workload
- Continuously improving the culture.
- This best practice governs the way you operate.
- must recognize that change is constant, and need to continue to experiment and evolve by acting on opportunities to improve.
- Having a shared understanding of the value to the business.
- Make sure have cross-team consensus on the value of the workload to the business,
- have procedures that can use to engage additional teams for support.
- Ensuring appropriate number of trained personnel
- to support the needs of workload.
- Perform regular reviews of workload demands, and train existing personnel or adjust personnel capacity as needed.
- Making sure that governance and guidance are documented and accessible.:
- Ensure that standards are accessible, readily understood, and measurable for compliance.
- Make sure that you have a way to propose changes to standards, and request exceptions.
Checklists:- evaluate whether are ready to operate workloads.
- include operational readiness checklists and security checklists.
Runbooks:- for events and procedures that understand well and used in a workload.
playbook:- for failure scenarios.
Practicing recovery: identify potential failure scenarios and test the responses—for example, game days, and failure injection.
operational health
Defining expected business and customer outcomes
- Identifying success metrics.
- measure the behavior of the workload against the expectations of the business and of customers
- Identifying workload metrics.
- measure the status—and the success—of the workload and its components
- Identifying operations metrics.
- measure the execution of operations activities, such as runbooks and playbooks.
- Establishing baselines for metrics
- provide expected values as the basis for comparison.
- Collecting and analyzing metrics.
- Perform regular, proactive reviews to identify trends and determine responses.
- Validating insights.
- Review the results of the analysis and responses with cross-functional teams and business owners. Adjust the responses as appropriate.
- Taking a business-level view of the operations.
- Determine satisfying customer needs, and identify areas that need improvement to reach business goals
Determining the priority of operational events based on their impact on the business.
Putting processes in place to handle event, incident, and problem management.
- Processing each alert.
- Any event for which you raise an alert should have a well-defined response, such as a runbook or playbook.
- Defining escalation paths
- Runbooks and playbooks should have a definition for what triggers an escalation, a process for escalation, and specifically identify the owners for each action
Identifying decision makers.
Communicating operating status through dashboards.
- Pushing notifications to communicate with the users
- when the services they consume are being impacted, and when the services return to normal operating conditions, such as via email or SMS
Establishing a root cause analysis process that identifies and documents the root cause of an event.
- Communicating the root cause of an issue or event.
- Make sure understand the root causes of events and their impact, and communicate them as appropriate. Also make sure that you tailor the communications to the target audiences.

Reliability Pillar
– Test recovery procedures. – Automatically recover from failure. – Scale horizontally to increase aggregate system availability. – Stop guessing capacity. – Manage change in automation.
- Definition There are three best practice areas for reliability in the cloud:
- Foundations
- Change Management
- Failure Management
The Reliability pillar
- the ability of a system to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions such as misconfigurations or transient network issues.
- The goal: keep the impact of any type of failure to the smallest area possible.
- By preparing the system for the worst, you can implement a variety of mitigation strategies for the different components of the infrastructure and applications.
- Key topics include: set up, cross-project requirements, recovery planning, and handling change.
5 design principles that increase reliability:
- Test recovery procedures
- Test how the systems fail and validate the recovery procedures. Use automation to simulate different failures or to recreate scenarios that led to failures before. This practice can expose failure pathways that you can test and rectify before a real failure scenario.
- Automatically recover from failure
- Monitor systems for key performance indicators and configure the systems to trigger an automated recovery when a threshold is breached.
- This practice enables automatic notification and failure-tracking, and for automated recovery processes that work around or repair the failure.
- Scale horizontally to increase aggregate system availability
- Replace one large resource with multiple, smaller resources
- distribute requests across these smaller resources to reduce the impact of a single point of failure on the overall system.
- Stop guessing capacity
- Monitor demand and system usage, and automate the addition or removal of resources to maintain the optimal level for satisfying demand.
- Manage change in automation
- Use automation to make changes to infrastructure and manage changes in automation.
Definition There are three best practice areas for reliability in the cloud:
- Foundations
- AWS IAM: securely control access to AWS services and resources.
- Amazon VPC: provision a private, isolated section of the AWS Cloud to launch AWS resources in a virtual network.
- AWS Trusted Advisor: provides visibility into the limits of the AWS services that you use.
- AWS Shield: a managed service that protects against DDOS attacks, and safeguards web applications that run on AWS.
- Change Management
- AWS CloudTrail: records AWS API calls for the account, and delivers log files for auditing.
- AWS Config: provides detailed inventory of the AWS resources and configuration, continuously records configuration changes.
- Amazon CloudWatch: provides the ability to send alerts about metrics, including custom metrics.
- Auto Scaling: provides automated demand management for a deployed workload.
- Failure Management
- AWS CloudFormation: provides templates for the creation of AWS resources and provisions them in an orderly and predictable fashion.
- Amazon S3: provides a highly durable service to keep backups
- Amazon Glacier: provides highly durable archives.
- AWS Key Management Service KMS: provides a reliable key management system that integrates with many AWS services
basic disaster recovery system
for disaster recovery DR inside of AWS
recovery time objectives, RTOs: the time that business is down, during an outage
recovery point objectives, RPOs: the amount of data that will be lost.
sorted from the highest RTO and RPO to the lowest RTO and RPO.
simple backup and restore operation
- Advantages:
- Cost effective, simple to get started
- preparation phase:
- Take backups of current systems.
- Store backups in Amazon S3.
- procedures to restore from backups on AWS.
- which AMI to use, and build the own AMI as needed.
- how to restore the system from backups.
- Boot up the required infrastructure. Use AWS CloudFormationto automate the deployment of core networking
- how to switch to a new system. switch Route 53 to point to the site in AWS
- how to configure the deployment.
- RTO: times it takes to launch the infrastructure and restore system from backups.
- RPO: the time since the last backup.
pilot light architecture.
- This entire process can happen in minutes.
- Advantage
- very cost effective
- Preparation
- Take backup of current system.
- Store backups in Amazon S
- which AMI to use, and build the own as needed.
- how to restore the system from backups.
- how to switch to a new system.
- how to configure the deployment.
- In case of a disaster
- Automatically bring up the resources around the replicated core data set.
- Scale the system as needed to handle current production traffic.
- switch over to the new system, and adjust the DNS records to point to AWS.
- RTO: times it takes to detect that it need disaster recovery, and to automatically scale up a replacement system.
- RPO:l depend on how you replicate the data between the on-premises system and the AWS Cloud.
fully working low-capacity standby architecture.
- the main system and a low-capacity system runs on AWS.
- use Route 53 to distribute requests between the main system and the cloud system.
- Advantages:
- can take some production traffic at any time,
- cost savings than a full disaster recovery
- Preparation:
- similar to the pilot light scenario
- All necessary components and instances are running 24/7, but it’s not scaled for production traffic.
- best practice
- continuous testing. “trickle” test method
- have a statistical subset of production traffic go to the disaster recovery site.
- This method can alert you to any issues in infrastructure before rely on the disaster recovery site to handle all production traffic.
- In case of a disaster, you can:
- Immediately fail over the most critical production load.
- Adjust the DNS records to point to AWS.
- And Auto Scale the system further to handle all production load traffic.
- RTO: can take the critical load immediately for as long as it takes to fail over. For all other loads, it will be as long as it takes to scale further
- RPO: depends on the replication type.
multi-site active-active architecture
- have a full-size, production-capable infrastructure within the AWS Cloud.
- all of the servers are already operating at full capacity and can take the load at any time. You also perform data mirroring and replication between two sites.
- Advantage
- can take on all of the production load at any time
- preparation
- similar to that of a low capacity standby
- don’t need to scale in or out with the production load because the environment is already at full capacity
- In the case of a disaster
- can immediately fail over the entire production load.
- point DNS record to ensure that all traffic is sent to disaster recovery site within the AWS Cloud.
- RTO is as long as it takes to fail over
- RPO depends on the replication type.
best practices for being prepared
- start simple and work the way up.
- make sure backups in AWS work.
- incrementally improve the RTO and the RPO as a continuous effort
always check for any software licensing issues.
- exercise the disaster recovery solution
- Practice “game day” exercises.
- Ensure backups, snapshots, AMIs, and other recovery resources work
- monitor infrastructure for quickly implement the disaster recovery plan.
advantages of disaster recovery with AWS:
Various building blocks are available.
- have control over costs as it doesn’t require a second environment
- can spin it up quickly, test it, and then spin it back down to save costs.
quickly and effectively test the disaster recovery plan.
Multiple locations are available worldwide.
Managed desktops are available.
- Amazon WorkSpaces provides a fully managed desktop computing service in the cloud with a variety of solution providers.
User case:
The Security pillar
- the ability to protect information, systems, and assets while delivering business value through risk assessments and mitigation strategies.
- The goal of the Security pillar is to keep the impact of any type of failure to the smallest possible area.
- Key topics include:
- protecting confidentiality and integrity of data,
- identifying and managing who can do what (or privilege management),
- protecting systems,
- establishing controls to detect security events
7 design principles improve security: 5 best practice areas
- Implement a strong identity foundation:
- principle of least privilege + separation of duties + appropriate authorization for each interaction with the AWS resources.
- Centralize privilege management
- reduce or even eliminate reliance on long-term credentials.
- Identity and access management
- IAM, MFA, AWS organizations, Temporary security credential
- Enable traceability:
- Monitor, alert, and audit actions and changes to environment in real time.
- Integrate logs and metrics with systems to automatically respond and take action.
- Detective controls
- AWS CloudTrail: records application programming interface, or API, calls to AWS services.
- AWS Config: provides a detailed inventory of AWS resources and configuration,
- Amazon CloudWatch: monitoring service for AWS resources
- Apply security at all layers:
- Apply defense in depth
- apply security controls to all layers of the architecture
- for example,
- edge network, virtual private cloud, subnet, and load balancer;
- and every instance, operating system, and application
- Infrastructure protection:
- Amazon VPC: provision a private, isolated section of the AWS Cloud. You can then launch AWS resources in this virtual network.
- Amazon Inspectpr, AWS shield, AWS WAF
- Automate security best practices
- Automate security mechanisms to improve the ability to securely scale more rapidly and cost effectively.
- Create secure architectures and implement controls that are defined and managed as code in version-controlled templates.
- To reduce the possibility of human error, it is important to try to automate recovery as much as possible
- Protect data in transit and at rest:
- Classify the data into sensitivity levels and use mechanisms such as encryption, tokenization, and access control where appropriate.
- Data protection
- ELB; EBS; S3; RDS: These services provide encryption capabilities that protect the data in transit and at rest.
- Amazon Macie: auto discovers, classifies, and protects sensitive data
- AWS Key Management Service KMS: create and control keys used for encryption
- Keep people away from data
- To reduce the risk of loss or modification of sensitive data due to human error,
- Create mechanisms and tools to reduce or eliminate the need for direct access or manual processing of data.
- Prepare for security events:
- Have an incident management process that aligns with organizational requirements.
- Run incident response simulations and use tools with automation to increase the speed of detection, investigation, and recovery.
- Insident response
- IAM: to grant the appropriate authorization to incident response teams.
- AWS CloudFormation: to create a trusted environment for conducting investigations.
prevent common security exploits
distributed denial of service DDOS
- DDOS attack
- attackers use a variety of techniques that consume the network or other resources, make the website or application unavailable to legitimate end users
- DDOS attack combines the efforts of numerous systems, use multiple hosts, to simultaneously attack the website or application
- The compromised systems are typically infected with Trojans.
- Victims of a DDOS attack consist of both the end targeted system, and all systems that are maliciously used and controlled by the hacker in the distributed attack.
- Protecting against attacks is a shared responsibility
- AWS
- uses API endpoints that are hosted on a large, internet-scale, world-class infrastructure.
- Use proprietary DDOS mitigation techniques.
- AWS networks are multi-homed across a number of providers to achieve diversity of internet access.
- Customer
- Secure the applications with AWS services
- Safeguard exposed resources
- Minimize the attack surface
- Evaluate soft limits and request increases ahead of time
- Learn normal behavior
- And create a plan for attacks
-
- minimizing the attack surface area, reduces the number of necessary internet entry points
- eliminates non-critical internet entry points, separates end user traffic from the management traffic.
- obfuscates any necessary internet entry points so that untrusted end users cannot access them
- decouples internet entry points to minimize the effects of the attacks.
- scaling: horizontal scaling and vertical scaling.
- In terms of DDOS, can take advantage of scaling in AWS in three different ways
- First, select the appropriate instance types for the application.
- Next, configure services such as ELB and EC2 Auto Scaling to automatically scale the resources.
- Finally, use the inherent scale that is built into the AWS global services, like Amazon CloudFront and Route 53.
- The classic load balancer from ELB
- only supports valid TCP Transmission Control Protocol requests.
- DDOS attacks such as User Datagram Protocol UDP-floods and SYN floods cannot reach the instances.
- You can set a condition to incrementally add new instances to the Auto Scaling group when network traffic is high, which is typical of DDOS attacks.
- Amazon CloudFront
- filtering capabilities, help ensure only valid TCP connections and HTTP requests are made.
- It can also drop invalid requests
- WAF web application firewall
- applies a set of rules to HTTP traffic.
- filter web requests based on data such as IP addresses, HTTP headers, HTTP body, or uniform resource identifier-or URI-strings.
- mitigating DDOS attacks by offloading illegitimate traffic.
the responsibilities of the customer as part of the shared responsibility model
Front the application with AWS services.,
Proprietary DDOS mitigation techniques are used
Performance Efficiency Pillar The performance efficiency pillar focuses on the efficient use of computing resources to meet requirements and how to maintain that efficiency as demand changes and technologies evolve. – Democratize advanced technologies. – Go global in minutes. – Use serverless architectures. – Experiment more often. – Mechanical sympathy.
The Performance Efficiency pillar
- the ability to use IT and computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes or technologies evolve.
- Key topics include:
- selecting the right resource types and sizes based on workload requirements, monitoring performance, and making informed decisions to maintain efficiency as business needs evolve.
- Review selections using benchmarking and load tests to validate the system, especially as new services and features are launched.
- monitoring to know when performance degrades, take action before it impacts customers
- And make architectural tradeoffs to maximize performance efficiency.
- For example, you might use a cache to improve performance and reduce the load on the database.
5 design principles to improve performance efficiency:
- Democratize advanced technologies
- Consume technologies as a service.
- For example, technologies such as NoSQL databases, media transcoding, and machine learning require expertise that is not evenly dispersed across the technical community. In the cloud, these technologies become services that teams can consume.
- Consuming technologies enables teams to focus on product development instead of resource provisioning and management.
- Go global in minutes
- Deploy systems in multiple AWS Regions to provide lower latency and a better customer experience at minimal cost.
- Use serverless architectures
- remove the operational burden of running and maintaining servers to carry out traditional compute activities.
- Serverless architectures can also lower transactional costs because managed services operate at cloud scale.
- Experiment more often
- With virtual and automatable resources, quickly carry out comparative testing of different types of instances, storage, or configurations.
- Have mechanical sympathy
- Use the technology approach that aligns best to what you are trying to achieve.
- For example, consider the data access patterns when you select approaches for databases or storage.
- The Selection area encompasses compute, storage, database, and network services.
- For compute, Auto Scaling is key to ensuring you have enough instances to meet demand and maintain responsiveness.
- For storage,
- Amazon EBS provides a wide range of storage options—such as solid state drives, or SSDs—and provisioned input-output operations per second, which allows you to optimize for the use case.
- Amazon S3 provides serverless content delivery, and Amazon S3 transfer acceleration enables fast, easy, and secure transfers of files over long distances.
- For databases,
- Amazon RDS provides a wide range of database features—such as provisioned IOPS and read replicas—that allow you to optimize for the use case.
- Amazon DynamoDB provides single-digit millisecond latency at any scale.
- For network,
- Amazon Route 53 provides latency-based routing.
- Amazon VPC endpoints and AWS Direct Connect can reduce network distance and jitter.
- For the Review area,
- the AWS Blog and the What’s New section on the AWS website are resources for learning about newly launched features and services.
- For Monitoring services,
- Amazon CloudWatch provides metrics, alarms, and notifications can integrate with the existing monitoring solution.
- You can also use CloudWatch with AWS Lambda to trigger actions.
- For tradeoffs,
- Amazon ElastiCache, Amazon CloudFront, and AWS Snowball are services that allow you to improve performance.
- In addition, read replicas in Amazon RDS can help you scale read-heavy workloads.
User case:
The Cost Optimization pillar
- the ability to run systems to deliver business value at the lowest price point.
- Key topics include:
- understanding and controlling when money is being spent,
- selecting the most appropriate and right number of resource types,
- analyzing spending over time,
- scaling to meeting business needs without overspending.
- continual process of refinement and improvement of a system over its entire lifecycle.
- From the initial design of the very first proof of concept to the ongoing operation of production workloads, adopting the practices in this paper will enable you to build and operate cost-aware systems that achieve business outcomes and minimize costs, thus allowing the business to maximize its return on investment.
5 design principles that can optimize costs:
- Adopt a consumption model
- Pay only for the computing resources that you require.
- Increase or decrease usage depending on business requirements, not by using elaborate forecasting.
- Stop unused service.
- Measure overall efficiency
- Measure the business output of the workload and the costs that are associated with delivering it.
- Use this measure to know the gains that you make from increasing output and reducing costs.
- Stop spending money on data center operations
- AWS does the heavy lifting of racking, stacking, and powering servers,
- focus on customers and business projects instead of the IT infrastructure.
- Analyze and attribute expenditure 花费
- The cloud makes it easier to accurately identify system usage and costs, and attribute IT costs to individual workload owners.
- helps you measure return on investment (ROI) and gives workload owners an opportunity to optimize their resources and reduce costs.
- Use managed and application-level services to reduce cost of ownership
- reduce the operational burden of maintaining servers for tasks such as sending email or managing databases.
- managed services operate at cloud scale, cloud service providers can offer a lower cost per transaction or service.
“Everything fails, all the time.” One of the best practices that is identified in the AWS Well-Architected Framework is to plan for failure (or application or workload downtime).
- to architect the applications and workloads to withstand failure.
- 2 important factors cloud architects consider when designing architectures to withstand failure: reliability and availability.
- Reliability: a measure of the system’s ability to provide functionality when desired by the user.
- Availability: the percentage of time that a system is operating normally or correctly performing the operations expected of it (or normal operation time over total time).
A highly available system
- can withstand 承受 some measure of degradation下降 while still remaining available.
- downtime is minimized as much as possible and minimal human intervention 介入 is required.
- A highly available system can be viewed as a set of system-wide, shared resources that cooperate to guarantee essential services.
- High availability combines software with open-standard hardware to minimize downtime by quickly restoring essential services when a system, component, or application fails.
- Services are restored rapidly, often in less than 1 minute.
The key AWS feature supports cost optimization is cost allocation tags
help to understand the costs of a system.
These tags are used to tag all resources from EC2 instances to EBS volumes with cost center tags.
These tags enable you to know which cost center is incurring the most AWS charges.
This information can help you consolidate or trim down expenses. The following services and features are important in the four areas of cost optimization:
- Cost-effective resources:
- use Reserved Instances and prepaid capacity to reduce the costs.
- use Cost Explorer to see patterns in how much you spend on AWS resources over time, identify areas that need further inquiry, and see trends that you can use to understand the costs.
- Matched supply and demand:
- AWS Automatic Scaling: add or remove resources to match demand without overspending.
- Expenditure awareness:
- Amazon CloudWatch alarms and Amazon Simple Notification Service SNS notifications will warn you if you go over, or are forecasted to go over, the budgeted amount.
- Optimizing over time:
- The AWS Blog and What’s New section on the AWS website are resources for learning about newly launched features and services.
- AWS Trusted Advisor inspects the AWS environment and finds opportunities to save money by eliminating unused or idle resources, or committing to Reserved Instance capacity.
Amazon Web Services Free Tier
includes services with a free tier available for 12 months following the AWS sign-up date.
- For example,
- can use 750 hours per month of Amazon EC2,
- can use 5 GB of standard Amazon S3 storage with up to 20,000 get requests and 2,000 put requests.
Free usage of other services is also available.
AWS Free Tier Non-Expiring Offers: Some services have non-expiring offers that continue after the 12-month term.
For example, you can get up to 1,000 Amazon SWF workflow executions for free each month.
AWS Free Tier Eligible Software: The AWS Marketplace offers more than 700 free and paid software products that run on the AWS Free Tier. If you quality for the AWS Free Tier, you can use these products on an Amazon EC2 t2.micro instance for up to 750 hours per month, and pay no additional charges for the Amazon EC2 instance during the 12 months.
- Software charges might still apply for paid software, but some software applications are free.After you create the AWS account, you can use any of the products and services for free within certain usage limits through the AWS Free Tier. Select the link to learn more and create the free tier account. https://aws.amazon.com/free/
To optimize costs, consider four consistent, powerful drivers:
Right-size – right balance of instance types. servers can be either sized down or turned off, and still meet the performance requirements.
Increase elasticity – Design the deployments to reduce the amount of server capacity that is idleby implementing deployments that are elastic, such as deployments that use automatic scaling to handle peak loads.
Optimal pricing model – Recognize the available pricing options. Analyze the usage patterns to n run EC2 instances with the right mix of pricing options.
Optimize storage choices – Analyze the storage requirements of the deployments. Reduce unused storage overhead when possible, and choose less expensive storage options if they can still meet the requirements for storage performance.
optimizing cost with caching
Databases can be cached to Amazon ElastiCache Database types include NoSQL instances like MongoDB or Amazon DynamoDB, and also include relational database servers.
Example

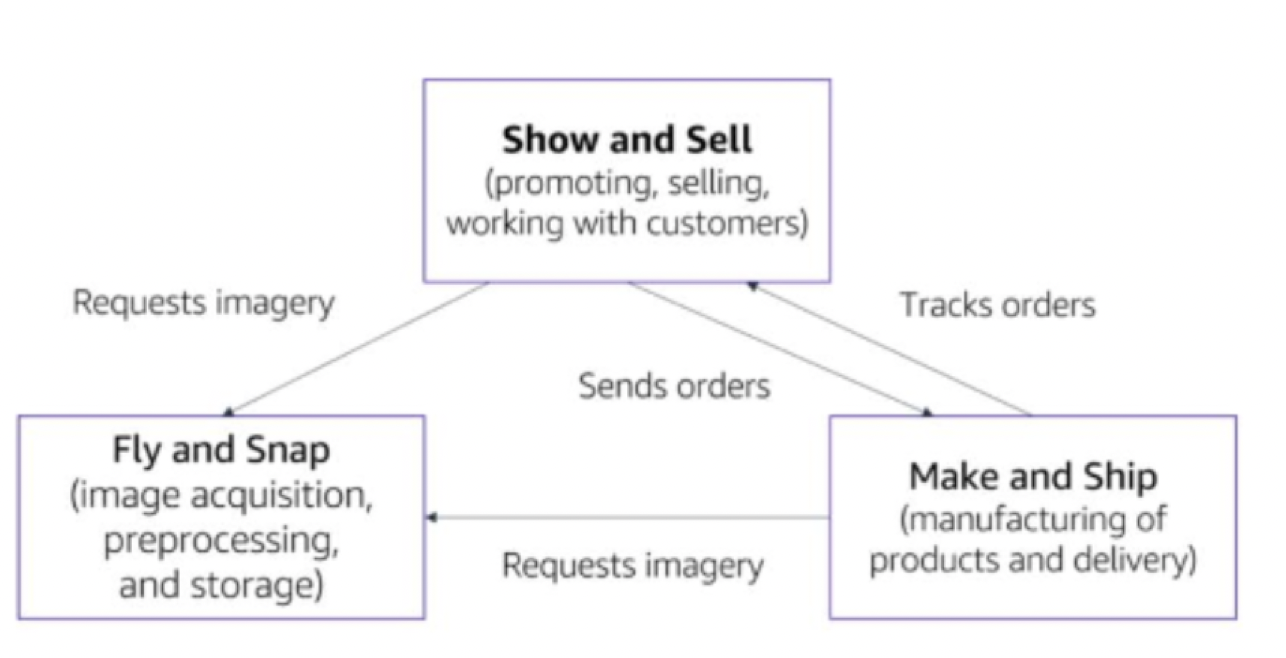
Fly and Snap
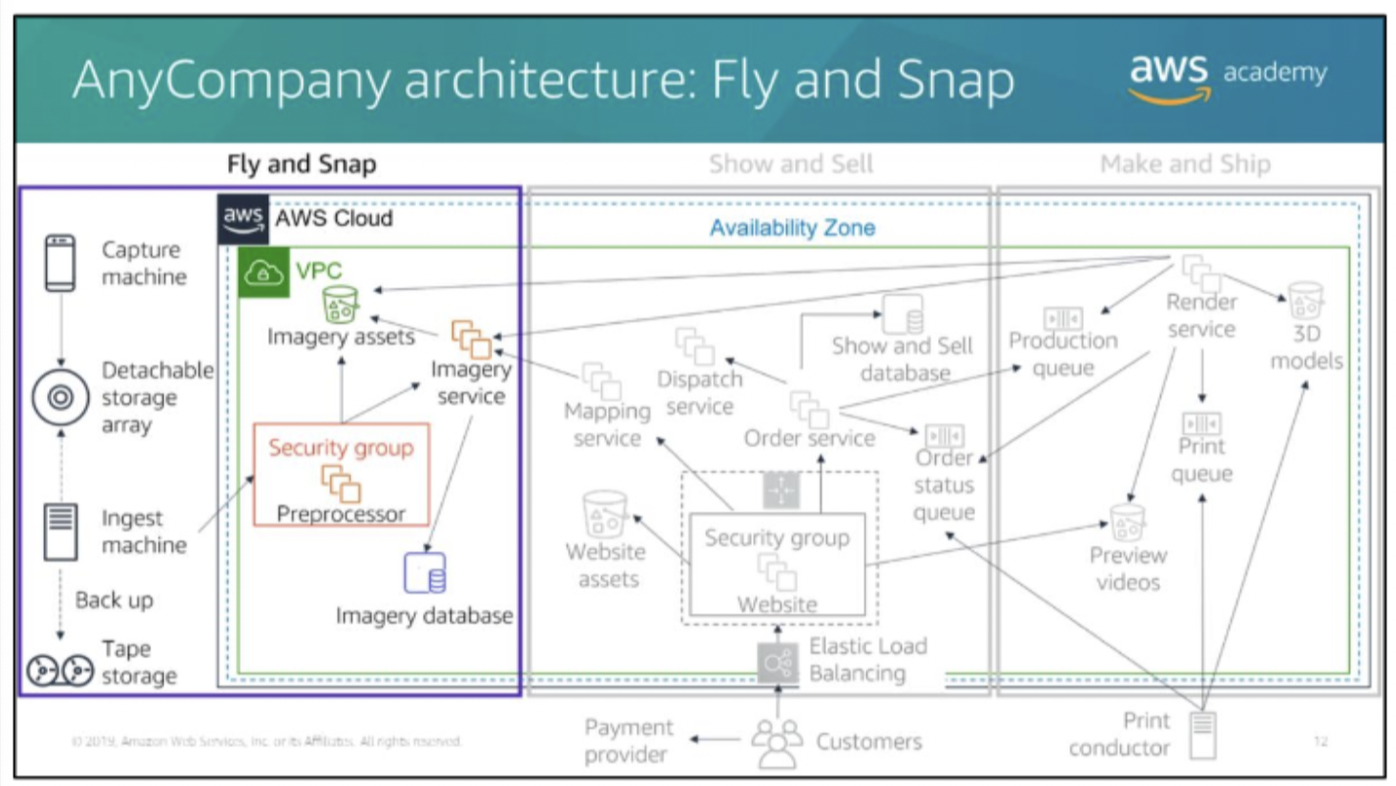
- Multiple devices (camera)
- mounted on lightweight aircraft, capture imagery of major cities on a scheduled basis.
- generates imagery assets that are time-stamped with a clock that is synchronized with the aircraft’s clock.
- The imagery assets are streamed to the onboard Capture machine that has an external storage array. The Capture machine is also connected to the aircraft’s flight system and continuously captures navigation data—suchas global positioning system (GPS) data, compass readings, and elevation.
When it returns to base, the storage array is disconnected and taken into an ingest bay. Here, the storage array is connected to an
Ingest machine.- The Ingest machine creates a compressed archive of the storage array and uses file transfer protocol (FTP) to send it to an EC2 instance Preprocessor machine.
- After the storage array has been processed, the archive is written to tape (for backup). The storage array is then cleared and ready for the next flight.
- Tapes are held offsite by a third-party backup provider.
- The Preprocessor machine
- periodically processes new datasets that have been uploaded to it.
- extracts all the imagery assets and stores in an S3 bucket.
- It notifies the Imagery service about the files and provides it with the flight information.
- The Imagery service
- uses the flight information to compute a 3D orientation and location for every moment of the flight, which it correlates to the imagery file timestamps.
- This information is stored in a relational database management system (RDBMS) that is based in Amazon EC2, with links to the imagery assets in Amazon S3.  Show and Sell
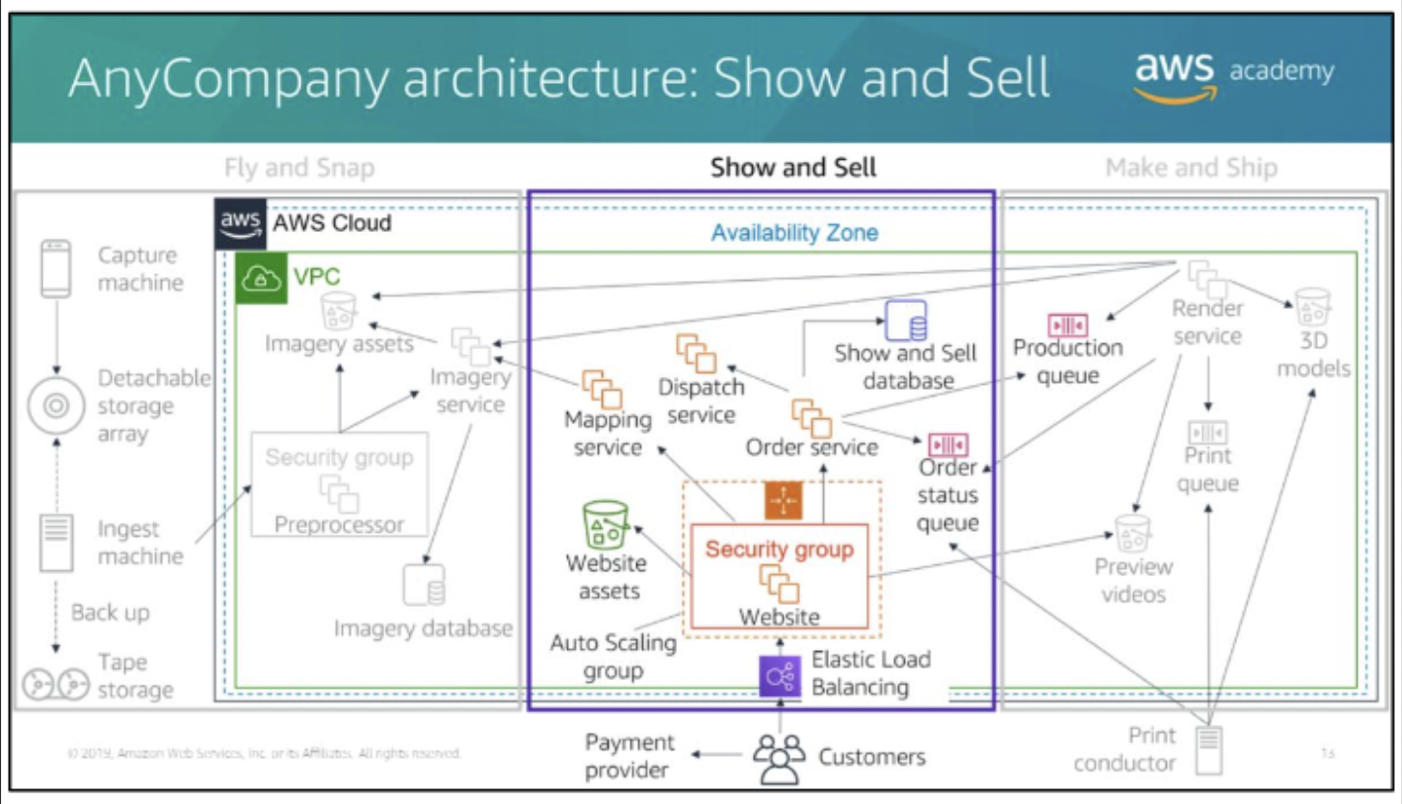
- customers visit the AnyCompany website
- see images and videos of the physical product.
- These images are in a variety of formats (for example, a large-scale, walk-around map).
- The website uses
Elastic Load Balancingwith Hypertext Transfer Protocol Secure (HTTPS), and anAuto Scaling group of EC2 instancesthat run a content management system.
- Static website assets are stored in an
S3 bucket.- Customers can select a location on a map and see a video preview of their cityscape. choose the physical size of the map, choose the color scheme (available in white, monochrome, or full color), place light-emitting diode (LED) holes in the map to build illuminated maps.
- The
Mapping servicecorrelates the map location input from the website with theImagery serviceto confirm if imagery is available for that location. - If the customers order their cityscape.
- Customers pay by credit card. Credit card orders are processed by a certified third-party payment card industry (PCI)-compliant provider.
- AnyCompany does not process or store any credit card information.
- After the website receives payment confirmation, it instructs the Order service to push the order to production.
- Orders details are recorded in the Show and Sell database, an RDBMS that is based in Amazon EC2.
- To initiate a video preview or full print of an order
- the Orders service places a message on the Production queue, which allows the Render service to indicate when a preview video is available.
- The Order service also reads from the Order status queue and records status changes in the Show and Sell database.
- Customers can track their order through manufacturing and see when it has been dispatched, which is handled by a thirdparty through the broker Dispatch service.

Make and Ship
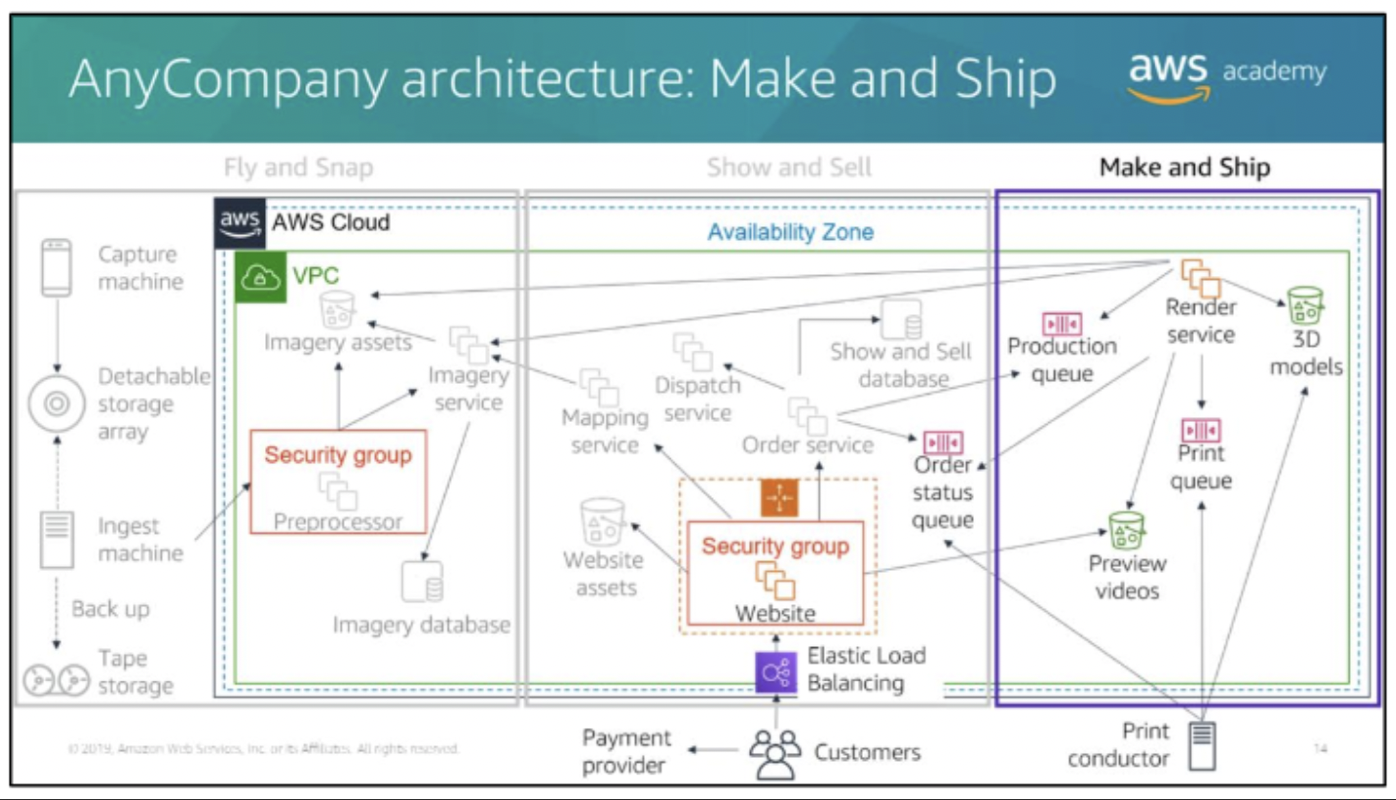
- AnyCompany has proprietary technology that enables it to generate 3D models from a combination of photographs and video (extracting structure from motion).
- The
Render serviceis- a fleet of g2.2xlarge instances.
- takes orders from the Production queue and generates the 3D models that are stored in an S3 bucket.
- also uses the 3D models to create flyby videos so that customers can preview their orders . These videos are stored in a separate S3 bucket.
- Once a year, the team deletes old previews. However, models are kept in case they are needed for future projects.
- After a customer places an order, a message is placed in the Print queue with a link to the 3D model. At each stage of the Make and Ship process, order status updates are posted to the Order status queue. This queue is consumed by the AnyCompany website, which shows the order history.
- The Make and Ship team has four 3D printers that print high-resolution and detailed color-control models. An on-premises Print conductor machine takes orders from the Print queue and sends them to the next available printer. The Print conductor sends order updates to the Order status queue. The Print conductor sends a final update when the order has been completed, passed quality assurance, and is ready for dispatch.
For each Well-Architected Framework question,
- What is the CURRENT STATE (what is AnyCompany doing now)?
- What is the FUTURE STATE (what do you think should be doing)?
Service access
All three options are built on a common REST-like API that serves as the foundation of AWS. To learn more about tools you can use to develop and manage applications on AWS,
AWS Management Console: The console provides a rich graphical interface to a majority of the features offered by AWS.
AWS Command Line Interface (AWS CLI):The AWS CLI provides a suite of utilities that can be launched from a command script in Linux, macOS, or Microsoft Windows.
Software development kits (SDKs): AWS provides packages that enable accessing AWS in a variety of popular programming languages.
the AWS Cloud Adoption Framework (AWS CAF)
AWS CAF:
help organizations design and travel an accelerated path to successful cloud adoption.
provides guidance and best practices to help organizations identify gaps in skills and processes.
helps organizations build a comprehensive approach to cloud computing—both across the organization and throughout the IT lifecycle—to accelerate successful cloud adoption.
- At the highest level, the AWS CAF organizes guidance into six areas of focus/perspectives:
- Business(business, people, governance),
- technical (platform, security, operations).
- Each perspective consists of a set of capabilities, which covers distinct responsibilities that are owned or managed by functionally related stakeholders.
Capabilities within each perspective are used to identify which areas of an organization require attention. By identifying gaps, prescriptive work streams can be created that support a successful cloud journey.
Stakeholders from the Business perspective
(business/finance managers, budget owners, and strategy stakeholders)
can use the AWS CAF to create a strong business case for cloud adoption and prioritize cloud adoption initiatives.
ensure that business strategies and goals align with its IT strategies and goals.
Stakeholders from the People perspective
(human resources, staffing, and people managers: resource/incentive/career/training/organization change management)
can use the AWS CAF to evaluate organizational structures and roles, new skill and process requirements, and identify gaps.
Performing an analysis of needs and gaps can help prioritize training, staffing, and organizational changes to build an agile organization.
Stakeholders from the Governance perspective
(the Chief Information Officer, CIO, program managers, enterprise architects, business analysts, and portfolio managers: portfolio/program and project/business performance/license management)
can use the AWS CAF to focus on the skills and processes that are needed to align 使结盟 IT strategy and goals with business strategy and goals.
This focus helps the organization maximize the business value of its IT investment and minimize the business risks.
Stakeholders from the Platform perspective
(Chief Technology Officer, CTO, IT managers, solutions architects: compute/network/storage/database provisioning, systems and solution architecture, application development)
use a variety of architectural dimensions and models to understand and communicate the nature of IT systems and their relationships.
They must be able to describe the architecture of the target state environment in detail. The AWS CAF includes principles and patterns for implementing new solutions on the cloud, and for migrating on-premises workloads to the cloud.
Stakeholders from the Security perspective
(Chief Information Security Officer, CISO, IT security managers/analysts: identity and access management, detective control, infrastructure security, data protection, incident response)
must ensure that the organization meets security objectives for visibility, audit ability, control, and agility.
can use the AWS CAF to structure the selection and implementation of security controls that meet the organization’s needs.
Stakeholders from the Operations perspective
(IT operations/support managers: service monitoring, application performance monitoring, resource inventory management, release/change management, reporting and analytics, business continuity/disaster recovery, IT service catalog)
define how day-to-day, quarter-to-quarter, and year-to-year business is conducted.
Stakeholders from the Operations perspective align with and support the operations of the business. The AWS CAF helps these stakeholders define current operating procedures.
It also helps them identify the process changes and training that are needed to implement successful cloud adoption.
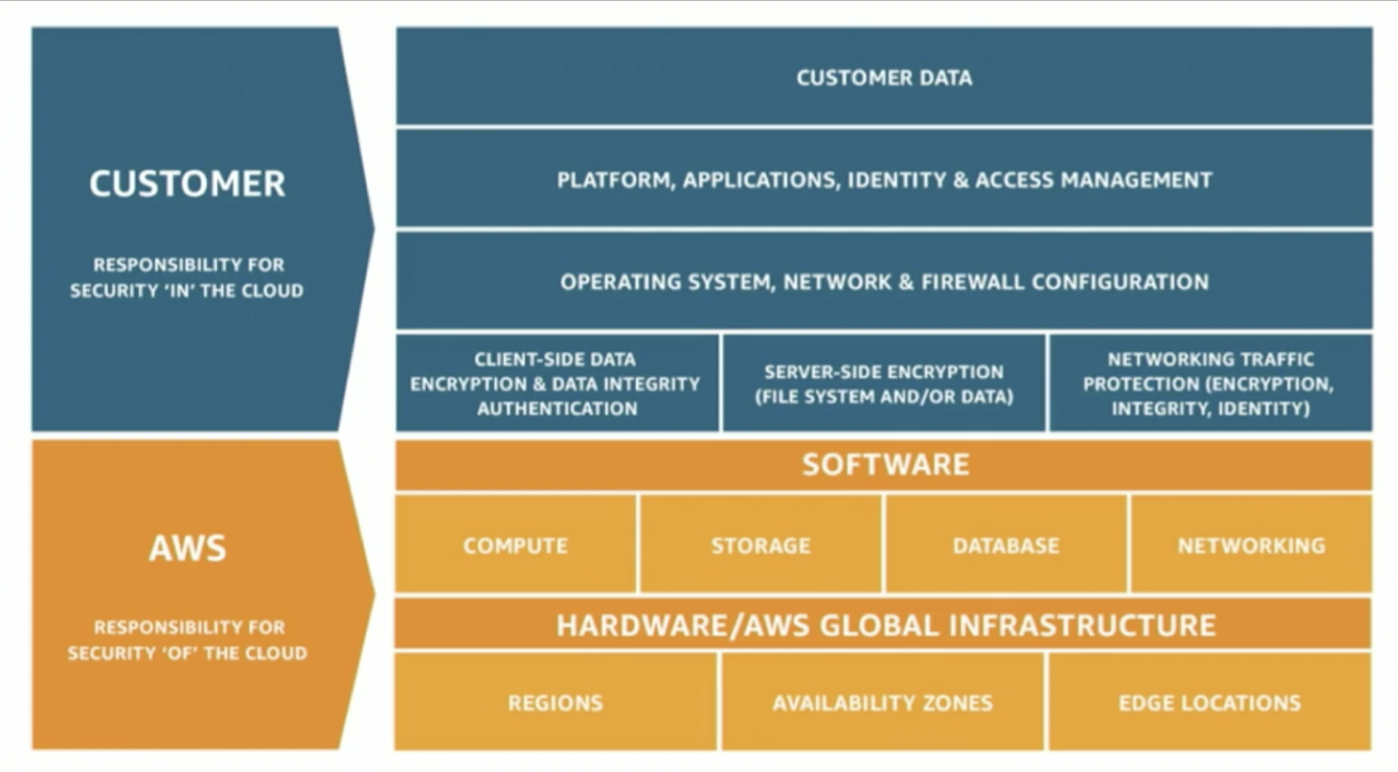
shared responsibility model


Comments powered by Disqus.